Hacker News Comments on
Simple Made Easy
Rich Hickey
·
InfoQ
·
856
HN points
·
240
HN comments
- Ranked #22 all time · view
Hacker News Stories and Comments
All the comments and stories posted to Hacker News that reference this video.> "Who Says C is Simple?"People who don't know what "simple" means and confuse it with "easy".
https://www.entropywins.wtf/blog/2017/01/02/simple-is-not-ea...
https://www.infoq.com/presentations/Simple-Made-Easy/
"Easy" things almost always lead to astonishing complexity.
Also it's easy to see just how complex C is: Have a look at a formal description of it! (And compare to a truly simple language like e.g. LISP).
https://github.com/kframework/c-semantics/tree/master/semant...
In contrast some basic Lambda calculus language semantics fit 0.5 of a page in K.
⬐ owl_vision+1 for simple is not easy, yet with enough thinking and ingenious ideas, it is achievable. Thank for the links."simplicity is the ultimate sophistication." -- Leonardo da Vinci
If I wasn't clear, I think that's fair! And certainly appreciate your blog entry. I think if anything my quibble is with our/some's obsession with "minimalism". Like, in one sense, it's less complicated to live in the woods, in another, it's tremendously difficult for some. And I'm not certain we should glorify it. It's just a different way of living.For example, OpenBSD won't adopt ZFS. Won't adopt Rust within the OS. Won't use hyperthreading. All aren't even up for debate. They have their reasons, but also I do enjoy my creature comforts. Because at a certain level of additional ease does have its benefits?
It feels like the other side of the Simple Made Easy talk by Rich Hickey[0]. Yes, we shouldn't aggravate complexity, but also we need not make things unnecessarily hard on ourselves either for the sake of "simplicity" or "minimalism". It's a balance for the rest of us. I think the goal should be to strive for both easy and simple, and an OpenBSD desktop falls short re: easy for me. And, if the point is "It's simple/minimal!", I think that simplicity should have benefits (it's more composable..., it fits on a very small flash device,...). We shouldn't simply worship simplicity for its own sake.
⬐ anthk> Won't use hyperthreading.That's a switch.
> Won't adopt Rust within the OS.
It's in packages. Get it.
> OpenBSD won't adopt ZFS
Hammer2 would be preferable.
⬐ mustache_kimono> That's a switch.That's fair. I supposed what I was getting at is: OpenBSD seems... mono-maniacal(?), and that's one reason it remains niche.
> It's in packages. Get it.
Yeah, but won't adopt inside the base OS.
> Hammer2 would be preferable.
"...from a licensing standpoint..." Otherwise, ZFS is still obviously the state of the art. Most of us shrug and say "Whatever?" re: the licensing noise and run the stuff that works?
⬐ anthkZFS has two flaws: the license and that it's too intrusive.
it's going to take quite some time to read it all since it's long and deserves the time but since it's soliciting early feedback here it is: research and quote all the works done over the last 10 or so years by others in this space!!The topic of cognitive load in software development is far from rarely considered and in fact it's been somewhat "popular" for several years depending on what communities and circles you participate it on- and off-line.
I'm surprised not to find any mentions to things like:
- the Team Topologies book by Skelton and Pais, published in 2019 where they cover the topic. Particularly of note here is the fact that Skelton has a Computer Science BSc and a Neuroscience MSc
- the many, many, many articles, posts, discussions and conference sessions on congnitive load from the same authors and connected people in subsequent years (I'd say 2021 was a particularly rich year for the topic)
- Dan North sessions, articles and posts from around 2013/2014 in which he talks about code that fits in your head but no more, referencing James Lewis original... insight. E.g. his GOTO 2014 session "Kicking the Complexity Habit" https://www.youtube.com/watch?v=XqgwHXsQA1g&t=510s a quick search returns references to it even in articles from 2020 https://martinfowler.com/articles/class-too-large.html
- Rich Hickey's famous 2011 Simple Made Easy talk https://www.infoq.com/presentations/Simple-Made-Easy/
⬐ rpeszekAbout "Cognitive load being rarely considered", I meant it in actual project work, not in the sense that the idea of applying cognitive psychology to programming is new.I am sure the topic has been considered in an academic setting. I would not feel qualified to provide a good reading list on the topic.
This is also related to code quality, thus it will have a ton of relevant work.
Thank you for the links, in particular to Skelton, Pais, I will have a look!
⬐ Lwepz>research and quote all the works done over the last 10 years or so by researchers in this space!!I totally understand your point and appreciate you linking those resources, however I think it's important to remember that the author's post is from a personal blog, not from a scientific journal or arxiv.
Perhaps OP would've never posted this if he felt that his "contribution" wasn't novel enough. Additionally, there's a chance that the wording and tone the author used might speak to people who found the articles you mentioned opaque(and vice versa, obviously).
If the author, feeling the urge to write something up, had looked very hard for "prior work" instead of following the flow of their insights gained through experience, perhaps they would've felt compelled to use the same vocabulary as the source, which has its pros(forwarding instead of reinventing knowledge) and cons(propagating opaque terms, self censoring because of a feeling of incompetence in the face of the almighty researchers).
That's one of the great things about blog posts: to be able to write freely without being blamed for incompleteness or prior art omission.
On a different note, I think this may also highlight the fact that the prior work you mentioned isn't easy enough to find. Perhaps knowledge isn't circulating well enough outside of particular circles.
Look, of course there's lots of unexplored territory in software engineering, and we absolutely should continue to strive for better programming languages and abstractions. And we are! From reading this article, this author is looking in entirely the wrong direction for such improvements. It's not going to be some magic visual model thatOne thing we should not expect is that new developments will be easy for us to learn, because we are already steeped in the current way of doing things. Supposedly, lexical scoping (what we're all familiar with) was extremely difficult to understand by early waves of programmers that were used to dynamic scoping (an insane way of doing it). They could have easily complained that this was just some new over-complicated abstraction and language construction that we don't need, but once you get over that hurdle and understand it, life actually becomes much simpler. New breakthroughs will hopefully be simple, but probably not very easy for us [1].
Many of this author's complaints about the current state of programming sound like they just haven't really achieved fluency in their programming language yet, and that they've been burned out on bad abstractions and have stopped trying to create (or just can't recognize) good ones. That's OK, this is all really hard to do! But it doesn't mean that everyone else is doing it wrong.
⬐ panstromek> It's not going to be some magic visual modelI wasn't talking about visual model at all. In fact, the word `visual` doesn't even appear in the article once.
⬐ feorenA fair point, and I can't remember what my point was going to be (perhaps I meant to delete this sentence). But on the other hand, you never talk about the alternative to plain text, and I think every alternative I've ever heard of has been "visual" in some sense. In fact I'm not sure what other options there are other than "visual" and "plain text".Perhaps what you were saying is that each developer should be able to choose whether they're working visually or in plain-text, with the underlying model being neither (binary? XML?). If you chose to work in LISP for the day, the computer would transpile the underlying model to LISP, and then transpile it back when you're done? I think this is the "magic" part, where some, what, AI does this for you? We're so far away from that being effective, and the benefits are just not there when you're truly fluent in the programming language. Every single instance I've ever seen of "Each developer can pick how it appears on their machine!" has made communication and synchronization between developers worse, not better.
Clojure libraries target microservices with a precision that no other language ecosystem has. In essence, Clojure web services developers rail against Rails and other bloated, unnecessarily complected (https://www.infoq.com/presentations/Simple-Made-Easy/) frameworks of the 90s. As a Clojurist I too rail against Rails. I don't think that expansive model fits the problem space. I have had painful experiences in the past maintaining Rails projects wondering why they didn't know of DRY. If there is a essence within Rails that you feel could be distilled into a lean Clojure model, build it out in a library and share it.
⬐ janetacarrMy central thesis seems to be getting lost here.I'm not advocating for a Clojure Rails because I love Rails. I've never used Rails to be honest. I'm arguing open-source efforts are repeatedly being spent on trying to build the next web framework/library/toolkit (Rails) for Clojure and not much else, so it would be great if there was one, so we can get on with filling the gaps in the Clojure ecosystem.
⬐ huahaiy⬐ aantix"open-source efforts are repeatedly being spent on trying to build the next web framework/library/toolkit (Rails) for Clojure and not much else", really?That's contrary to what most of us know. There are some efforts in the Web front, but not much. At least, the community is not paying much attention to these efforts.
Let's look at the list of community funded projects, e.g. those in Clojure Together: the only Web related projects funded were clj-http in 2018, ring, re-frame and reagent in 2020. None of these are Web frameworks, and the rest of the funded projects are not Web related at all.
Keeping things DRY is about the discipline of the developer.It’s nothing specific to the language or framework.
⬐ fmakunbound> Clojure libraries target microservices with a precision that ..I’m not sure what that means exactly, but no one is using Rails only for building out micro services. They’re using Rails to go from nothing to a production ready web application, with all the incidental complexity taken care of, in a very short time.
It’s been a few years since I was involved with Clojure ecosystem - what is the Clojure experience equivalent to say, the original Rails demo from back in 2005? The last I tried, all the parts seemed to be there, but much painful assembly/“composing” was required and not all the parts fitted which ended up producing a lot of awkward complexity needing desperate decomplecting.
I understand your worry, but I've had a quite opposite take on this.I think we can agree that it's not that hard to find ANY job as an experienced developer. However it's much more difficult to find a great, satisfying job. For that you need to navigate around a lot of corpo-bullshit type of projects, and Clojure has served me well as a useful filter in doing that. My reasoning is that Clojure is niche enough that when company is using it, you can assume that it's due to a deliberate technical choice, and not just because of its popularity. That tells me two things that are symptomatic, in my opinion, of a healthy tech company culture: - tech decisions are made by engineers, not by top-level executives, - their conclusions and bets align with mine because we all see and agree on Clojure's edge over more popular solutions.
Admittedly, there's always a risk that someone just followed the hype and got out of their depth but I think this risk is relatively small, because Clojure's no longer a new kid on a block and choosing a tech stack is a major decision and usually done by senior tech leadership, hopefully less hype driven.
Of course, Clojure is no silver bullet and it's just a tool that gives you enough rope to hang yourself. Messy codebases are just as possible as in other languages, especially when the team is new to lisps that are very different from mainstream languages, but that's a nature of software development - you learn with the experience. I do cringe when I look at the Clojure code I wrote when I was just starting and wasn't fully grasping Clojure's way of thinking, but the more I use it, the more I come to appreciate how powerful it is.
Great intro that made it click for me: https://www.youtube.com/watch?v=vK1DazRK_a0 (Solving Problems the Clojure Way - Rafal Dittwald, 2019)
Having said that, no software project is ever complete and so isn't Clojure as an ecosystem. The tooling is constantly evolving and new patterns are emerging. What's great about Clojure open-source community is that everyone seems to share the desire to harness complexity and Rich Hickey has convinced each one of us at some point that the way to do it is through simplicity https://www.infoq.com/presentations/Simple-Made-Easy/
Even within Clojure's community there's a diversity of approaches, and I think it's necessary to improve and evolve. The more recent trend, I've noticed is that the community is converging at Data Oriented Programming that's applicable in other languages as well, but has always been at the core of Clojure's mindset that is especially well suited for it.
Dropping some links relevant about DOP: https://youtu.be/8Kc55qOgGps?t=4175 (Rafal Dittwald, “Data Oriented Programming” 2022) - whole talk is valuable, but long so I'm linking to the most juicy snippets) https://blog.klipse.tech/dop/2022/06/22/principles-of-dop.ht...
Moreover, Clojure has already grown past the threshold of being just a niche toy and has sufficiently big market that it won't die off anytime soon. When you study history of programming languages, you'll notice that it's enormously difficult thing to do for an emerging player, especially without big corporate backing. And Clojure is as grassroot as it gets: https://clojure.org/about/history
It's been hinted at in this subthread a few times, but Rich Hickey's keynote https://www.infoq.com/presentations/Simple-Made-Easy/ about simple and easy is worth a listen/watch.
In case you have not seen it, there is an excellent talk by Rich Hickey on what "simple" is and how it differs from "familiar" or "easy": https://www.infoq.com/presentations/Simple-Made-Easy He proposes that "simple" is more objective than subjective.
Like everything else there’s a tendency to lean towards categorizing it into one binary category or another, I think this article makes some great points however about the topic of simplicity I think rich hickeys talk about “simple made easy” is really informative for thinking about design and building systems (it also presents a interesting definition of the two categories)
This is the kind of question that Rich Hickey (inventor of Clojure) dealt with here: https://www.infoq.com/presentations/Simple-Made-Easy/
> As a general rule, if you're referencing the dictionary definition of a word to make your point, you're just playing semantic games.Before dismissing this as silly semantic games, you should watch the talk which they were very likely referencing: https://www.infoq.com/presentations/Simple-Made-Easy/
It definitely can be. I'm constantly trying to push our stack away from anti-patterns and towards patterns that work well, are robust, and reduce cognitive load.It starts by watching Simple Made Easy by Rich Hickey. And then making every member of your team watch it. Seriously, it is the most important talk in software engineering.
https://www.infoq.com/presentations/Simple-Made-Easy/
Exhausting patterns:
- Mutable shared state
- distributed state
- distributed, mutable, shared state ;)
- opaque state
- nebulosity, soft boundaries
- dynamicism
- deep inheritance, big objects, wide interfaces
- objects/functions which mix IO/state with complex logic
- code than needs creds/secrets/config/state/AWS just to run tests
- CI/CD deploy systems that don't actually tell you if they successfully deployed or not. I've had AWS task deploys that time out but actually worked, and ones that seemingly take, but destabilize the system.
---
Things that help me stay sane(r):
- pure functions
- declarative APIs/datatypes
- "hexagonal architecture" - stateful shell, functional core
- type systems, linting, autoformatting, autocomplete, a good IDE
- code does primarily either IO, state management, or logic, but minimal of the other ops
- push for unit tests over integration/system tests wherever possible
- dependency injection
- ability to run as much of the stack locally (in docker-compose) as possible
- infrastructure-as-code (terraform as much as possible)
- observability, telemetry, tracing, metrics, structured logs
- immutable event streams and reducers (vs mutable tables)
- make sure your team takes time periodically to refactor, design deliberately, and pay down tech debt.
⬐ islandertI agree with most of you points, but the one that stands out is "push for unit tests over integration/system tests wherever possible".By integration/system tests, do you mean tests that you cannot run locally?
⬐ LoveGracePeaceMost of that I agree with, I'm curious why you'd recommend unit tests over integration tests? It seems at odds with the direction of overall software engineering best practices.⬐ solididiotOnly read the transcript but I'm not getting most of it. I mean it starts with a bunch of aphorisms we all agree with but when it should be getting more concrete it goes on with statements that are kind of vague.E.g. what exactly does it mean to: >> Don’t use an object to handle information. That’s not what objects were meant for. We need to create generic constructs that manipulate information. You build them once and reuse them. Objects raise complexity in that area.
What kind of generic constructs?
There's a really wonderful talk that I've recommended to almost everyone I've ever worked with called Simple Made Easy[1] by Rich Hickey. I also struggled to explain why I hated state so much. You can talk about races with shared mutable state but even single threaded code I found I couldn't stand it, that it made things harder to reason about and change. It's because state is complex, in the sense Rich discusses in the talk: State intertwines "value" and "time", so that to reason about the value of a piece of state you have to reason about time (like the interleaving of operations that could mutate the state).I don't know if it's just me but I watched that talk a couple years into my career and it was like something clicked into place in my brain. It changed the way I think about software.
⬐ usrusrThat time part is what you are wrestling with when you are battling with state. So it's natural to think about it that way. But there's also this somewhat dumbed down version of the argument: every piece of state a method reads is like an additional function argument and every state it writes an additional return value. What a mess.⬐ mujina93⬐ qazpotThis made me think: if we wrote object oriented code methods where all the members that we access are passed explicitly as parameters, as well as all the members that we modify (as out references), then we at least would immediately identify the real complexity of some methods! I'll try to do this, I'm curious to see how that would look like.⬐ andi999⬐ cventusAt some point you get too many parameters, so you pass a struct, which basically means that struct turned into an object. (one interesting difference is that you can pass more than one different struct to that function which is the equivalent of subclassing; but with more permutations possible. Thats actually interesting).⬐ raducu> I'll try to do this, I'm curious to see how that would look like.That looks like a terrible mess.
The problem is not state, but messy access to it.
⬐ usrusrEverybody agrees that OOP was killed by getters and setters. But I don't think that there is much consensus about how long it would have survived without.(I'm not saying that OOP doesn't have its place, but it has clearly turned from a way of structuring code to universally strive for into something to avoid if possible)
That's not a bad way of putting it. It reminds me of "It is the user who should parameterize procedures, not their creators."⬐ branko_dThis is insightful.In some sense, the only distinction a "pure" function has over "non-pure" is that it declares all its inputs/outputs (as function parameters and result). We say that a non-pure function has "side effects", but all that actually means is that we don't readily see all its inputs/outputs.
Even a function that depends on time could be converted to a pure function which accepts a time parameter - this is conceptually the same as a function which accepts a file, or an HTTP request or anything else from the "outside world".
The trouble, of course, comes from the tendency of the outside world to change outside of our program's control. What do we do when time changes (which is all the time!) or file, or when the HTTP request comes and goes never to be seen again?
Or when the user clicks on something in the UI? Can we politely ask the outside world for the history of all past clicks and then "replay" the UI from scratch? Of course not. We cache the result of all these clicks (and file reads and network communications and database queries...) and call it "state". When the new click comes, we calculate new state based on the previous state and the characteristics of the click itself (e.g. which button was clicked on). This is a form of caching and keeping a cache consistent is hard, no matter what paradigm we choose to implement on top of it.
The real-world example of this would be React. It helps us implement the `UI = f(state)` paradigm beautifully, but doesn't do all that much for the `state` part of that equation which is where the real complexity lies.
⬐ veidelisThere's no such thing as UI = f(state) in React. You may know that already, but it's UI = f(allStatesStartingFromInitialState). That way all state transitions are captured and all state changes are handled accordingly inside components taking into account component's internal state.> State intertwines "value" and "time", so that to reason about the value of a piece of state you have to reason about time (like the interleaving of operations that could mutate the state)Chapter 3 of SICP deals with this topic in great detail.
⬐ wainstead⬐ troupeSICP being https://mitpress.mit.edu/sites/default/files/sicp/full-text/...I think I was at that talk. If I remember right the Sussmans were there as well and Gerry was the first to his feet giving Rich a standing ovation after that talk.⬐ allenuThis is one of my favorite talks. It also helped things click for me regarding state. I try to use immutability wherever I can now and when there are unavoidable state changes, I try to understand and constrain the factors that could lead to such a state change. It's simplified things so much for me.⬐ dwohnitmokI enjoyed the talk and agree with it in many ways, but perhaps a contrarian stance will stimulate some interesting discussion. Here's the steelman I can think of against that talk.Hickey's fundamental contention is that whether something is easy is an extrinsic property whereas whether something is simple is an intrinsic property. Whether something is easy is dictated often by whether it is familiar, whereas simplicity lends us the more ultimately useful property of being understandable.
To which I'll counter with Von Neumann's famous quote about mathematics : "You don't understand things [simple]. You just get used to them [easy]."
There is no fundamental difference between ease and simplicity. Simplicity (of finite systems) is ultimately a function of familiarity. There's a formal version of this argument (which is effectively that most properties of Kolgomorov complexity when applied to finite strings are defined by your choice of complexity function, even in the presence of an asymptotically optimal universal language. In particular there is not a unique asymptotically optimal universal language, that is the Invariance Theorem is overhyped), but the informal version is that both simplicity and easiness arise from familiarity.
Indeed the fact that there is "ramp-up" speed for simplicity suggests that in fact what is going on is familiarity. E.g. splitting state into "value" and "time" is one way of thinking about it. But I could easily claim that in fact "time" complects "cause" and "state." Rather state machines where the essential primitives are "cause" and "effect" are the proper foundations from which "value" and "time" then flow (you can think of "effect" nondeterministically, a la infinite universes, and then "value" and "time" fall out as a way of identifying a single path among a set of infinite universes). Likewise Hickey claims that syntax mixes together "meaning" and "order" whereas I would could just as easily say that "order" complects syntax and semantics!
What of the idea of "being bogged down?" That "simple" systems allow you to continue composing and building whereas merely "easy" systems collapse and are impossible to make progress on past a certain threshold? I claim that these are not intrinsic properties of a system. They are rather extrinsic properties that demonstrate that the system no longer aligns well with the mental organization of a human programmer. However this is dependent on the human! A different human might have no problem scaling it.
Now hold on, perhaps, while simplicity is perhaps dependent on the human mind and humans all more or less have the same mental faculties. Perhaps we can't find a truly intrinsic property that we call simplicity, but perhaps there's one that's "intrinsic enough" and relies only on the mental faculties common to all humans. That is, returning to the idea of "being bogged down," there are systems whose complexity puts them beyond the reach of all, or at least most, humans. We can then use that as our differentiator between "simple" and "easy."
To which I would reply that this is probably true in broad strokes. There are probably systems which are are so arcane as to be un-understandable by any human even after a lifetime of study. But at a more specific level, the way humans think is very varied. The ways we learn, the ways we develop are hugely different from person to person. Hence I find this criteria of "bogging down" far too weak to support Hickey's more concrete theses, e.g. that queues are simpler than loops or folds.
When you're talking about things like love, hate, and fear, sure maybe those are universal enough among humans to be called "objective" or to have associated "intrinsic properties," but when you're talking about whether a programming language should have a built-in switch statement, I don't buy it.
For the purposes of programming languages, simple is not made easy. Simple is easy. Easy is simple. The search for the Platonic ideal of software, one that relies on a notion of intrinsic simplicity, is a false god. Code is an artifact made for consumption by humans and execution by machines and therefore any measure of its quality must be extrinsic to the humans that consume it.
Sometimes X is simple. Sometimes it's not. It all depends on the person.
As empirical evidence of this I leave this final exchange between Alan Kay and Rich Hickey where the two keep talking past each other, no matter how simple their own system is: https://news.ycombinator.com/item?id=11945722
⬐ kaba0⬐ grumpyprole> To which I'll counter with Von Neumann's famous quote about mathematicsI’m fairly sure this great quote is about mathematical “objects” in that you will never be able to truly “understand” or have a “real feeling” for more complex ones, like higher dimensions. Yet, by applying some simpler rules we can use and transform them, and after a bit of practice that will make it feel “close to us”, or “real”.
> Simplicity (of finite systems) is ultimately a function of familiarity.
I really don’t believe it would be true. Maybe I’m misunderstanding, but no matter how familiar I am with a given crud program vs JIT compiler technology, the latter will always be complex - but as you later refer to, I’m sure you know the difference between essential and accidental complexity. But in this view I would rather say that simple things are ones with minimal accidental complexity, while the easy-hard axis is about the essential part of that, that is irreducible.
⬐ raspasov>>> the way humans think is very varied>>> It all depends on the person.
Based on what I've recently learned about neuroscience and optogenetics, I don't think there's much evidence to support this sort of relativism. On the contrary, many processes in mammalian brains have common mechanisms.
To explore more, this is a great podcast https://peterattiamd.com/karldeisseroth/
Disclaimer: I am a complete layman on the topic, so please correct me if I'm wrong.
⬐ Peritract⬐ qsdf38100There is more to how we think than the underlying mechanisms, just as varying programs can be run on the same hardware.This concept of "used to" vs "understand" reminds me of an interview with Feynman where IIRC he explains how can magnetism work at a distance to a layman person. He discusses about the "why" questions and how you keep getting deeper and deeper each time you ask "why". He concludes that his explanations won’t be satisfying for the other person, saying "I can’t explain this to you in terms you are more familiar with". I thought it was interesting and related. I’ll try to find that video.⬐ jodrellblank⬐ wnkrshmIt's the Feynamn "Fun to Imagine" video / series.This bit is wher ehe says that about magnets: https://youtu.be/P1ww1IXRfTA?t=1300
I want to add to this that physics aims at this 'simplicity', i.e. being able to derive mathematical models ab initio, with the least amount of assumptions.While the 'simplest' (in the physics sense) description of something is elegant, it can also be extremely hard to understand and work with. Maxwell's equations are used in engineering for a reason - and not their simpler theoretical physics underpinnings.
⬐ taurathI appreciate the thought process here, and I'd want to spend more time thinking it over before a full response - though I think it maybe goes a little bit too into etymology for my taste! My immediate comment is that working memory is a measurable finite resource that developers have to use. The more entities they have to track in order to model the part of the system they're working on, the more usage of working memory.Every bit of state creates potentially exponentially more possible entity states. So therefore limiting potential changes in state limits the amount of working memory necessary to understand the system. Its starting with "can't" and then building a "can" when necessary, which is a lot better on memory, comprehension and feeling safe/secure to make changes then starting with a collection of 10^n "can"'s and adding in "can't"'s.
⬐ dwohnitmokFirst off I don't think this is quite the way Hickey thinks about the issue (though I suspect he would agree about the working memory part), especially with the comment about etymology /s!(it's a meme in Clojureland that every Hickey presentation and library must contain at least one slide on/mention of etymology) In particular Clojure as a whole embraces an ideology of "open systems" vs "closed systems" where we start with an infinite sea of "can"s and then add "can't"s as needed.But that's immaterial to your main point, which is that adding state into the mix of things makes things hard. Which I agree with, but again to steelman the point, I could turn around and say that values allow for exponentially more possible values as well! When I see a map passed into a Clojure function I have no idea what could be in that map!
I think the main objection here which you are alluding to is one of "global" vs "local" reasoning. With a value I just need to worry about the body of my function, whereas with (global) state I need to worry about every function everywhere! But what if that's just a problem with our tools rather than an intrinsic issue? What if I had a tool that could automatically present all the mutable state of your system that is publicly accessible as a single screen and automatically link to different procedures that link to different parts of it? At that point I don't see much of a difference between state strewn everywhere and nice orderly values plumbed everywhere. In fact maybe it's nicer to have that implicit state strewn everywhere instead of having to carry around values which are irrelevant for the bulk of a function body and only relevant for a single part of a subfunction. What if it's all just a matter of not having the right IDE?
Working memory is definitely a hard limitation and universal enough among humans, but it's not clear to me it's a specific enough concern to convincingly justify certain programming language features which may just be crutches for inadequate visualizations or different educational backgrounds.
⬐ joluxThere's a lot to think about in your comments in this thread but I have a nitpick about functional programming style here.> In fact maybe it's nicer to have that implicit state strewn everywhere instead of having to carry around values which are irrelevant for the bulk of a function body and only relevant for a single part of a subfunction.
I would call this an anti-pattern in FP. It's often a symptom of trying to replicate more imperative styles like OOP in a pure language. Threading mostly-irrelevant state through a bunch of different functions is a sign that your program is under-abstracted. If you think of all the function calls in your functional application as a tree, state should stay as close to the root of the tree as possible, kept in nodes it's relevant to, and the children and especially leaves of these nodes should be decoupled from it to the greatest extent possible.
⬐ dwohnitmok⬐ raspasov> Threading mostly-irrelevant state through a bunch of different functions is a sign that your program is under-abstracted.The problem is that often you do want fairly complex state in the leaves of the tree, but want very little of it in anything else. Web browsers are a classic example of this. Pure FP solutions such as Elm that completely eschew the idea of local mutable state require a lot more ceremony to implement something like a form (the classic thorn for Elm users). By forcibly moving up the state to the root, you sometimes end up needing to pull some fairly severe contortions.
E.g. the usual answer to move the state back up to the root in the land of statically-typed, pure FP is to express it in a return type (e.g. a reader or state monad, culminating in the famous ReaderT handler strategy in Haskell) or in the limit bolt on an effect system instead. The usual answer in impure FP is to accept some amount of mutable state and just rely on programmers not to "overdo" it.
But from a certain point of view, writing an elaborate effect system whose very elaborateness might cause performance issues and inscrutable error messages sounds suspiciously like trying to work around a problem in visualization with an over-engineered code solution. And from another perspective it feels a bit like a trick. If some function has a lot of state, then I would hope by opening up the definition of the function I'd see how it all works, but with an effect system all of a sudden I've split things up into an interpreter that actually performs the mutation and an interface that merely marks what mutation is to be done. It feels like I've strewn logic around in even more places than if I just had direct stateful, mutable calls there!
⬐ joluxI will say plainly that I think there are situations in which mutability offers more elegant solutions than immutability, but I think most languages that offer it do it badly. I’m most experienced programming the Erlang platform via Elixir, and I think it offers a really nice midpoint between locality of state and purity. Within a process everything is immutable, and mutation requires sending a message to a process that will have a function specifying an explicit, pure state transformation from that message. Just about the only thing I don’t love about Elixir is the lack of real types.I’m also very pragmatic and to the example of a web browser I would say, most applications are not web browsers. The overwhelming majority aren’t, in fact. I’ve chosen at this point in my career to mostly focus on enterprise software development, which I believe was Rich’s original field as well, and I’ve seen an enormous number of solutions with too much state cast about everywhere that benefit massively from centralizing the state high in the tree and really thinking through the data model carefully. So I stand by the principle I advocated originally, but it’s not universally applicable. It’s my belief that one of the core virtues of software development is knowing when to apply which principles.
⬐ dwohnitmok> to the example of a web browser I would say, most applications are not web browsers.I should've clarified. I meant developing a web page to run on a web browser, hence the form example.
⬐ joluxIt’s a good point. UI is a situation where the classic OOP-style frameworks work really well when they’re carefully designed. I think we’re still waiting on a model for doing that with FP that doesn’t rely on passing state deep down into an expression tree like React and its descendants encourage you to do. There’s stuff like Redux but it has its own problems.⬐ lincpaNoneYou can "solve" global mutable state with an IDE until you bring concurrency plus parallelism into the mix. Then all bets are off for mutable global state.In the case of Clojure, the map that you pass to a function is a value. It is guaranteed not to change underneath you and it can be freely shared with anybody.
⬐ dwohnitmok⬐ john-shafferWell to keep my contrarian hat on...> concurrency plus parallelism into the mix
The hard part of concurrency is writing or writing+reading, not just reading, so an immutable map isn't going to solve everything. Instead the hope is that you confine the mutability to one place with various transactional guarantees (in Clojure's case, this is usually atoms) and then everywhere else you don't have to worry about it.
But then again why couldn't the same analysis be performed on mutable state? How are we sure this isn't just a tooling issue? If we knew exactly what parts of mutable state were being touched by what we could identify what critical sections needed various guards.
Taking my hat off and going back closer to my own views, I actually think Clojure's combo of maps+atoms are an arguable case where Clojure has in fact complected things together in a way that e.g. STM doesn't (and Clojure's implementation and use of STM has its own problems). Namely it's complected committing a transaction with modifying an element in a transaction.
To illustrate the problem, right now Clojure atoms basically give up parallelism entirely. If you have a map in an atom with two threads modifying different keys, then those threads have to come one after another. It's actually kind of a waste of resources compared to the single thread case because work done in one thread will be thrown away and retried if the other thread wins.
So if you want true parallelism when modifying different keys you can use a ConcurrentHashmap. But that then gives up atomic updates of multiple keys at once! (Or you can have nested atoms but that has its own problems and doesn't solve the inter-key atomicity issue).
It looks like an all or nothing proposition where you either get non-parallel but fully atomic map updates or parallel per-key updates but nothing in-between. These kinds of false dilemmas are a classic symptom of complection.
The way other languages with an STM system deal with this is to build concurrent maps out of STMs refs. That way you get exactly the amount of parallelism you can relative to the amount of atomicity you need. If you have a transaction that touches two keys at once then both of those keys are atomically updated together and those two keys form one unit of parallelism. If you have a transaction that only touches one key then you have per-key parallelism. If you have a transaction that touches all the keys at once then you just collapse to the normal case of a map inside an atom.
As far as I can tell the reason Clojure doesn't do this (but other languages have) is that its STM API is a bit clunky and missing some interesting combinators.
All this is to say that maybe indeed simplicity and ease aren't all that different if from one perspective atoms are simple and from another merely easy.
⬐ raspasovThose are well reasoned points.I'm not going to delve into STM because that can be a whole book worth of discussion :). It's a fascinating universe, I've spent many hours (weeks, months?) exploring it, and I don't consider myself even close to an expert.
You are absolutely correct about the trade-off about atoms in Clojure.
Practically speaking, to start seeing retries you'd have to have a big number of updates going on at the same time. You can push a huge number of updates through a single thread. If you do have the need to do big throughput, you can explore not-so-idiomatic options like atoms-in-atoms, like you said.
IMO, the biggest unique benefit of combining atoms with immutable persistent data structures, comes from the fact that you can get unlimited number of consistent readers virtually for free. Any thread can look at (aka, deref) an atom, while the state/world keeps moving forward. I don't think any amount of tooling can solve that case for mutable data. A snapshot of a mutable data structure would require copying the whole data structure while using some sort of a locking strategy to stop writers while the read is taking place.
In production, I may only want one connection pool to a DB, and in that case global state is pretty much equivalent to passing state as an argument. Development in a Clojure REPL is a different story. I have one connection pool for the dev server, and a separate pool to run tests against. The test db is re-created from a template between each test run, without affecting the dev db at all. I can trivially have multiple test pools if I want to run tests concurrently.I also have a separate service that the server makes calls to, which doesn't run on this server in production (it has its own production server), but does run in dev and test. Each dev/test system runs a separate instance of this service, which has its own separate connection pool(s), and setting this up was trivial.
Needless to say, failures are reproducible and meaningful. There is no mocking -- we test against real local services with real local DBs. (There are still some remote service calls which I'm slowly replacing, and some flakey, unavoidable remote dependencies in a few browser tests).
I didn't do anything special to make this possible other than naming the config files "service-name-config" instead of just "config". It is just the natural result of passing state in explicit arguments. The same is not true of global state.
⬐ dwohnitmok⬐ nyanpasu64To continue with my devil's advocacy...> It is just the natural result of passing state as explicit arguments.
But nothing you've mentioned here is intrinsic to mutable state. It seems like all that's happened is you identified a part of your program that you wanted to be configurable and exposed a configuration knob. If for example you wanted to make it so that there is a test mode that where you want to prefix "test-" to every string written to the DB that would also probably involve a new argument somewhere. There's nothing here special about the mutable state part of it.
> But what if that's just a problem with our tools rather than an intrinsic issue? What if I had a tool that could automatically present all the mutable state of your system that is publicly accessible as a single screen and automatically link to different procedures that link to different parts of it?The world needs this. I think Pernosco has a workable technical foundation, but the GUI is a debugger and I need a code exploration tool to "find my way" in big unfamiliar codebases. Encouraging developers to pick up and hack around in others' codebases is the only way to get enough eyeballs to make all bugs shallow.
> maybe it's nicer to have that implicit state strewn everywhere instead of having to carry around values which are irrelevant for the bulk of a function body and only relevant for a single part of a subfunction.
I think global state (which is unusually bad) or shared mutable state (which is omnipresent outside of Rust) is a mental overhead (more things to keep in mind). I don't think tooling can eliminate the overhead of worrying about moving parts, only make it faster to look up (and hopefully document) what touches each bit of state.
I personally think "encapsulation" is a misnomer. State is not encapsulated I OOP,it is just hidden. Proper state encapsulation would be to use mutable state internally for efficiency, but for that state to be unobservable externally.OOP does unfortunately encourage introducing mutable state into the domain model. The canonical example being the back account, with a mutable back balance!
⬐ simongrayIf you're going to reference a Rich Hickey take-down of OOP, I think "Are We There Yet?" is the most pertinent: https://www.youtube.com/watch?v=ScEPu1cs4l0Of course, Simple Made Easy is excellent too, probably his most influential talk.
⬐ kazinatorTime does not go away from the concept of value when you remove state.What state takes away is access to a given value at any other time but now.
It's always now; every value is the current value and no other version of that value exists.
⬐ krafNot just you, I had the same experience. I rewatched it several times over the years and understood something new every time.⬐ mycall> State intertwines "value" and "time"Reminds me of deterministic finite automaton. Is that what you mean?
⬐ cutlerMe as well but I was already sold on Clojure by then.⬐ butwhywhyohThe problem I have with talks like this is that they sound fantastic on the surface. They almost sound self-evident! "Duh! I want to make simple things, not easy things! That was great!"But where are the examples? Not a single example of something easy versus simple, or how something "easy" would resist change or be harder to debug. All of these concepts sound fantastic until you begin to write code. How do I apply it? It's a great notion to carry around, but I often wonder if this is just someone's experience/opinion boiled down to a really well done talk, and not much else.
⬐ baryphonicIf you want functioning, robust, maintainable software (or even better, software that doesn't require maintenance), then spend a long time modeling the problem domain. Build it as a system of types, a protocol, perhaps even a language (or at least an AST with semantics). Prove things about this model, particularly some useful things about soundness, consistency and (in)completeness. Learn all the funky symbols people use in the literature, learn about the strange tools you weren't told about in undergrad like dependent typing or higher-order contracts or CRDTs and lattices. Spend a lot of time doing this. Then, when you have determined the essential shape of the domain and nothing more, implement the software. At that point, the code almost writes itself.I submit that if we did that, we would have excellent, elegant, simple software, but following the process would be incredibly hard. So hard, in fact, that it couldn't possibly be distilled into a conference talk.
⬐ Hercuros⬐ jackblemmingSpeaking as someone with experience with many of those things (PL theory/formal verification background), I don't think they're even close to being a silver bullet.Coming up with the right abstractions and the right domain model is difficult (especially if you just sit down and try to come up with stuff, you're likely to get it wrong the first time around). Knowing about some of those things could help you come up with better abstractions, but it's neither necessary nor sufficient to ensure that you will.
Take dependent types for example. They allow you to express more program invariants or correctness properties in your types. But actually using them requires you to write proofs (at least, if you're using them to their full potential). And I do think that in general System F like type systems hit a nice sweet spot and are generally good enough for the stuff that you might actually want to handle on the type system level.
I've also run into similar "proof-like" situations with much simpler type systems like those of Haskell and Rust, where I was structuring my types to "make illegal states unrepresentable", but in the process ended up complicating my program due to having to match the structure of my program to the expected structure of the types. Sometimes it is nice to _not_ to have the type system enforce some of your invariants. (Such things are also doable with dependent types of course, but this is just an example of some of the tradeoffs involved).
You can also still have a shitty domain model even if you use all of those fancy tools. They just allow you to be very formal/precise about the domain model (and do perhaps encourage some more uniformity by making it more annoying to express ugly or complicated things).
⬐ FpUserDomain knowledge is very important. In the real world however by the time you finish this type of process the competition will have had the product out already. It may not be that perfect castle in the sky but it will work and if you have revenue you will have time and means to improve.⬐ baryphonic⬐ jcelerier100% agree. It's a trade-off. Get product-market fit first and learn what you can about the domain. Spend enough time on architecture up front so you can easily pivot. That's all the simplicity you should care about at that point.Once you get traction, you can start to afford to have the crazy vision. IMO, at that point it's easily worth the risk. A decent research team will probably discover something, and potentially extremely valuable knowledge.
If you were James Clerk Maxwell before he published his equations, how much would they be worth to you, especially if you had paying customers?
⬐ magicalhippoOur customers don't even want to pay for something that bespoke. They have margins to worry about.So instead we've had to make a system which makes it less painful when bugs occur.
For us that means making it trivial to run older major and minor versions our software, and an automated update mechanism which delivers new builds to customers on-premise in less than an hour, updating the DB schema as well.
⬐ samhwI don't think this excludes what the GP said, but this is super important as well. I think of it as second-order reliability: design your software not only so that bugs don't occur, but also so that the user can take practical steps to remedy bugs if they do occur.(Also, as one of my past companies enshrined as an engineering axiom: "write software to be debugged". Most programmers write waaay too few logs. You know the print statements you add to your code when it's buggy, to track down what's going wrong? Well, do that all the time, and if there are too many then fix that problem with adequate tooling. If it's running on your customers' computers - whether servers or PCs or phones - then store them locally for N days / N logs and allow them to be submitted when a bug occurs. Stack traces - even good ones - are not nearly enough.)
By the time you're 20% in that process your competitor has already overtook the market.⬐ baryphonic⬐ alatkinsTo quote Thiel, "competition is for losers."Counterpoint is that the Big Design Up-Front utopia didn't win in software, giving rise to Agile (for better or worse).⬐ wpietriWhat sort of domains do you see as sufficiently well-understood and stable where this process is even achievable? A lot of my career has been in domains where we are exploring problems by building and shipping things to see what really works for users and customers. And other times there's domain volatility driven by changes in technology and competitive landscape.Even for domains that are stable and knowable, I have to wonder what businesses can afford that kind of up-front investment before the first feature ships.
⬐ magpi3Compilers maybe?⬐ wpietri⬐ baryphonicOoh, interesting! You're right, there's a class of domain where one can just push the real-world change to the edges of the system and ignore it. E.g., there's surely software that's mainly about complying with laws.But even there, I suspect adaptation has to happen. Python's had how many versions over the years? Indeed, I could argue that it's one of the world's most successful languages precisely because it keeps responding to user need. Or look at tax software, which is going to change at least every year, and more often in emergencies.
So I suspect at best these other domains have a slower iteration clock. Which might be slow enough for the sort of formal modelling that is described. But then I think there's an open question: do other methods also work just as well with slow iteration clocks?
I've had largely the same experience as you, but I have seen some hints that real simplicity could be possible. If the domain is technology itself, there may be no underlying simplicity.Ultimately, I think we have to make a trade-off between simplicity and easiness. The approach I outlined would be incredibly expensive because the tooling for that approach isn't quite good enough yet, and stakeholders wouldn't even understand it. They wouldn't realize that you were building a pitch for your product not as a PowerPoint deck, but as executable code!
A lot of our complexity today is from constructing software itself over layer upon layer of previous complex software (CSS, I'm looking at you), not due to the intrinsic "business cases" our software is meant to solve. Some of that complexity cannot be avoided, and some of it could be but at significant cost. To use an analogy, it's also cheaper to build a traffic light-controlled intersection, but overpasses are simpler.
Coincidentally, almost all of the tools I've seen that try to make simplicity cheaper come either from the Scheme/Racket/Lisp world that Hickey himself hails from or from Alan Kay and his sphere of influence. (The two groups have quite a bit of overlap, both in terms of ideas and even people.)
⬐ wpietriSorry, I'm still not seeing how/when the approach you're hinting toward is practically valuable. So far it seems to me like you're pursuing one dimension of quality to the exclusion of others. Which is an interesting theoretical exercise, so if that's your jam, have at it. But it sounded to me like you were proposing something people could actually do.⬐ jiriroCould you please elaborate on Hickey’s and Kay’s key ideas and how to try them hands on?I know about Smalltalk (Squeak) so I guess that is the playground for Kay’s. Would just playing with Clojure do the same for the Hickey’s?
Easy things work until you have to extend them or do anything the least bit complicated. Think of SQL or most "easy" declarative APIs. Or even worse, ORM engines. Simple things are normally also easy to use, but you may have to write some more boilerplate and there's less "magic".Steve wrote a simple CRUD API that gets some data and returns it. Bob tried to be clever and write a loosly typed declarative cluster fuck that nobody understands, but it's "easy" if you dont do anything interesting or useful with it.
⬐ raducu⬐ codebjeA bit like haiku, wonderful when you read it, extremely hard to maintain conversations in haiku.Or like an improv exercise where you have to improvise a dialogue, but only by using questions, no afirmations.
Can it be done? Sure, but not by most people, not in real time. Again, wonderful when you see it done right.
⬐ PeritractTalking in haiku: Wonderful when you read it. Too hard to maintain.Improvisation. A constrained dialogue. Affirm? No. Question.
Can it be done? Sure. Most people struggle slowly. When right? Wonderful.
It's easy to stop calling a now-unused function when some behaviour is no longer needed.The system is made more simple if you remove the function, though.
This is more so if only part of the behaviour of a function is no longer desired - the function becomes easier to understand when it's trimmed down, but it's harder to make that change.
⬐ simongrayThe presenter is Rich Hickey. He is the guy who created Clojure. He basically designed the language around this principle (it is a very opiniated language). If you want examples, look at Clojure and its ecosystem where the ideas of Rich Hickey are held in high regard.⬐ kgwxdThe Clojure language is the example. Basic data structures vs classes/objects, immutable vs mutable, lisp vs other languages, etc.⬐ DyslexicAtheist> They almost sound self-evident!I think it's hard to provide examples since they would all be implementation dependent.
simple to me is a stage of the thought process that will become apparent only after putting in the extra work. It's not just applying "this 1 trick". Making it simple is its own unique challenge. E.g. my first iteration of an idea is always a mess. Then I rework it enough times to make it presentable (a state where it "works" and I can reason about it with others). But on the job nobody pays me to make things simple because that means spending another 10-30% of the budget on it. making things "simple" at work is nearly impossible to sell because people quickly through arguments at you like "perfect is the enemy of good", and few jobs give you a "definition of done" where making things simple is part of it.
Another reason why it's impossible is that the best time to rewrite a greenfield project or an MVP is before you add additional features. But at that point people will not allow it because the expectation usually is to build on top what you (they) invested in previously.
⬐ bcrosby95The point of simple vs easy is they exist on completely different dimensions. There's simple/complex, and there's easy/hard. Something can be simple+easy, simple+hard, complex+easy, or complex+hard. Obviously there's a sliding scale in each dimension.Simplicity in a vacuum isn't a good thing. Ideally your solution targets the exact level of simplicity vs complexity required for your problem. Obviously you won't always hit or know the target.
The value in simplicity is greater composability. It's especially important for the building blocks of our systems - of which programming languages make a huge portion. It doesn't sound too controversial to say that it's easier to take multiple simple things and make a more complex thing, than it is to take a complex thing and distill it down to the simpler thing you need. I say this because regardless of what programming paradigm you adhere to, the "kitchen sink" unit of code is universally derided, be it god modules or god classes that does shit you don't need.
It's not that Clojure is all simple, all the time. There is mutable state in Clojure - atoms, refs, etc. They also have interfaces. And multimethods. And so on.
But the simplicity floor is lower in Clojure than most other languages I've used. More than those other languages, you can target the level of simplicity you need. And it provides for more complex elements if you need them. And in my experience, a lot of the time, you don't need those more complex elements.
If you have an hour spare, probably the best way to understand Clojure's main selling points is to watch this talk: https://www.infoq.com/presentations/Simple-Made-Easy/InfoQ list the Key Takeaways as:
- We should aim for simplicity because simplicity is a prerequisite for reliability.
- Simple is often erroneously mistaken for easy. "Easy" means "to be at hand", "to be approachable". "Simple" is the opposite of "complex" which means "being intertwined", "being tied together". Simple != easy.
- What matters in software is: does the software do what is supposed to do? Is it of high quality? Can we rely on it? Can problems be fixed along the way? Can requirements change over time? The answers to these questions is what matters in writing software not the look and feel of the experience writing the code or the cultural implications of it.
- The benefits of simplicity are: ease of understanding, ease of change, ease of debugging, flexibility.
- Complex constructs: State, Object, Methods, Syntax, Inheritance, Switch/matching, Vars, Imperative loops, Actors, ORM, Conditionals.
- Simple constructs: Values, Functions, Namespaces, Data, Polymorphism, Managed refs, Set functions, Queues, Declarative data manipulation, Rules, Consistency.
- Build simple systems by: Abstracting (design by answering questions related to what, who, when, where, why, and how); Choosing constructs that generate simple artifacts; Simplifying by encapsulation.
So Clojure is a language that embodies these principles in its design. It's a Lisp, which means that all code is constructed from a very regular expression syntax that has an inherent simplicity and can be quickly understood. It's a functional programming language that provides exceptional tools for minimising mutating state, and it favours working with a small set of data structures and provides a core api with many useful functions that operate on them.
I'd say the result is getting a lot done with a small amount of code, minimal ceremony, true reuse, and the ability to maintain simplicity even as your system's capabilities grow.
⬐ fulafelThere's also transcripts of this and other Rich Hickey talks available: https://github.com/matthiasn/talk-transcripts/blob/master/Hi...
The irony of thinking files and folders are too much for simple app and also praising a feature that is in direct relation to php’s MO of conflating codebase folder structure with requests’ path.Edit: this reminds me, I was like this too at the beginning of my dev career, I also was completely in favor of this supposed “simplicity” of php, only much later, thanks to hickey’s nice talk I realized that I was confusing simplicity with ease.
⬐ hn_throwaway_69In a simple application there is nothing wrong with your folder structure being related to the request path. Heck, such an approach is practically mandated for static sites.⬐ hn_throwaway_69Sorry, I don't understand your first point, even after reading it several times. I think I might have inferred what you meant by looking at the second (edited in) point, but I'm not sure.Are you suggesting that it is bad that PHP applications often have a request path that relates to the folder structure?
In other words, are you suggesting that simplicity means an application should not have a request path that relates to the folder structure?
To give an example, are you saying it's a bad thing that example.com/profile/ loads /profile/index.php, rather than passing /profile through a single controller function to identify what code should be responsible for handling it?
The first approach actually seems pretty straightforward paradigm and it's what most new programmers would expect. Adopting a MVC/routes method is more complex and arguably overkill for a simple application.
If that is what you are contending, it should be said that PHP does not require this approach. Although it is often a preferred approach, because it doesn't depend on additional web server configuration.
⬐ keymoneI’m not suggesting, I’m saying that conflation is mother of confusion. Conflating request path with file path is not a great idea, especially for new developers that get a mental model of how web apps work that is completely irrelevant for the rest of their careers.⬐ hn_throwaway_69There's plenty of large PHP projects that adopt this paradigm. Is it really fair to say it will be completely irrelevant for the rest of their careers?Also, let's not lose sight that this arises in a context of criticism of the model adopted for programming a simple form. This is just a simple one page form. More complex or abstract paradigms or design patterns is overkill.
As always it depends. If you're thinking about preprocessor macros and operator overloading from C++, sure, those can be annoying, it's more to do with C++'s implementation and usage of them than the features themselves. You might want to try Common Lisp sometime; so much of the base language is made up of macros without which programs would be neither pleasant to read or write, and the language itself provides facilities to ask "ok but what function(s) are actually going to get called with this data" so that even not-so-local things like e.g. transparent logging of a call's input/output become visible if you need to know. But CL is not a language one can pick up in a couple of days -- albeit CL shops report success in getting new hires to be productive after a week or two of reading a book and the company code, which is a common onboarding time at many companies with any language.Programmers notoriously conflate "simple" and "easy" (classic talk: https://www.infoq.com/presentations/Simple-Made-Easy/) and so I believe languages that are easy for a lot of programmers will also be perceived as simple, whether or not that's accurate.
I need to go to the bathroom. The simplest thing that solves my immediate problem is to urinate in my pants. I ate a bag of chips and now I have an empty bag to dispose of. The simplest thing that solves my immediate problem is to throw it on the floor.So it's clear that "the simplest thing that solves my immediate problem", like simply adding a new int field to the most convenient table, can compound into an awful mess. But perhaps "simple" is not the right word here.
I like Rich Hickey's talk on simple vs. easy; we're both using the wrong word according to him. "Simple" means not intertwined or tangled; well-organized. "Easy" means "close at hand" or "familiar". We both mean "easy" here.
https://www.infoq.com/presentations/Simple-Made-Easy/
That being said, your examples of complexity fetish do indeed sound awful. Abstract classes, optional configuration files, environment variables and regular expression; we can agree those are awful. Those are neither easy nor simple. But the problem is that they're not discussions about the domain, they're truly unnecessary. Maybe that's all you really mean.
>We had to add something to the database the other day. Big argument. Should be one to many? many to many? what if this or that happens? what if requirements change? You know what - for the requirement we actually had it was solvable with a single integer field on an existing table.
Agreed about not inventing requirements, but questions about "how is this likely to change in the future?" are much closer to productive discussion. Discussions about one-to-many vs. many-to-many can also be the exact discussions software developers should be spending most of our time on (although don't get me started on the awful database designs most software has, so these discussions may be inane for that reason alone).
⬐ andrewmcwattersYeah, except no one says, hey let me piss myself now and in version 2 I'll whip it out and then piss on the floor, and eventually I'll piss in an AbstractReceptacle.Instead, developers ask themselves, will we want to piss anywhere in the future? Yeah, lets develop an abstraction to piss anywhere, but should we also plan for this urination to be sexual in nature? Better make sure we can use composition to mix in kinks whenever we'll need that, because surely we will, even though our piss implementation is toilet only and we barely have the time or budget for that.
Maybe we really should offshore all technical labor, too, because if developers had their way, they'd gold plate pissing and never develop the actual toilet, forgetting they had to eventually get around to that, too.
⬐ ProZsolt> I ate a bag of chips and now I have an empty bag to dispose of. The simplest thing that solves my immediate problem is to throw it on the floor.Maybe that's the best solution for the long run, instead of designing and implementing a whole garbage disposal system from the ground up for only one piece of trash.
My problem a lot of software developers are trying to solve problems they don't have and never will. This consumes time and adds unnecessary complexity to their projects.
⬐ mysterydipPrematurely designing for scale when I just needed to finish the beta version has been my engineering vice.⬐ heavenlyblue⬐ feorenHaha, on the other hands a lot of developers never grow out of always developing betas and their only concept of programming is developing betas and then dealing with fires all the time.⬐ inDigiNeousFor me too this took years and years to learn. It's a hard lesson that seems can only be learned by walking the road and learning from working on a particular piece of software for a long time, at least that's what it took for me.I guess it's called experience to know when to design and when to just implement. Somebody wrote somewhere for example that if you're not going to need a particular piece of code in more than 3 different places, don't write a function for it.
As a newbie you would totally want to write a function for it, thus also making it harder to read the code as you would have to understand the function in order to see what it does in that context.
Also thinking in terms of "Do I really need this feature in future use cases?" is something I don't feel you can assess when not having the experience of already have peeked into those future use cases, where in many cases you will not ever need that particular function in more than this one place.
But can you learn how to design a reusable system without first doing it in the wrong places ? That's something that is hard to say, I don't know.
Could you teach somebody who wants to build complex, reusable components not to do it and just stick to simplicity ? How would one then know how to build those reusable systems where you need them ?
Maybe we should focus more on training both simplicity and complex design, but rarely you can do that when you are under pressure and working on real life software.
Haha, touché; I thought I had come up with completely unassailable examples of obviously bad choices but you've made a good point that a single piece of trash on the floor may occasionally be the best option. Engineering is all about tradeoffs, even in the extreme.⬐ MengerSpongeaka YAGNI⬐ citrin_ruPeople are bad a predicting future. Especially when this predicting is done in 5 minutes before implementing something and not dedicated activity which includes interviewing of users and domain experts.I've seen this many times: programmer is asked to solve a small and well defined problem. Instead programmer generalizes it and makes something more universal with the requested feature as a special case. More often than not nothing except this special case is used.
Or working on some new project they add a feature which looks useful in theory, but ends up being rarely/never used. It may look easy to implement initially, but over the years maintenance cost can be much higher.
⬐ pipingdogPeople are amazing at predicting the future, and in some ways we are better at it than remembering the past. That's because we use the same machinery to do both. We partly remember the future, and predict the past. This ability breaks down with complexity and abstractness, as well as with novelty, all of which are involved in software (I can tell you that the sun will come up tomorrow, and where I should move my hand to catch a ball, but I can't predict all of the defects my software will have--though if it involves X.509 certificates, I can tell you exactly when a particular sort of outage will occur)
> In fact easy, in terms of getting something working, trumps difficult simplicity any day of the week. Easy is part of what makes an employer want to use your technology.The whole point of the talk is that choosing "easy" (as in easy to get started) solutions while ignoring the complexity will be harder to maintain in the long run over choosing the "simple" solution that takes a bit more time to set up. Personally, this tracks pretty closely with my experience.
(Relevant slide from the talk: https://res.infoq.com/presentations/Simple-Made-Easy/en/slid...)
{kind=link}
Some clarity:1) Experts don’t say fuck you user by intentionally doing hostile things for their own convenience or emotional satisfaction.
2) Elegance directly suggests simplicity and polish where simple means few:
https://en.m.wikipedia.org/wiki/Elegance
https://www.infoq.com/presentations/Simple-Made-Easy/
That’s fewer shit in the code, which eliminates decoration and unnecessary conventions many developers cannot live without.
3) Beginners and weak insecure developers focus on composition. Experts focus on the end state.
⬐ lmilcinOh, of course, that's all true.The difference between elegance and simplicity is when you start to talk to developers who learned just enough to be able to put patterns in their projects but not enough to know when to do so.
> 3) Beginners and weak insecure developers focus on composition. Experts focus on the end state.
That is one more way to say that experts use programming as a tool and that programming is not a problem for them and so the biggest issue they see is that the end result is the right one.
It is easier to focus on the end goal when you trust you have some kind of solution for any problem that can happen on the way.
On the other hand novice and intermediate developers focus on technical because this is the challenge they are facing. And they don't yet feel they can solve every problem they will face. You can't tell them to not focus on technical because it is useless advice -- they need to learn technical first before they can become experts and focus fully on the end goal.
The best you can do is to remind that the end goal is important and keep it on the back of their heads even when they are immersed in technical challenges.
**
As to "insecure" developers, I think there is something to it. Moving from purely technical problems to other kinds of problems (looking at big picture of the product, the client and the development team) requires a little bit of courage (don't laugh). It is easy to keep working within the same types of problems that you are comfortable with, and make illusion of progress by changing technologies, working with larger applications and so on.
I had a prospective client some time ago. They wanted me to help with their application. They had trouble delivering and additionally their application was unreliable.
So on the meeting with the director, architect and tech lead they asked me to start by upgrading Java from 6 to 11.
Mind, that this is discussion with a director that had some 40 devs and reached out to me personally to get help.
So I asked "Guys, do you really want to say that people were not able to deliver reliable application with Java 6? Or maybe the problems are somewhere else?"
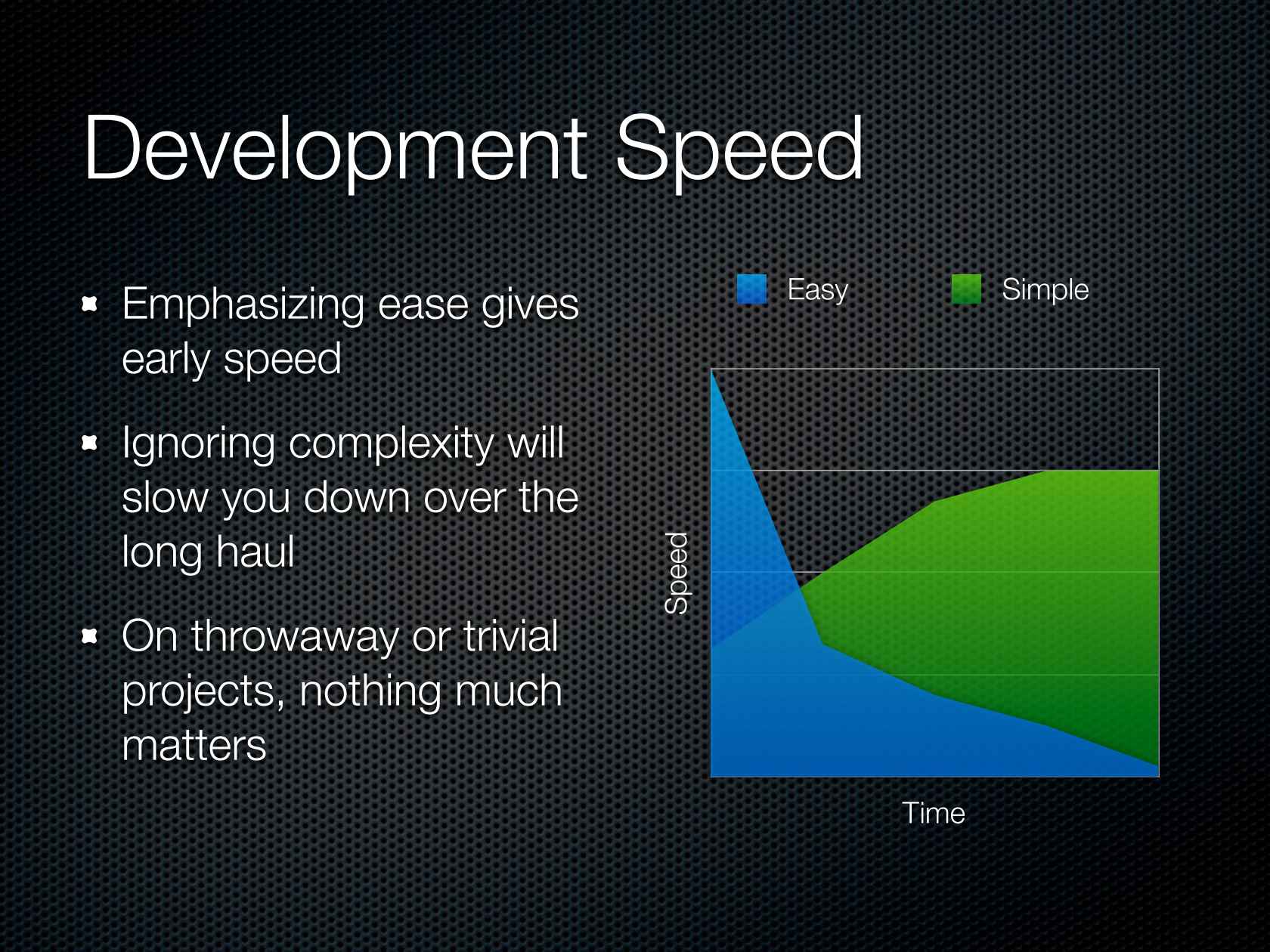
The chart comes from Rich Hickey’s Simple Made Easy presentation. Watching that will provide missing context that may answer some of your questions.
Indeed. Thank for you stating this so clearly.The "ease of use" and "familiarity" distinction reminds me of talks by people such as Rich Hickey who distinguish "simple" and "easy":
https://www.infoq.com/presentations/Simple-Made-Easy/
> Rich Hickey emphasizes simplicity’s virtues over easiness’, showing that while many choose easiness they may end up with complexity, and the better way is to choose easiness along the simplicity path.
This sounds like elitism in disguise to me.Sure, there are some cases when you want quick and dirty and just glue some system together, but most production code out there has some more important business requirement than "understandable by the cheapest engineers out there".
For instance, if you're writing an account management system for a regional bank, you'll care most about the accuracy and longevity (including easy maintainability) of the system.
If you're writing a microservice for a fancy web app with global distribution you might care about latency (high latency drives down CVR), reliability (errors drive down sales and ads too) and sustained agility (you need to develop features fast to keep ahead of competition).
I think the second example covers most of what web and mobile developers do. I've definitely seen cases of over-engineered systems with many layers of leaky abstractions, but also many cases of under-engineered systems. Here are some well-documented maladies:
1. RYE (Repeat Yourself Everywhere) - You have the same business logic repeated in multiple places, because originally it didn't seem common enough or large enough to warrant DRYing up. This is obviously easier to read, since you don't need to dive deeper into more functions, but in practice the shared logic quickly diverges between the different cases, until it's very hard to specify what your system does.
2. "Let's just add an if branch here for this special case" - quick and dirty, as unclever as it can be, until you realize you need to deal with the combined permutations of 20 different branches. This is readable only in the very surface sense.
3. "Our junior engineers understand for loops better than map-filter-reduce chains, so let's use for loops instead of spending a few days teaching them": You can replace "for loops" with anything else that your junior engineers happen to know. The end result is not avoiding an over-engineered or "too clever" solution, but rather just avoiding a solution that is often simpler and easier to understand but just happens to be unfamiliar to your engineer. See also "blub paradox".
4. "This 500-line function is brain-dead simple and uses no fancy tricks". Likewise, it's easier for a junior engineer to write long-winded code and avoid thinking about even the simplest abstractions. And the code works! This doesn't make the code more maintainable or reliable though.
5. "Let's add ad-hoc retry with for loops and branches when necessary instead of creating an abstraction based on closures or let alone monads - this is just too clever". End result: reliability is added only after somebody complains about a certain functionality instead of being designed and baked into the service, and your service suffers accordingly.
There are many more examples, but the general gist is that in almost every corner of our industry there are important concerns that require us to take our engineering practice seriously. I think statements like "It's all just glue code", "It's all just plumbing" or "It's just a CRUD app" are not constructive for quality.
I wholly agree with you about simplifying things. I just think we should be mindful of the difference between "simple" and "easy" (as Rich Hickey famously put it[1]). What is easy for a junior developer to understand (because it doesn't contain any concept they haven't learned yet) may increase the absolute complexity. If you choose the "easy" solution here, you make the code seem _subjectively_ simpler to junior developers, at the price of _objectively_ (and measurably!) increasing cyclomatic, cognitive or state complexity.
Unless the "clever solution" requires understanding that is beyond what we can expect the reasonable average engineer to learn quickly, I prefer to always err on the side of reducing absolute complexity, and code that is simpler to read _for senior engineers_.
⬐ AstralStormThe problem 5 is sometimes caused by the management not allowing time for a proper redesign of a prototype. (Even if TDD is employed, which often is not because tests are not user deliverables.)Hence why my statement "iterative development never works" as the managers will see the initial prototype mostly/partly working and start pushing features on it.
In such an environment, you need an experienced designer from day one - at worst you'll get slightly less performant but maintainable code due to extra abstractions.
If you get a design mistake... Well...
⬐ methodiosmelGreat response!!! I wholeheartedly agree⬐ ehntoYou bring up some great examples, I think we do agree in principle. I must point out that I didn't really specify what simple was to me but it's quite a nuanced topic as your examples show. I just mean keep it reasonable given the context.Why I think we do agree is that what I really love to see is actually idiomatic code. Does the software you're working in already use array map/filter? Then go right ahead. Could the types of developers working on the project be reasonably expected to learn it? Then also, go right ahead!
I prefer to use frameworks for commercial projects because of this reason. I can hire more talented developers because I can test to see if they know the idioms well, and I can also be happy investing in their learning of the framework knowing that it's going to be repeatably useful for them while working on the project, and can upskill the whole team over time. You're essentially defining a body of knowledge expected by picking a framework.
Similarly when you're architecting software you're essentially choosing what level of developer you're going to need to hire or train, and so if you're in that position it's smart to be cautious of increasing the burden of knowledge too much unless you're happy hiring for that.
⬐ ItsMonkkI disagree, and agree with Mark Seemann's take[0]. If something is better, switch to it even if it causes inconsistencies. Over time you can refactor the old code.You've limited your projects progression to if a billion dollar company has created a framework that is more productive such that they can be taught it in University. You'll never get hackers like pg who can code LISP if you go that route. You should hire good talent and then train them such that they understand, and hopefully keep them and they stay long after they work on your one project.
⬐ AstralStormAssuming that you will be ever allowed to refactor properly rather than be put under immense pressure to fix other things right now.⬐ ehntoI think that's the crux of the disagreement, I explicitly don't want hackers, I want professional software developers to execute a very reasonable software project effectively, which is not everyone's cup of tea.There's plenty of room for hackers in the industry, to go make really cool stuff and make endless cash, and I love the architecture part more than the rest of it so for personal projects that's what I'm all about. But if I want to achieve delivery on time and in an expected format, I want zero hackers, I want career engineers. That is definitely a boring take for some, but that's just part of a maturing industry. Not every project needs to be an R&D project at the same time.
"Simple Made Easy" by Rich Hickey: https://www.infoq.com/presentations/Simple-Made-Easy/ "We should aim for simplicity because simplicity is a prerequisite for reliability. Simple is often erroneously mistaken for easy. "Easy" means "to be at hand", "to be approachable". "Simple" is the opposite of "complex" which means "being intertwined", "being tied together". Simple != easy. ..."
The primary source for this is https://www.infoq.com/presentations/Simple-Made-Easy/(I am not entirely sure I agree with its thesis or its applicability to Go, but since nobody had actually linked you directly to the concept, I thought it would be worthwhile to do so.)
I think Go can only be defined as "simple" in the New Jersey (worse is better) sense of simple, that is: "it is more important for the implementation to be simple than the interface."A lot of things about Go are not simple. In my opinion a simple language is not about how simple it is to write a parser or a compiler for that language, but it's about how many different non-trivial and arbitrary pieces of information the developer has to memorize.
This is highly tied to the Principle of Least Astonishment[1] in language design: how many unexpected surprises does the programmer have to deal with?
With Go, you get quite a lot:
1. Go already has generic types. These are the magical maps, slices and channels. Everything else is not.
2. Even if you think #1 was also true for Arrays in Java 1.4 and no one was complaining, Go goes further: it already has generic functions like 'copy', 'len', 'min' and 'append'. Since you cannot properly describe the interface of a magic built-in function like 'append' using the Go language itself, this is not a standard library function, but should be viewed as an entirely new piece of custom syntax, like the print statement in Python 2.x.
3. Nil interfaces and interfaces with a nil pointer are not equal.
4. Multiple return values are a magical beast - they are not tuples and you cannot manipulate them in any useful way.
5. Channel axioms[2]. Possibly one of the more astonishing and painful aspects of Go.
5. Slices are mutable, unless you copy them. This can lead to some very surprising cases where a slice is passed down many layers below and then modified, breaking the caller.
6. Continuing the topic above, Go has neither clear data ownership rules (like Rust), clear documentation tradition on who owns the data passed to functions (like C/C++) nor a way to enforce immutability/constness (like C++, Rust or FP languages). This really pushes a lot of the cognitive overload to the developer.
7. Go modules are a lot better than what we had before, but are quite hard to deal with. The moment you need to move to v2 and above and start creating subdirectories they becomes rather confusing compared to what you would do in other package management system.
8. If a simple language is a language that allows you to write _simple programs_, and you follow Rich Hickey's classic definition of Simple[3], then Go is probably one of the LEAST simple languages available today.
tl;dr: I'm not saying other languages often compared to Go (like Rust or Java) don't have their own share of complexities, but I don't think Go should be viewed as a simple language in the broadest sense. It is a language with a rather simple implementation for our day and age (though Pascal was much simpler if we stretch this definition backwards).
[1] https://wiki.c2.com/?PrincipleOfLeastAstonishment [2] https://dave.cheney.net/2014/03/19/channel-axioms [3] https://www.infoq.com/presentations/Simple-Made-Easy/
It's hard to say from a single quote from a single person. I dare say most developers confuse difficult with complex.[0] His coding style may have been brutally simple, even if that meant very hard. He also could have been a bad programmer.I often take a look at a problem from multiple perspectives in order to try and find ways of minimizing the number of special cases or minimizing the number of states in the (perhaps implicit) finite state machine. This is often harder than just gut-feeling my way through the most intuitive ad-hoc coding solution.
For instance, if something has an optional timeout, I strongly prefer to write it as a non-optional timeout that defaults to something absurdly large (but not so large as to uncover multi-billion-year overflow bugs in libraries I'm using), usually 100 years. Maybe that's the hard way of doing it, but it gets rid of special handling of the optionality. I'm sure some colleagues would describe this as "the hardest way" to write an optional timeout, but it objectively has fewer code paths to reason about and test. Some people really hate seeing code that doesn't treat the no-timeout case as a special case, because they just find it uncomfortable to switch perspectives. They really want to code it up as they most naturally think about it, not in the way that yields the least twisted code.
In another case, one of my colleagues wrote some minor error recovery logic for a distributed system. I politely told him that his solution had too many implicit states and would get stuck if messages were delayed between systems. I proposed a simple 4-state machine: ok, trying_to_resovle, resolved, and taking_too_long_to_resolve. But, he was the one originally assigned the task, I didn't have any real authority, and it wasn't worth a fight. He said the way he wrote it was "easier" and "more natural." A few months down the road, his solution got stuck and never alerted us that it was taking too long to resolve the error, because messages got delayed between systems. In an afternoon, I whipped up my original proposal: since the recovery action is idempotent, when you go into the recovering state, just blindly fire off the recovery action every x seconds until you either get confirmation of resolution, or after y seconds give up and alert the humans that the problem might not be resolved. As far as I know, my 4-state FSM solution is still in production years later. I'm sure the author of the original felt a 4-state finite state machine was "the hardest way to write it."
In a third case, we have a pretty slick internal publish-subscribe system, but the error handling is just level-based: the subscriber provides a callback taking a boolean that indicates if the publisher has just gone from "bad" to "okay" (true) or "okay" to "bad" (false). Publishers have an upper time limit of inactivity after which they'll publish out a size zero message, so if a subscriber doesn't get any messages in that maximum idle period plus some configurable leeway, then the subscriber needs to assume the publisher has died and go into error mitigation/recovery/alerting logic. It's a pretty simple two-state FSM. The start state is the "bad" state. Every message results in the current time being recorded as the latest timestamp, and if the current state is "bad", transition to the "ok" state and pass true to the health status callback. If there's not an existing timer, create one for transitioning back to a "bad" state. When the timer goes off, check the latest recorded timestamp, and see if you really should transition to a "bad" state and call the health status callback with false. Otherwise, calculate the next timeout based on the latest heartbeat and reset the timer. The problem is that it starts out in the "bad" state, so in order to handle the case of publishers being dead at subscription time, all subscribers need to implement their own timer logic, and a lot of subscribers either don't try to handle the case or handle it incorrectly. I spent a while trying to convince the main developer for the pub-sub system to switch to a tristate FSM: start, bad, and ok. If you use 100 years for the default time to transition from the start state to the bad state, you'll get backward-compatible behavior for subscribers that just assume their first health status callback must be their initial notification that the publisher is live. The other state transitions were all really easy to work out. I sent him an email with a pretty state transition table showing all 4 possible state transiions, what triggered them, and which transitions triggered which health status callbacks. It's really dead simple: 3 states, 4 transitions, and it greatly simplified code on the subscriber side and stopped forcing all subscribers to implement their own poor solutions, and it was 100% backward compatible if default parameters were used. He kept on pushing for various ad-hoc solutions with more implicit states and state transitions because his gut feeling solution was easier for him than thinking in terms of a 3-state finite state machine. We went through a couple back-and-forths with me pointing out flaws in his ad-hoc proposals, and him not pointing out any flaws in my FSM, but just complaining that it was "complex". But, he didn't really mean "complex", he meant "hard"[0] because he wasn't accustomed to thinking in terms of state machines. With the extra corner cases and implicit states in his ad-hoc proposals, his solutions were more complex by an objective complexity metric. But, I'm sure he'd complain that my 3-state, 4-transition state machine was writing it "the hardest way."
I also strongly prefer to put throttles with very high limits in cases where we don't think throttles will ever be necessary. When the network admins are yelling at you that you're killing the network is no time to have to code up a throttle instead of just changing a configuration. I've had people argue that putting in throttling logic is too complicated. When some middlewear daemon got absurdly slow, I've also had to tell those same people "The middlewear admins are screaming. If the middlewear daemon's memory usage hits 3.75 GB, we need to kill your programs to keep the middlewear from falling over." Sometimes a colleague complaining about complexity is really trying to simplify things to a dangerous degree.
I think of Rich Hickey [1]: helping others to understand the code faster by identifying and removing most of the accidental complexity.
⬐ abdababThis reminds me of a talk of Linus Torvalds. From this perspective, mastery can be seen as an acquired taste that came after doing a large volume of work.⬐ rramadassCan you please link the talk?⬐ abdababIt’s this one: https://www.ted.com/talks/linus_torvalds_the_mind_behind_lin.... The code he referred is here: https://github.com/mkirchner/linked-list-good-taste⬐ rramadassAh; i had seen the TED talk earlier though i had not looked at the code example in detail.Thanks for the links.
I'm a bit torn on the hooks feature since it seems like a great example of something that's easy but not simple [1], as well as going against React's prior principle of minimizing the API [2].I'm glad the article also shows how to use the more traditional API as well, even if it is a bit more verbose.
[1]: https://www.infoq.com/presentations/Simple-Made-Easy/ [2]: https://www.youtube.com/watch?v=4anAwXYqLG8
⬐ bern4444I disagree that hooks increase the API surface. They decrease the React API.Before hooks, if you wanted a stateful component you had to use class components with all of their specific methods (didMount, didUpdate, shouldUpdate, render etc).
Hooks allow functional components to have state, and a functional component in and of itself has an even smaller API than the class. The React API vastly decreases. A single hook, useEffect, replaces at least 3 methods (didMount, didUpdate, willUnmount) that previously had to written out separately in class components. Each of those methods had to contain logic for ALL your state and side effects so they could very easily grow in scope and be responsible for handling many things.
Now each individual concern can be packaged up in its own useEffect call. If I have state that is relevant to the useEffect call, than I just build my own custom hook that binds the stateful data with the useEffect.
Because hooks are just functions built up from other hooks, I'm no longer constrained by the React API (its effectively gone) and I can so much more easily the abstractions I need that can be shared across components.
No, that is not my argument. I'm sorry if I didn't explain myself well enough for everyone to understand.My point is that "readability" is composed by many factors, not just one. What is "readable" to some will not be "readable" by others. It depends.
For someone who knows Fortran, learning a Fortran-like language is easy (like C or JS). For someone who knows Common Lisp, Clojure is easy. But for someone who knows Fortran, Clojure is less familiar, hence the code will, on a glance, look less "readable".
The other factor is if something is "simple" by itself.
Most of this view comes from Rich Hickey, who wrote Clojure. He discusses "readability" or "simplicity" rather, in his talk "Simple Made Easy". If you haven't seen it before, do yourself a favor and watch it: https://www.infoq.com/presentations/Simple-Made-Easy/
He'll explain it much better, and with further points, much better than I ever can.
this is a good example of a "simple versus easy" trade off [1] , i.e. this is something that is easier to get started at some expense of simplicity: it is over-complicated & hides complexity behind a simple interface, but not in a way that is reliable - so eventually things will break and then you'll be strictly more confused than if you did things in a less easy but simpler way - learning a bit about dependency management & setting up a reproducible environment for running your python script/app.that said, it is an amusing hack to run the virtualenv'd python in a subprocess and then extract the environment vars and inject them into the already running python process.
some of the code could be cleaned up a bit -- e.g. it could be using https://docs.python.org/3/library/tempfile.html#tempfile.Tem... to just ask for a uniquely named temp dir, some of the subprocess invocations dont appear to have error handling, etc.
for my python hobby project these days i only depend upon packages i can install using apt in debian stable. containers for isolation help too.
Complexity.https://www.infoq.com/presentations/Simple-Made-Easy/
The goal of class based OOP is extension. When something is extended you then have the original and an extended derivative. What was one is now two, or more. That might be easy, but it certainly is complex. Complexity is to make many.
I prefer simplicity and predictability.
⬐ colesantiagowhat would you recommend instead?⬐ non-entityI take it you're unemployed then?⬐ austincheneyI’ve never had trouble finding work as a senior software engineer, but currently I’ve managed to escape the nonsense.I have found from working in Java heavy industries that people most reliant on OOP tend be school educated developers with little or no capacity for self education. These tend to be the developers most concerned with job security. Very few (almost none) self-taught developers I’ve known openly embrace OOP as their preferred paradigm.
High insecurity among software developers is why I’ve grown to dislike writing software in the corporate world and why I was happy to accept a management opportunity doing something unrelated.
⬐ dgb23All of the Rich Hickey talks I watched (there are many!) are insightful and entertaining. He manages to talk about technical things on a abstract, sometimes philosophical level. I even re-watched some talks after a couple of years and got something new out of them.One of the most entertaining ones I watched was "Spec-ulation". It is less general than some of the more shared/cited ones but really funny.
⬐ leetrout⬐ milesvpAnyone else interested it is available at https://www.youtube.com/watch?v=oyLBGkS5ICkThis talk had a profound effect on how I think about complexity, and taught me not to conflate easy and simple, 2 words in english that are often treated as synonyms. It really opened my eyes to how much tooling we use as devs (particularly in ops) that hides much of the complexity of a system. I’m much more dubious now whenever a tool comes around that makes X easier, and look for any added costs to complexity to see if there’s a hidden tradeoff.I highly recommend giving the talk a listen to.
⬐ 1penny42centsThis talk turned an inflection point in my career. The physical metaphor of a braid and having that braid straightened out applies to so many areas of software. "Unbraidedness" is a very useful (albeit informal) measure of quality for me. It helps me detect when something's not right, as well as hinting how I can help straighten it out.⬐ thereticent⬐ tdrgabiEven the informal concept is useful, but I suspect it could be formalized. I'd love to hear from a theoretical CS person about that notion.I see this talk given as an example of best talks. I watched it twice. I'm obviously in a minority here, but I don't get it. I hear just truisms. Like: "It's better to be rich and healthy than poor and sick." I know it's hard to summarize a talk in a few paragraphs, but what big point did you get out of it. Honest question, I'm genuinely interested.⬐ dgb23⬐ stonemetal12The core idea is to separate ease from simplicity and to talk about the implicit trade-offs of adhering to one over the other.He claims that certain (often popular) tools and practices adhere to ease rather than simplicity, which introduces accidental complexity. And he introduces term „to complect“ which is now widely used in the Clojure community.
Many of the concepts and comparisons he talks about can be found in the design of Clojure and Datomic.
⬐ dvnguyen⬐ Ace17What is simplicity and how it differs from ease? I haven’t got a chance watching the talk yet.⬐ dgb23Simplicity is described as being "disentangled" or the opposite of complexity.I personally often picture complexity as a graph of nodes and edges:
- The more edges you add, the more complex the thing it describes.
- The more rules you can deduce about the graph (for example "it is a unidirectional circle-like") such as the flow of the edges, counting etc. the less complex it is.
The imagery in the talk describes it similar: Complexity is more knotted and interwoven. Simplicity is more straight-forward, clear and composable.
Ease is described as something being "near", also in the dimension of time. Something you already know or can learn/do quickly.
The talk goes on describing how simplicity requires up-front investment and time to achieve and also how ease and simplicity sometimes overlap and when they are at odds.
1) easiness is subjective, simplicity is objective.2) simple code is easy to read, but hard to write.
If you're a programmer, and you're not surrounded by people conflating both words, consider yourself lucky. What does a coworker really means by "I did the simplest possible thing" ?
⬐ tdrgabiOk. So it might be a language thing. Not being a native, easy and simple from pov of a customer is the same for me.For example, for me, statement 1 is false. Simplicity is also subjective
I am one of the people conflating the terms. Are they used from the devs pov? Like what's easiest for you (add one more parameter to this function or another special case handled with its) might make things more complicated.
From the customer pov simple or easy is the same, or?!
⬐ nekopaIt is a language thing, even for native speakers :) That is why he went to a lot of trouble to define each term in the beginning, and kept referring back to his opening definitions throughout the talk:Simple = One thing not 'mixed - linked - folded' with anything else. That's why he says it is objective - if you look at something and see it's mixed up with something else, it's not simple (in his terms, now it's complex - eg many things woven together)
Easy = Near to you. Near in as you know it already, or you have it already and so on.
His talk is for the dev pov, but even outside of dev, simple does not mean easy all the time.
For example, (and something I am struggling with right now) it is simple to lose weight - eat less calories than you burn each day. Simple.
But I can attest it is far from easy.
⬐ tdrgabiThank you for the reply. I'm starting to get it.Wow it has been close to a decade since then. Is there a simple made Easy 2? He presents a number of grandiose ideas, it would be interesting to see what he thinks he got right and what went off the rails.⬐ Scarbutt⬐ juliend2He indirectly recognized the importance of declaring the shape of data 6 years later by introducing spec, which to date still has big issues and screams "just use a proper statically typed language".⬐ dgb23⬐ wellpast> spec, which to date still has big issues and screams "just use a proper statically typed language"I think this statement is unfair.
I don't think there is a widely used statically typed language that is nearly as expressive and simple as spec. Also the opt-in nature of it retains the advantages of dynamic typing.
⬐ iLemmingThere's no "proper statically typed language." Every single statically typed language I tried, comes with certain drawbacks. However, I'd like to add - I do miss sometimes static types in dynamic langs, including Clojure. Bottom line - there are truly no silver bullets. That's why we keep inventing new programming languages and new paradigms. But of course, once we pick up one "religion," we feel compelled to yell at others: "you're doing it wrong!"⬐ lukashrbEverytime I read your name, you subtile spread some negativity :)Maybe Hickey just didn't prioritized "types" as high as some other ideas to spend his time on. And in my opinion he focused on the right things and achieved something really great.
As general advice stay positiv, focus on the things you like instead of telling everyone what you don't like, it's better for your mental health ;)
That’s precisely what this is, including what he got right &c — “10 Years of Clojure” https://youtu.be/2V1FtfBDsLUI wonder what he meant by "Rules" (compared to "Conditions"), in his table where he describes "Complexity" vs "Simplicity".Is it some kind of paradigm that exist in Clojure but not in procedural languages?
⬐ joncampbelldev⬐ pansa2I believe conditionals is referring to if statements (and their ilk, switch/case/cond etc). Rules is referring to rule systems and/or more generally declarative knowledge systems. Things like core.logic in clojure (or prolog, datalog and minikanren in the wider world).Stuff like this is not specific to clojure, however it would be harder to have an embedded rules system in your language if its not a lisp. You'd probably have have to resort to a string based DSL (something like drools in java).
Fantastic talk, covering the difference between “simple” and “easy”, and how (when you can’t have both) the former is preferable.I find it interesting that Python, despite being widely described as a simple language, takes the opposite approach. The language isn’t simple at all [0], it prefers to make things easy. This preference even appears (in the contrapositive) in the “Zen of Python”: “Complex is better than complicated.”
As a specific example, Python 3.7 introduced dataclasses, making them dependent on type hints when they could have been completely orthogonal. The language design ignored this talk’s advice against “complecting” features.
⬐ iLemminghttps://twitter.com/lxsameer/status/1273546170137300992> I wrote a #clojure program for logic A in 4 hours. I've been asked to rewrite it in #python because of some product requirements. It's been 3 days since i've started and still on the first 25% of it. Note: I'm using python for more than 13 years.
⬐ ScarbuttYeah, no way that's true if his python and clojure knowledge are at the same level. That tweet sounds like what you see on r/clojure all the time, a cult.⬐ lgesslerIt seems hard to say conclusively what is or isn't possible about differences in development time without knowing more about the problem domain. Since he mentions GIL in one of his tweets, it seems like his code must have involved concurrency, and Python and Clojure differ enough in this regard (to say the least...) that it seems believable that something that's easy in Clojure could be gut-wrenching in Python.⬐ iLemming> That tweet sounds like what you see on r/clojure all the time, a cult.Check any Clojure forum - clojureverse, clojurians slack, mailing-list. Talks from conferences. Clojure/conj , ClojureD, ClojureX, etc. Click around, check the profiles. Then you'd probably see that majority of Clojure users are not that young. Most of them come to Clojure after learning other, very often multiple programming languages. Many of them have tried all sorts of different tools before finally discovering Clojure.
You see it over and over again, people claiming that Python, and other popular PLs have little to offer in comparison to Clojure ecosystem. And your only explanation is "it's a cult"? Yeah, sure. Clojurists are just a bunch of losers who simply failed to learn Python. It is a pretty cool cult to be in, it is based on ideas endorsed by people like Guy Steele, Gerald Jay Sussman, Paul Graham, Matthias Felleisen, Brian Goetz, and many others.
⬐ praptakJust a language that isn't yet used widely in production. I remember when Python was like that, there is even a relevant xkcd strip: https://xkcd.com/353/Gosh, I remember when JAVA was like that!
⬐ fulafel⬐ iLemmingClojure is used in production a lot, a big majority of users report using it for work. There's been significant shift from from the enthusiast-dominated community days of 10 years ago.See the first graph at https://clojure.org/news/2020/02/20/state-of-clojure-2020 where you can see what portion of respondents have reported using it for work over the years.
⬐ iLemming> isn't yet used widely in productionWhat are you talking about? Walmart has built their receipt processing in Clojure. Apple uses it (afaik for payments processing). Cisco has built their entire security platform in Clojure - security.cisco.com. Funding Circle has built their peer-to-peer landing platform in Clojure. Nubank - the largest independent digital bank in the world and sixth-largest bank in Brazil been using Clojure extensively. There are many other companies very actively using Clojure. Pandora, CircleCI, Pitch, Guaranteed Rate, etc. It's even used at NASA.
It's a the third most popular JVM language after Java and Kotlin, and the most popular alt-js PL (if you don't consider Typescript as alt-js). It's the most popular language among PLs with a strong FP emphasis - it is more popular than Haskell, Elm, Idris, OCaml, Erlang, Elixir, F#, Purescript, and (recently) Scala.
Clojure is very ripe for the prime-time. The ecosystem is really nice. A lot more nicer than most other languages. It is an extremely productive tool. But of course skeptics be like: "but it's dyyying ...", "it ain't popular ...", "but all those parentheses ...", "it's a cult ...", etc.
After using a bunch of other programming languages professionally (for over fifteen years), I can confirm - Clojure is a cult. I am so stuck in it and have no desire to leave. Rich Hickey is a voodoo shaman or something. Don't you ever watch his talks and do not try Clojure! I have warned you!
Sadly it's a video/presentation, not an essay, but Simple Made Easy[1] is the single software argument that has made the most impact on me.___
⬐ breckenedgeI’ve been programming for a long time, watched this presentation several times, done a bunch of other research, and still don’t know if I understand what this presentation is about. I fear that I’ve tried to apply these simple-vs-complex principles and only made my code harder to understand. My understanding now is that complexity for every application has to live somewhere, that all the simple problems are already solved in some library (or should be), and that customers invariably request solutions to problems that require complexity by joining simple systems.⬐ nordsieck⬐ dimitar> I fear that I’ve tried to apply these simple-vs-complex principles and only made my code harder to understand. My understanding now is that complexity for every application has to live somewhere, that all the simple problems are already solved in some library (or should be), and that customers invariably request solutions to problems that require complexity by joining simple systems.Simplicity exists at every level in your program. It is in every choice that you make. Here's a quick example (in rust):
The closure is more complex than the function because it adds in the concept of environmental capture, even though it doesn't take advantage of it.fn f(i) -> i32 { i } // function let f = |i| -> i32 { i }; // closureThis isn't to say you should never pick the more complex option - sometimes there is a real benefit. But it should never be your default.
You are correct in your assessment that customers typically request solutions to complex problems. This is called "inherent complexity" - the world is a complex place and we need to find a way to live in it.
The ideal, however, is to avoid adding even more complexity - incidental complexity - on top of what is truly necessary to solve the problem.
⬐ KoshkinI think, the shift in programmer's perspective on where complexity should live is very much related to the idea of "the two styles in mathematics" described in this essay on the way Grothendieck preferred to deal with complexity in his work: http://www.landsburg.com/grothendieck/mclarty1.pdf.⬐ mac01021> still don’t know if I understand what this presentation is about1. The simplicity of a system or product is not the same as the ease with which it is built.
2. Most developers, most of the time, default to optimizing for ease when building a product even when it conflicts with simplicity
3. Simplicity is a good proxy for reliability, maintainability, and modifiability, so if you value those a lot then you should seek simplicity over programmer convenience (in the cases where they are at odds).
⬐ mumblemumbleI find the graph at the top of Sandi Metz's article "Breaking up the Behemoth" (https://sandimetz.com/blog/2017/9/13/breaking-up-the-behemot...) to be poignant.If you agree with her hypothesis, what it's basically saying is that a clean design tends to feel like much more work early on. And she goes on to suggest that early on, it's best to focus on ease, and extract a simpler design later, when you have a clearer grasp of the problem domain.
Personally, if I disagree, it's because I think her axes are wrong. It's not functionality vs. time, it's cumulative effort vs. functionality. Where that distinction matters is that her graph subtly implies that you'll keep working on the software at a more-or-less steady pace, indefinitely. This suggests that there will always be a point where it's time to stop and work out a simple design. If it's effort vs. functionality, on the other hand, that leaves open the possibility that the project will be abandoned or put into maintenance mode long before you hit that design payoff threshold.
(This would also imply that, as the maintainer of a programming language ecosystem and a database product that are meant to be used over and over again, Rich Hickey is looking at a different cost/benefit equation from those of us who are working on a bunch of smaller, limited-domain tools. My own hand-coded data structures are nowhere near as thoroughly engineered as Clojure's collections API, nor should they be.)
There is a transcript here: https://github.com/matthiasn/talk-transcripts/blob/master/Hi...⬐ bezmenov⬐ Cthulhu_Rich belongs to the small class of industry speakers who are both insightful and nondull. Do yourself a favour if you haven't and indulge in the full presentation.I still can't believe that I was actually there during that exact presentation but at the time it didn't have the impact on me that it seems to have had on HN as a whole. Maybe I should review it again, or maybe I'm just not smart enough / don't have the right mindset, IDK.⬐ mumblemumble⬐ jonjackyI think that the thing about that talk that struck a chord is that he took a bunch of things that people had been talking about quite a bit - functional vs oop, mutability, data storage, various clean code-type debates, etc. - and extracted a clear mental framework for thinking about all of them.⬐ twicRich Hickey seems to be a bit of a Necker cube. Some people i know and respect think he is a deep and powerful thinker. But to me his talks always seem like 90% stating the obvious, 10% unsupported assertions.⬐ mac01021If you find 90% of his statements to be obvious, maybe all that means is that you're a deep and powerful thinker too?⬐ chubotYeah, I think it depends on whether you're thinking about things from a SYSTEMS perspective or a CODE perspective.Hickey clearly thinks about things from a systems perspective, which takes a number of years to play out.
You need to live with your own decisions, over large codebases, for many years to get what he's talking about. On the other hand, in many programming jobs, you're incentivized to ship it, and throw it over the wall, let the ops people paper over your bad decisions, etc. (whether you actually do that is a different story of course)
Junior programmers also work with smaller pieces of code, where the issues relating to code are more relevant than issues related to systems.
By systems, I mean:
- Code composed of heterogeneous parts, most of which you don't control, and which are written at different times.
- Code written in different languages, and code that uses a major component you can't change, like a database (there's a funny anecdote regarding researchers and databases in the paper below)
- Code that evolves over long periods of time
As an example of the difference between code and systems, a lot of people objected to his "Maybe Not" talk. That's because they're thinking of it from the CODE perspective (which is valid, but not the whole picture).
What he says is true from a SYSTEMS perpective, and it's something that Google learned over a long period of time, maintaining large and heterogeneous systems.
https://lobste.rs/s/zdvg9y/maybe_not_rich_hickey
tl;dr Although protobufs are statically typed (as opposed to JSON), the presence of fields is checked AT RUNTIME, and this is the right choice. You can't atomically upgrade distributed systems. You can't extend your type system over the network, because the network is dynamic. Don't conflate shape and optional/required. Shape is global while optional/required is local.
If you don't get that then you probably haven't worked on nontrivial distributed systems. (I see a lot of toy distributed computing languages/frameworks which assume atomic upgrade).
-----
His recent History of Clojure paper is gold on programming language design: https://clojure.org/about/history
I read a bunch of the other ones. Bjarne's is very good as usual. But Hickey is probably the most lucid writer, and the ideas are important (even though I've never even used Clojure, because I don't use the JVM, which is central to the design).
⬐ kaioThat is the key: stating the obvious actually is hard and I think Rich does a beautiful job to translate the thoughts and feelings most programmer have into words. It actually gives a way to discuss and think about things (especially design and architecture) with others. I learned that there is no such thing as "common ground" or common knowledge magically and intuitively shared by all programmers. So if this already reflects your thoughts - even better.There is a transcript here:https://github.com/matthiasn/talk-transcripts/blob/master/Hi...
⬐ draw_downIt is a good one, but the way it gets applied drives me a bit batty sometimes. Hickey includes some concrete examples of simple vs complex, and there exist people who will extol this talk and then pick the choice from the complex column every time. Really wonder what they’re getting out of it.⬐ mercerI don't have a transcript link at hand, but as far as videos go, "Functional Core, Imperative Shell" / "Boundaries" by Gary Berhardt is also a must-see (or must-read, hopefully).⬐ rovoloHere's the video link:https://www.destroyallsoftware.com/screencasts/catalog/funct...
Unfortunately there's no transcript on the official video
> makes you a lot more familiar with itEssentially boiling down to the famous "easy vs simple" where something is "easy" if you're familiar with it and can draw conclusions via leveraging existing experience and "simple" is that it's maybe not familiar, but easier to become familiar with because it's not complex.
Blatantly stolen from Rich Hickey's "Simple Made Easy" talk: https://www.infoq.com/presentations/Simple-Made-Easy/
I don't like lisp, not code in lisp; not even a line.. and I have read TONS of lisp stuff.Why?
The #1 reason: The lisp people have a lot of cool things to teach.
One of the most obvious examples:
https://www.infoq.com/presentations/Simple-Made-Easy/
So, you can learn enough of Lisp or APL or oCalm or Haskell to tag along with somebody smart on the field (that use certain lang, maybe for very good reasons, maybe is just what he like) and understand stuff.
Most of the real gems are kind of easy to learn with the most basic understanding of a language.
---
A lot of times, is THAT kind of people that have the better insights of why certain lang matter.
Continue with the example of Rich Hickey:
https://dl.acm.org/doi/abs/10.1145/3386321
---
You can translate a lot of ideas from a lang to other, as the most basic and simply benefits.
Is just the case that certain langs fit the minds/goals/niches better, so is there where to look for better answers...
I agree with the notion.I find that a lot of less experienced devs I work with like to prioritize "ease of use" in API design over other things, such as testability, orthogonality, decoupledness, reversibility, etc. If an API is "easy to use" from a client perspective, they often deem it a good one. API ease of use is definitely important, but weighed against other constraints, which are more fuzzy and more about long-term maintainability. Sometimes making an API slightly harder to use (often requiring additional client knowledge about the domain before using it) is worth the trade-off against ease of use since it means it's easier to extend in the future.
It's definitely a skill to learn what helps long-term usability vs short term usability.
I often go back to Rich Hickey's talk about Simple Made Easy when thinking about this problem. https://www.infoq.com/presentations/Simple-Made-Easy/
⬐ umviIMO "public" facing APIs should always be easy to use and only require the minimum information from the user necessary. An example of an outstanding public API would be nlohmann's json library for C++[0].Whether that API is merely a wrapper for an internal API that is more testable (i.e. allows injection, etc.) or whatever is another matter.
⬐ allenuI think there can be debate on what is "minimum information". I'd also say "easy" for one developer may be challenging for another developer if the domain of the model is foreign to them.A lot of frameworks require up-front knowledge to work with. To some, that's not "easy", but it allows the client to do so much because what the framework is providing is not simple.
In other places, the API can be dead easy because what it's providing is so simple.
I think a good starting point is to integrate the principles described in the Simple Made Easy[1] & Hammock Driven Development[2]. These are overarching first principles that help in designing and writing code, but also in communication & team work.[1]: https://www.infoq.com/presentations/Simple-Made-Easy/ [2]: https://www.youtube.com/watch?v=f84n5oFoZBc
https://www.infoq.com/presentations/Simple-Made-Easy/Hickley argues that simple != easy. "Easy" is inherently subjective, and only tells us how easy something is for the actor attempting that thing; if you know more about a domain, things related to that domain become easier. If you knew how to tie knot A and I knew how to tie knot B, we would both find our respective knots easier. "Simple" is more objective, insofar as anything can be. We could judge the complexity of knots in a rope based on how many times the rope turns over on itself, and that complexity would not be dependant on your knowledge of particular knots. In principle we should be able to agree on which knot is more complex even if we still have an easier time tying the ones we are familiar with.
Of course you can mount an argument that simple is used as a synonym of easy, because it often is, but I like the idea of simple being the opposite of "complex" and "complex" meaning "many-folded" rather than "difficult."
⬐ dTalPerhaps, but it's a complete sidetrack. In the context of this discussion, "simple" was indeed being used as a shorthand for "accessible":> Finally, this is going to be more accessible to more users to Mozilla since now they are using Matrix.
> I disagree, IRC is as simple as it gets. This might discourage some people from joining.
⬐ Ajedi32Fair point, but in this case it's really easy that users want, not necessarily "simple". Going back to the points made earlier in this thread, IRC is a lot simpler than WhatsApp, but WhatsApp has a much larger user base because it's easier to use.
> [...] easy is confused with being simple [...]The first half of Rich Hickey's "Simple Made Easy" presentation does a great job of defining easy/hard and simple/complex axes and distinguishing them.
video: https://www.infoq.com/presentations/Simple-Made-Easy/
It has been discussed before on Hacker News:
So, my first answer is that you shouldn't have too, and if you do, you might not be writing proper Clojure code.The most fundamental concept in Clojure, from the famous Rich Hickey talk Simple Made Easy (https://www.infoq.com/presentations/Simple-Made-Easy/) is that your code should strive to be decomplected.
That means that your program should be made of parts that when modified do not break anything else. This, in turn, means you don't really ever need to refactor anything major.
In practice, this has held true for most of my code bases.
Now, my second answer, because sometimes there are some small refactors that may still be needed, or you might deal with a Clojure code base that wasn't properly decomplected, you would do it the same way you do in any dynamic language.
The two things that are trickier to refactor in Clojure are removing/renaming keys on maps/records, and changes to a function signature. For the latter, just going through the call-sites often suffice. The former doesn't have that great solutions for now. Unit tests and specs can help catch breakage quickly. Trying out things in the REPL can as well. I tend to perform a text search of the key to find everywhere it is used, and refactor those places. That's normally what worked best for me.
It helps a lot if you write your Clojure code in a way that limits how deep you pass maps around. Prefer functions which take their input as separate parameters. Prefer using destructuring without the `:as` directive. Most importantly, design your logic within itself, and so keep your entities top level.
⬐ hombre_fatalRefactoring involves unavoidable, heavy code changes due to any number of unforeseeable circumstances like a change in requirements that forces a bedrock reabstraction because your previous solution was written to a different specification.Maybe you want to add an archer class to your game that was melee-only and now your damage system needs to be reconsidered from scratch to be projectile-based instead of proximity-based. Maybe you're trying to move your 2D tile-based game into 3D gravity-based space and now your entire physics simulation has changed. Or you want to replace your AI enemies with networked multiplayer, lag compensation, and dead reckoning.
"Just write your code so you don't have to refactor it" is suggesting the impossible: that you somehow have zero unknowns from the moment you write your first line of code. A refactor that you can avoid upfront isn't a refactor nor what people are talking about when they bring up the challenges of refactoring.
Just chiming in because you seem to consider Clojure a great tool and want to spread the good word. But you're unintentionally damning it to suggest that Clojure's refactoring solution is to merely never incur significant change.
⬐ iLemming> Prefer functions which take their input as separate parameters.In practice, it's better to avoid positional arguments and extensively use maps and destructuring. Of course, there's a risk of not properly passing a key in the map, but in practice that doesn't happen too often. Besides - Spec, Orchestra, tests and linters help to mitigate that risk.
⬐ didibus> In practice, it's better to avoid positional arguments and extensively use maps and destructuringWe can agree to disagree I guess. In my experience, especially in the context of refactoring, extensive use of maps as arguments causes quite a lot of problems. Linters also do nothing for that.
Positional arguments have the benefit of being compile errors if called with wrong arity. I actually consider extensive use of maps a Clojure anti-pattern personally. Especially if you go with the style of having all your functions take a map and return a map. Now, sometimes, this is a great pattern, but one needs to be careful not to abuse it. Certain use case and scenarios benefit from this pattern, especially when the usage will be a clear data-flow of transforms over the map. If done too much though, all over the app, for everything, and especially when a function takes a map and passes it down the stack, I think it becomes an anti-pattern.
If you look at Clojure's core APIs for example, you'll see maps as arguments are only used for options. Performance is another consideration for this.
Doesn't mean you should always go positional, if you have a function taking too many arguments, or easy to mix up args, you probably want to go with named parameters instead.
⬐ iLemmingFor example if you have something like:And inside it calls a bunch of auxiliary functions where you pass either `student` or `age` depending on what those functions do, then someone says: "oh we need to also add an address", and have address verification in the midst of that pipeline. And instinctively programmer would add another positional argument. And to all auxiliary functions that require it. The problem with the positional arguments - they often lie, they're value depends on their position, both in the caller and in the callee.(study [student age] ,,,)It also makes it difficult to carry the data through functions in between. The only benefit that positional arguments offer is the wrong arity errors (like you noted). And yes, passing maps can cause problems, but both Joker and Kondo can catch those early, and Eastwood does that as well, although it is painfully slow. With Orchestra and properly Spec'ed functions - the missing or wrong key would fail even before you save the file. I don't even remember the last time we had a production bug due to a missing key in a map args.
But of course it all depends on what you're trying to do. I personally use positional arguments, but I try not to add more that two.
⬐ didibusThat's a bit of a different scenario then I was thinking.In your case, you're defining a domain entity, and a function which interacts on it.
Domain entities should definitely be modeled as maps, I agree there, and probably have an accompanying spec.
That said, still, I feel the function should make it clear what subset of the entity it actually needs to operate over. That can be a doc-string, though ideally I'd prefer it is either destructuring and not using the `:as` directive, or it is exposing a function spec with an input that specifies the exact keys it's using.
Also, I wouldn't want this function to pass down the entity further. Like if study needs keys a,b but it then calls pass-exam which also needs c and d. This gets confusing fast, and hard to refactor. Because now the scope of study grows ever larger, and you can't easily tell if it needs a student with key/value c and d to be present or not.
But still, I feel since it's called "study", it feels like a side-effecting function. And I don't like those operating over domain entities. So I personally would probably use positional args or named parameters and wouldn't actually take the entity as input. So if study needs a student-id and an age, I'd just have it take that as input.
For non side-effecting fns, I'd have them take the entity and return a modified entity.
That's just my personal preference. I like to limit entity coupling. So things that don't strictly transform an entity and nothing else I generally don't have them take the entity as input, but instead specify what values they need to do whatever else they are doing. This means when I modify the entity, I have very little code to refactor, since almost nothing depends on the shape and structure of the entity.
The article mentions “Simple is better than complex”, but not the next line of the Zen of Python, which I think tells us a lot about that language’s philosophy: “Complex is better than complicated”.Looking closely, that line says “(not simple) is better than (not easy)”, or more clearly, “easy is better than simple”. Python definitely lives up to this - it’s easy to get started with, but if you look deeply it’s a very complex language.
Go’s philosophy is probably the opposite - that simple is better than easy. This is similar to the philosophy of Clojure, as explained by Rich Hickey in “Simple Made Easy” [0].
⬐ masklinnDon't forget this absolute banger:> Obviously Go chose a different path. Go programmers believe that robust programs are composed from pieces that handle the failure cases before they handle the happy path.
A function which only returns an error can have its result ignored without any warning.
⬐ throwaway894345⬐ bjornjajajajaI don’t think that paragraph was referencing compiler guarantees.⬐ coldtea⬐ ProZsoltIt should refer to them or address them.Since, given this, Go is no better than a language with unchecked expressions nobody handles...
⬐ stousetThere’s other reasons too! I’ve written the following:… and then went on to use `v`. Thanks to `v`s zero value being legitimate (and not nil like a pointer would be), the program continues on as if everything is okay. In case you didn’t catch it, I forgot the `return`.if v, err = func(); err != nil { nil, err }Rust takes a much better approach with Result, where the return value is either `Ok(v)` or `Err(e)`, and there’s no way to access a meaningless value for the other possibility.
⬐ earthboundkidYour example doesn't compile: https://play.golang.org/p/KQwXqTZHSPFGo doesn't allow values to just be referenced without having some use, e.g., JavaScript's `"use strict";` hack could not be done.
In general, I have never seen a bug caused by accidentally ignoring an error. It's a theoretical concern, but not a real world problem.
⬐ stouset⬐ coldteaDon’t know what to tell you, I have personally made this mistake and not had this caught by the compiler. I haven’t used go in several years at this point, so it’s entirely possible this is a newly-caught scenario by the compiler.Regardless, the fundamental point stands. Using tuples to return “meaningless” values alongside errors allows developers to mistakenly use those meaningless values.
⬐ throwaway894345I do wish Go would adopt sum types, but in practice errors like you describe are vanishingly rare. It’s mostly a theoretical problem.Yeah, and this is so simple a change (compiler wise) and far more stronger a guarantee I don't see why Go didn't implement it...At least then errors as return values would be solid.
Of course now they make programmers do all the extra error wrapping thing in 1.14 to pass "richer" errors...
⬐ pm90Eh. It’s verbose but I like it. It makes me think about the code a bit when I have to write a descriptive error wrap. Kind of annoying I guess... I haven’t written ultra large go codebases though so ymmv.⬐ coldtea>It’s verbose but I like it. It makes me think about the code a bit when I have to write a descriptive error wrap.Having the compiler force you, as is my suggestion, would make you think even more -- or not be able not to think and skip the error check or miss it.
⬐ dangTotally off topic: if it isn't a bother, would you mind emailing [email protected]? I would like to send you a repost invite.When you write your program you have to explicitly ignore the error. Ignoring it is a way to handle it.⬐ closeparenAny serious Go shop would have errcheck as one of the linters in CI.⬐ masklinn⬐ tomluApparently linters are bad and that’s why go literally refuses to compile if you have unused imports. But crap like this? No problem, flies right through.⬐ VendanLinters aren't bad (Go basically has one as `go vet` that checks for all kinds of "this is probably wrong", like the common "closing over a loop variable")Warnings are bad, specifically when the warning is unambiguous (importing a package you aren't using is always wrong, though it makes debugging frustrating at times) The idea is that warnings that don't "stop" the build generally get ignored. Build most non-trivial C++ projects and count how many warnings flow past the top of your screen for an example of what they were trying to prevent.
⬐ earthboundkidWhat drives people crazy about Go is the laser-like focus of the designers on real world problems over theoretical problems.Theoretical problem: Someone might mutate a variable intend to be constant.
Go designers: Then put a comment saying not to do that.
Real problem: People ignore compiler warnings.
Go designers: Then eliminate warnings.
Real problem: Exceptions can happen anywhere and often go unchecked.
Go designers: Then call exceptions "panics" and encourage people not to use them.
Theoretical problem: Someone might ignore an error return value.
Go designers: Let paranoid people write linters.
Etc. etc.
⬐ stousetI can emphatically confirm that this is not what annoys me about go, and what does annoy me are the real-world issues I ran into it through multiple pieces of production software developed with multiple teams of skill levels ranging from intern to senior.⬐ earthboundkid⬐ VendanCan you link to a write up? I’d like to read what went wrong.⬐ stousetIt’s been at least three years so it’s difficult to do a real write-up. In a lot of ways it was death by a thousand cuts. But some things off the top of my head:Having to rewrite or copy/paste data structures for different types, given the lack of generics. As I understand it, even Google now has tools that generate go source from “generic” templates. This is absurd.
Defer to free resources (e.g., closing files) is a terrible construct because it requires you to remember to do this. You have lambdas! Use them so that the APIs can automatically free resources for you, like Ruby and Rust. It’s insanely hard to debug these kinds of issues because you run out of file descriptors and now you have to audit every open to ensure matching closes.
Casting to interface{}. The type system is so anemic that you have to resort to switching over this, and now you lose type safety. Combine this with the compiler not caring about exhaustive switch statements. And combine this with interfaces being implemented implicitly, and it’s a mine field for bugs.
I literally had a go maintainer waffle on adding support to calculate SSH key fingerprints because “users can just read the RFC and do it themselves if needed”. This is an indefensible perspective on software development.
Despite “making concurrency easy”, having to implement concurrency patterns by hand for your different use-cases is nuts. I have lots of feelings here, most are summed up by https://gist.github.com/kachayev/21e7fe149bc5ae0bd878
Tulpe returns feel like they were bolted on to the language. If I want to write a function that does nothing more than double the return value of a function that might error (insert your own trivial manipulation here), I have to pull out the boilerplate error handling stanza when all I want to do is pass errors up the stack.
This is the 5% that I remembered off the top of my head years later. All in all, the design of go as a “simple” language just means that my code has to be more complex.
Interestingly, the one time I introduced someone to Go without really "realizing" it (during a coding interview, got to pick the language I used), his first comment was actually that he liked how explict the error return was. (strconv.Atoi, to be specific). That pretty much sums it all up to me: `if err != nil` seems like annoying boilerplate, but then when you see stuff that's not just doing `return err` inside that conditional, you realize that it can actually be a benefit.⬐ masklinnYes, laser focus on real-world problems like unused variables (don't matter) or unused imports (matter even less).> Theoretical problem: Someone might mutate a variable intend to be constant.
> Go designers: Then put a comment saying not to do that.
One can only wonder why they even bothered writing a compiler when comments can solve it all.
> Real problem: Exceptions can happen anywhere and often go unchecked.
> Go designers: Then call exceptions "panics" and encourage people not to use them.
> Theoretical problem: Someone might ignore an error return value.
> Go designers: Let paranoid people write linters.
Because that way it's even easier to ignore than exceptions, and that's… good apparently?
Also create `append` where not using the return value just right (with no help from the compiler but that's OK because comments are where it's at) doesn't just create a bug in your program it can create two or more, what relentlessly efficient focus on real-world problems.
> A function which only returns an error can have its result ignored without any warning.It should perhaps be an error to not assign an error to a variable. Internally, Google has linters that enforce this.
It would be nice to have “elegance” brought into the picture too. Code is an art as well!⬐ aequitas⬐ todotaskUnless your building a user facing frontend please keep art out of your code. Just like a bridge internal's concrete structure doesn't need decoration so does your backend's plumbing. Writing elegant and artful code that is hard to understand and debug does not make you a clever developer. Keep that stuff for the demo-scene or 99-bottles-of-beer. Go is an language for engineering software, not crafting.⬐ rat9988I have seen uncharitable interpretations, but this one is one one of the worst.⬐ fastballWhat exactly are you picturing when someone says "elegant" or "artful" code?To me, elegant code is DRY code. Elegant code is code with useful abstractions where needed, and no abstractions where they just complicate matters. Code that is succinct yet clearly communicates its purpose.
From the sounds of it, you have an entirely different conception of what elegant code looks like.
⬐ crazyjncsu> Writing elegant and artful code that is hard to understand and debug does not make you a clever developerThe whole purpose, to me, of artfulness in code is to take unartful, hard to understand code and make it simple. What other objective is there?
⬐ bjornjajajajaHonestly if a solution is too hard to understand and debug then it is not elegant. Elegance is turning a complicated solution into an easier-understood one. Clever solutions could be elegant but they could also be shortcuts that are confusing and cause more harm than good. There’s definitely a difference.⬐ Koshkin> Unless your building a user facing frontend please keep art out of your code.Honestly, I had rather art be kept out of the user facing frontend. (Computer programming, on the other hand, is considered art by some computer scientists.)
⬐ tpmx(I don't necessarily disagree, but...)It's probably changed a lot since, but at least back in the 90s demo-scene code was absolutely 100% written for the result alone, even perhaps when it should perhaps have been say 75% for the sake of reusability. Imagine "decent" 90s game code quality, then dial the qualitynotch down a bit, since it will only have to work once on a well-defined machine anway.
I'm long since tuned-out. I do seem to remember Farbrausch making some waves when they started applying the concept of reusability and structure to their work in the early 2000s.
⬐ njharman> Writing elegant and artful code that is hard to understandYou do not know the meaning of elegant. At least in context of programming and maths.
⬐ skywhopperYou have a depressingly narrow view of what "art" can mean.⬐ gtf21This seems to have totally missed the first half of the comment to which you replied: _elegance_ certainly has a place in programming, just as it does in mathematics and many other disciplines. Things that are elegant are often difficult to conceive, but easy to understand being simpler solutions to a problem than something inelegant.I just read Eric update quite recent on CSP. https://gitlab.com/esr/reposurgeon/-/blob/master/GoNotes.ado..."Translation from Python, which is a dreadful language to try to do concurrency in due to its global interpreter lock, really brought home to me how unobtrusively brilliant the Go implementation of Communicating Sequential Processes is. The primitives are right and the integration with the rest of the language is wonderfully seamless. The Go port of reposurgeon got some very large speedups at an incremental-complexity cost that I found to be astonishingly low. I am impressed both by the power of the CSP part of the design and the extreme simplicity and non-fussiness of the interface it presents. I hope it will become a model for how concurrency is managed in future languages."
⬐ cannabis_sam> Go community’s practice for grounding language enhancement requests not in it-would-be-nice-to-have abstractions but rather in a description of real-world problems.jfc, the arrogance of this asshole. Seems like a decent fit for Go though, considering that language’s history of ignoring PL research..
I mean, Go is awesome for containers, and it’s awesome if you have a lot of junior devs and a decent amount of churn.
But the amount of anti-intellectualism by big shots in the community is seriously depressing.
⬐ throwaway894345⬐ d0mineESR might be a lot of things, but he’s not a junior dev by any standard. And experience reports are pretty consistent across the experience gradient—Go is useful for solving real world problems, and often the very abstract languages fail to do so (often especially those languages beloved by intellectuals). You can challenge the qualifications of the reporters with respect to their own experiences if you like, but that seems like a silly thing to do.If PLT can’t produce languages that practitioners find useful, then PLT is at fault, not practitioners.
EDIT: Rereading my last paragraph, "PLT is at fault" sounds harsher than I intended it to. Mostly it just sounds like PLT is based on a model of software development practice that doesn't fit well with the real world. The model performs poorly, but PLT supporters like the parent commenter are (implicitly or explicitly) blaming contemporary software development practice for the mismatch.
⬐ cannabis_samI never said esr was a junior dev, and he’s obviously not :)>“Go is useful for solving real world problems”
People repeat this like a mantra (you also hear similar from rich hickey’s most fervent acolytes in the clojure community), and I can’t for the world understand what it means...
I mean fucking BASIC can solve real world problems... I’ve spent ten years writing java and php to great success, but I'm still happy to never write in those languages again.
I even adore Elm, despite its annoying lack of type classes, but I respect Evan’s goal of avoiding complexity in the language. That argument holds up a lot better than That Rob Pike’s argument on types:
“ Early in the rollout of Go I was told by someone that he could not imagine working in a language without generic types. As I have reported elsewhere, I found that an odd remark.
To be fair he was probably saying in his own way that he really liked what the STL does for him in C++. For the purpose of argument, though, let's take his claim at face value.
What it says is that he finds writing containers like lists of ints and maps of strings an unbearable burden. I find that an odd claim. I spend very little of my programming time struggling with those issues, even in languages without generic types.
But more important, what it says is that types are the way to lift that burden. Types. Not polymorphic functions or language primitives or helpers of other kinds, but types.
That's the detail that sticks with me.
Programmers who come to Go from C++ and Java miss the idea of programming with types, particularly inheritance and subclassing and all that. Perhaps I'm a philistine about types but I've never found that model particularly expressive.
My late friend Alain Fournier once told me that he considered the lowest form of academic work to be taxonomy. And you know what? Type hierarchies are just taxonomy. You need to decide what piece goes in what box, every type's parent, whether A inherits from B or B from A. Is a sortable array an array that sorts or a sorter represented by an array? If you believe that types address all design issues you must make that decision.
I believe that's a preposterous way to think about programming. What matters isn't the ancestor relations between things but what they can do for you.”
It’s just your average, obvious complaint about the inflexibility of class hierarchies in OOP, with a slight misdirection at the beginning when he mentions generic types (aka parametric polymorphism) but for some reason that’s an argument against types?! He mentions polymorphic functions, as if they can’t be typed???
I mean I made the same mistake after three semesters of java at uni, but one semester of c/c++/python made me realize there was more to programming and I eventually discovered type theory, which makes Rob Pike’s claims seem odd at best.
For me personally (and thus anecdotally) PLT has been a boon in most aspects, even though I have to deal with imperative or object-oriented languages from time to time. it’s just such a drag...
⬐ throwaway894345⬐ clktmr> I can’t for the world understand what it means...It means Go performs well on real world projects. People feel productive, the language, tooling, and ecosystem get out of the way. You (and most PLT advocates I've encountered) seem to be evaluating languages on their inputs/features (presumably because you believe axiomatically that certain features--e.g., type systems--have a huge effect on the success or failure of a given software project) while the "useful for real world problems" view is about evaluating languages on their outputs. The latter view is harder to measure objectively, but it accounts for everything (e.g., syntax, type system, tooling, performance, ecosystem, etc) in correct proportion (no axiomatic beliefs).
Many PLT proponents generally seem to struggle with the notion that languages are successful when their model predicts that they shouldn't be. For example, many PLT proponents believe type systems strongly predict the success of a language, yet languages with very sophisticated type systems which are much admired by PLT proponents do poorly in the real world and languages with very flat-footed type systems (e.g., Go) do relatively well.
Either the qualitative data about these languages are wrong (e.g., contrary to the qualitative data, Haskell actually makes for more productive software development on balance than Go), or these PLT proponents' whitebox model is wrong. My money is on the qualitative data.
⬐ cannabis_sam> You (and most PLT advocates I've encountered) seem to be evaluating languages on their inputs/features (presumably because you believe axiomatically that certain features--e.g., type systems--have a huge effect on the success or failure of a given software project) while the "useful for real world problems" view is about evaluating languages on their outputs.I don’t, so please keep you assumptions to yourself and don’t put words to in my mouth.
> in correct proportion (no axiomatic beliefs).
What is this based on?
⬐ throwaway894345> I don’t, so please keep you assumptions to yourself and don’t put words to in my mouth.I'm hardly putting words in your mouth. You were expressing more-or-less exactly this sentiment in your previous post.
> What is this based on?
It follows by definition of output-based or blackbox evaluation. Evaluating the output of a system implies that you are evaluating inputs in proportion to their contribution to the output.
⬐ cannabis_sam> I'm hardly putting words in your mouth. You were expressing more-or-less exactly this sentiment in your previous post.Trust me, I wasn’t.
> It follows by definition of output-based or blackbox evaluation. Evaluating the output of a system implies that you are evaluating inputs in proportion to their contribution to the output.
I like this! It’s like pure functions/total programming, only not rigorously defined in the slightest.
It’s not an answer to my question though, HOW do you know that the results of your output/blackbox testing is correct?
> often especially those languages beloved by intellectuals*self-proclaimed intellectuals
To be fair, it also took me years to realize how programming as tought in academia is out of touch with reality.
> dreadful language to try to do concurrency in due to its global interpreter lockdon't take it too seriously. GIL has its issues and it would be nice to see it gone but "dreadful" is an overstatement. Python wouldn't be so widely used as a back-end language otherwise. Concurrency is not parallelism.
On "it [Go] will become a model for how concurrency is managed in future languages." -- it is not as clear cut as it appears at the first glance: "Notes on structured concurrency, or: Go statement considered harmful" https://vorpus.org/blog/notes-on-structured-concurrency-or-g...
⬐ Vendangoroutines (and the go keyword) are the primitive, just like async is the primitive for python. Something like golang.org/x/sync/errgroup gives Go the same kind of "nursery" concept and can be leveraged almost identically (modulo Go not having the "with" concept, but defer can play the same role)⬐ d0mine⬐ murphy214there is no doubt that a "nursery"-like construction can be implemented in Go in the same way like any language with "goto" can implement structured loops. The point is in constraining what can be done.There is a trade off: "goto" is powerful but it is likely to lead to a spaghetti code. "nursery" introduces constrains but makes it easier to deal with error handling/cleanup, back pressure issues such as https://lucumr.pocoo.org/2020/1/1/async-pressure/
Dreadful may be a little strong but anytime I've tried to implement something like asyncio for a non trivial piece of code it becomes pretty obtuse. (imo)⬐ fjpI’ve found asyncio to be a very simple model to understand, using the aio libs: aiohttp, aiopg, aiobotocore, etc.Basically just slap “async” or “await” in front of everything and understand that anytime there is a network connection being accessed, that method will release control of the main thread.
You just have to pay attention to where something might block the thread for any significant amount of time - heavy calculation or lengthy file IO
You can spawn a multitiude of async tasks on startup and have super basic “scheduling” by using asyncio.sleep with some jitter.
The only time I have seen the performance limits of a naive asyncio app reached was in an auth app that sat in front of every API request for the whole company, and even then it was an obscure DB connection pool management issue deep in psycopg2.
Surprised no one linked Simple Made Easy[0] yet.Around 30 min, Rich Hickey describes how the opposite of simple is complex, and mentions the etymology, "to braid together".
"It's bad. Don't do it."
⬐ icebrainingOf course, but it could also be said that we're just composing the scrapers with a common building block, which Hickey says it's good.
> Simple Made Easy by Rich Hickey
I disagree. I think C is simple, but not easy[0]. I actually see explicitness as a sign of simplicity. It makes things obvious. Folks always cite undefined behavior, but I can't recall a single instance over the past 12 years of this causing me a day-to-day problem. I'm sure it does bite people though, I just don't relate personally.
Advice someone gave me in a similar situation: coding requires Mise en Place like cooking. Mise en Place is setting everything up and prepping before you start cooking so everything is easy to access.In coding, this means thinking through how you're going to structure it, have answers for what pieces of code use service calls and what needs to be its own modules. Think about the data and what it looks like: what fields and names does this have? Does it require a set or list collection?
Following up on that train of thought watch the Simple Made Easy talk and really try to internalize what he means when he talks about design.
> Since each transform needs to perform vastly different image operations, using an enum in this case would’ve forced us to write one massive switch statement to handle each and every one of those operations — which would most likely become somewhat of a nightmare to maintain.I don't mean to pick on the author, but I've seen this line of reasoning a few times before. It's the same argument that has been used in the past to justify inheritance hierarchies in OOP languages. I used to believe it too. However, I don't think this is actually true. In fact, I'd argue the opposite: switch statements, if used well, are _extremely maintainable_. Even though a switch statement might handle many cases, it does not become more complex [1] by doing so. If we're concerned about the length of the individual cases, we can easily replace each one with a function call. Fundamentally, in the example from the article, we'd like to map a piece of data (the operation with its parameters) to some behavior (actually performing the operation). A switch statement is one of the simplest ways to do that.
⬐ flipgimbleWhat you describe is called the Expression Problem [1] in programming language design and there is no simple formulaic answer on which method is better. I think you have to consider many aspects of your code's current design and possible future evolution when deciding which approach to use. For example: do you expect to have more types of transforms, or more operations/method per type of transform? It also means you can't nitpick a limited tutorial for focusing on one approach vs. the other.Fortunately swift (as well as Rust or Kotlin) has excellent modern toolbox that includes protocol conformance and algebraic data types so you can use either one.
Keep in mind that swift protocols avoid many of the pitfalls of Java\C++ school of OOP design you might have seen before that can only express "is-a" relationships.
⬐ pjmlp⬐ m12kJava and C++ have no issues representing has-a relationships.The issue is developers not learning how to use their tools.
Agreed on all points. One of the main metrics I use to assess maintainability of code is 'how many places do I need to edit to make a change?' (within the same file or worse, in other files too), 'how easy is it to find those places?' and 'how easy is it to make a change in one of those places but overlook another needed one?' On pretty much all of those counts, a single switch statement will tend to beat an inheritance hierarchy.
> Simple != Easy> For some, simple would be more like Haskell, while for others bash (until they need to understand old code). Each eye of the beholder can argue either way.
Certainly simple != easy, but I think in the second part there "simple" should be replaced with "easy". Simple is objective, while easy is subjective [1]. Haskell may be easier for some as they've spent more time with it, similarly bash for others. However, their simplicity, i.e. how many concerns are intertwined, how much global context is required to reason about a program, can be more objectively analyzed.
> The article talks about simplifying, though is more about discipline, something many find hard to find motivation and incentives for in this age of instant gratification!
Indeed, it takes discipline to maintain simplicity. Simplicity is hard. Complexity is easy. "If I had more time to write, this letter would be shorter."
"Simple is often erroneously mistaken for easy. 'Easy' means 'to be at hand', 'to be approachable'. 'Simple' is the opposite of 'complex' which means 'being intertwined', 'being tied together'" - https://www.infoq.com/presentations/Simple-Made-Easy/
⬐ jolmgProblem: Finely chopping foodComplex and Easy: Stick blender with chopper attachment.
Simple and Hard: Knife and cutting board.
-
Problem: Making a drawing
Complex and Easy: Computer and printer
Simple and Hard: Paper and pencil
-
Problem: Sewing lots of clothes (perfect stitches)
Complex and Easy: Sewing machine
Simple and Hard: Thread and needle
-
Problem: Software
Complex and Easy: Graphical User Interface
Simple and Hard: Command-Line Interface
⬐ Ma8ee⬐ hzhou321In all your examples, the complexity is hidden in the underlying technology, which I think makes them less than ideal. Sewing with a sewing machine is usually both less complex and simpler than sewing by hand. If you count the complexity of the hardware and the operating system and compiler, nothing in development is simple.For me the dichotomy is better is better illustrated by: I need to create a new class that, with a few exceptions, does exactly what an existing class already does.
The easy way is to copy the existing class and make the small necessary changes in the copy. The simple way would be to refactor and put all the differences in delegates.
⬐ jolmg⬐ msla> both less complex and simplerDid you mean "easier"? Because complex and simpler are antonyms, so it seems kind of redundant to use both words.
> the complexity is hidden in the underlying technology
The complexity is there. Maybe not all get involved with it, but it's still there.
> Sewing with a sewing machine is usually [simpler] than sewing by hand
The technology is more complex. The operation is maybe on par, though I would think it's also more complex. I may be biased in that I've hand-stitched many times and I find it super-simple, but I'm still a bit intimidated at the prospect of learning the basic use of a sewing machine. For very basic hand-stitching, you just put the thread through the needle, and the needle through the clothes in some pattern. That's it. For the sewing machine, I guess you have to lead the thread through some parts of the machinery, select some stuff through the knobs, etc. I think there certainly is a need to know a bit on the construction and workings of the sewing machine to be able to fix issues that arise.
> If you count the complexity of the hardware and the operating system and compiler, nothing in development is simple.
Complex and simple are relative terms, after all. If you refer to the last example of CLI vs GUI, they both involve the OS and compiler, etc. so that cancels out and we can refer to one as simpler or more complex than the other just based on the differences. Now, if you compare software development to making a sandwich, then sure, nothing in software development is as simple as making a sandwich.
> The easy way is to copy the existing class and make the small necessary changes in the copy. The simple way would be to refactor and put all the differences in delegates.
I agree to that, and that also aligns with the examples I gave. The complexity is mainly in how the thing is constructed. Duplicated code adds complexity to how the program is constructed. When you want to make a change to the common code, you have to make the change twice, maybe with a few differences. That makes development of the program also more complex.
It's the same as a sewing machine, or a stick blender with chopper attachment. Their construction and maybe operation is more complex than their counterparts.
> Problem: Software> Complex and Easy: Graphical User Interface
> Simple and Hard: Command-Line Interface
GUIs are easy for the specific things the programmers made easy, and potentially impossible for everything else. The moment you want something the developers didn't put in the GUI, there's no recourse other than writing your own tool.
Command lines are harder to begin with, but modern command lines give you a gentler ramp up to writing your own tools.
⬐ jolmgSame is true with the other examples, I believe. Simpler tools tend to be the more versatile ones.I am yet to appreciate Rich Hickey's now famous "Simple Made Easy". While I agree with his points, I don't understand the significance of it. Simpler is easier than complex, right? Even the title said "simple-made-easy". What is the fuss about emphasizing "Simple is erroneously mistaken for easy"? They are not the same, but they are intimately related. Or is this an emphasis on relative vs absolute -- that relative simple can still be relatively not easy?I don't think I misunderstood Rich Hickey, and I don't think I disagree. But I don't understand why people quote the opening sentence and feel so significant for them? To me, that is just a click-bate.
⬐ tempguy9999⬐ ajdegol> Simpler is easier than complex, right?Well, no. Complexity has an obvious price but simplicity does too. You have to work for simplicity, even fight for it. Think of code; it just somehow becomes more complex. You have to work to pare it back to what's needed.
I can't think ATM of better examples (and you deserve some), but no, simplicity does not come easy.
A nice phrase I came across: "elegance is refusal".
⬐ hzhou321⬐ elliusUntil you find a good example, I challenge your understanding :)Similar to my response to another comment, I suspect there is a switching of subjects. It starts with a problem, and the subject is a solution to the problem. Simpler solution is easier to understand and manage. A more complex solution is more difficult. Is there a counter example?
Try not to switch out the subject here. For example, one may propose to use a library to solve the problem by calling `library.solve`. And then one may argue that the simplicity of the code is actually more difficult to manage as one need trouble shoot all the details/bugs/interfaces with the library. We should recognize that the library itself is not the same as the solution. The solution includes the calling the library and its details/bugs/interfaces/packaging/updating/synchronizing etc. And these elements interwine to make the complexity. So the solution itself using the library is not necessarily simple. It is difficult exactly because of the complexity.
As you can tell, I am essentially making the same opinion as Rich Hickey, which is `simple-made-easy`. And it is very far away from the click-bate opening statement of "simple is often erroneously mistaken for easy". A more correct sentence probably should be "simple is often erroneously labeled by partial".
EDIT: To clarify, I am not saying a solution using a library is more complex. It depends. With a library, the solution is layered and delegated. The entire solution is more complex and more difficult to understand -- if one is to understand every byte of it. However, the layering means not all complexity need to be understood for practical reasons. So with proper layering and a good judgement of practicality, the part of the complexity that you practically need manage may well be simpler (and easier) by using a library, or not. It depends.
⬐ tempguy9999I don't deny your right to challenge, but tight now I can't give an example. I've just gone through months of my posts looking for one particular post that might clarify but I can't find it. Not being able to search your own comments is frustrating. I'll have a muse overnight.sorry!
Found it (thanks google): https://news.ycombinator.com/item?id=20591621 Simplicity was staring me in the face, it took weeks to find it.
⬐ carapace( FWIW Algolia can search comments: https://hn.algolia.com/?dateRange=all&page=0&prefix=false&qu... )Simple is easier than complex the same way that exercise is easier than chronic obesity. If you have the discipline to do the obvious that's great, but it takes willpower to create or do the simple thing. Oftentimes it's easier or more expedient to do the lazier easy thing in the moment, but you pay for it down the road. For example: I notice I'm doing the same calculation twice on the front and back end of my application. The "simple" thing to do would typically be to extract that logic to one place so that you don't end up having to modify it in two/five/twelve places down the road. But I'm already halfway through writing it, and the simplification will involve some non-trivial refactoring, so I take the easy route and write the same logic twice. It's easy for now, but will be complex when I have to change it down the road.⬐ jackpirateModules are "simpler" than vectors because they have fewer axioms, but they are also much harder to understand. For example, not all modules have a basis, which can make them much harder to work with.For background on the math, see: https://math.stackexchange.com/questions/137442/a-module-wit...
⬐ F-0X⬐ chrisweeklyInteresting analogy, but it's a little off.The main reason modules are interesting is not as a generalisation of vector spaces, but because they are helpful in studying rings. Kernels of ring homomorphisms are ideals, which in general are not subrings, but they are modules - and of course every ring is a module over itself. So to study a ring R it pays off to instead study R-modules, since working with them is... you guessed it! Simpler.
⬐ hzhou321Good luck explaining "simpler" with modules and vectors :).Simple is defined as not to inter-wine. To understand an axiom is to understand how it "inter-wine" with other axioms to prove certain results. So fewer axioms necessarily results in more interwines, ie complex. I think here we are switching the subjects: from axiom itself to the results that we want to prove. If we focus on the simplicity of proving the results, the simplicity of axioms are irrelevant.
The way I see it, when there's already a lot of complexity inherent to the domain (eg, software design), it's nearly always much easier to add to the complexity than to find a way to reduce it.⬐ hzhou321⬐ SuoDuanDaoYour answer makes sense and is illuminating.It is not easy to keep it simple.
The problem here is not that "simple is not easy", it is rather "picking partial and sacrificing/neglecting whole". Since one is only part of a team and a part of the whole design/develop/use circle, the "whole" problem is not (necessarily) "my" problem, therefore it is easy to pick a simple and easy solution from "my" perspective. The "my" and "whole" can also be swapped with "now" and "future". "now" is here but "future" is uncertain.
⬐ chrisweeklyGood points!"Parts:whole"?
That's where "local complexity : global simplicity" tradeoffs come into play; well-defined boundaries (coherent interfaces) are key to striking the right balance.
"Now:future"?
Yeah, YAGNI (You Ain't Gonna Need It") and STTCPW (Simplest thing that could possibly work) are good rules of thumb.
Finally, as for "not my problem"?
IMHO (and IME, 21yrs in the industry), that's a dangerously myopic stance. Those who make the effort to expand their perspective beyond the scope of their immediate tasks and responsibilities are those whose skills, powers, value and influence show commensurate growth. By all means, be a good team player and do your (current) job to the best of your abilities, which includes efficiency and ergonomics and awareness of available shortcuts. But if you do this for too longbe aware of the compounding effects, not only on the larger system's technical debt, but also the limits this may be placing on your career.
My takeaway was that if we conflate the two, we tend to use familiar (easy) tools to solve our problems, but that learning a new tool (hard) could result in a simpler solution.E.G, passing something to a legacy program in a language I'm unfamiliar with from a program I wrote in a familiar language is easier than implementing my solution in the legacy language, but it's not simpler.
The 'relative vs absolute' seems like a heuristic to distinguish the two. Writing a solution in a different language is easier to me, but I can tell on an absolute level that there are more failure points to that approach.
⬐ hzhou321Thanks. I think I understand the background much better now. When we think easy, we always take the "my" and "now" perspective. When we think simple, we often take the wholesome point of view. Thus the need for differentiation.⬐ NoodleIncident⬐ zmmmmmI might be wrong, but I think the word you meant by "wholesome" is actually "holistic"⬐ hzhou321You are right, I just grabbed the words by the sound of it.A better word is subjective and objective. Easy is a subjective word, while simple is an objective one.
Nice explanation. Python is a great example of this IHMO. It is a real struggle to get the Python programmers on my team to use any other language than Python.Why? Because it's easy for them. But the solutions they create with it are highly suboptimal. They could be far more robust and expressed much more concisely and directly in other languages with more powerful type systems and better support for eg: functional concepts.
But they actually really think that because Python is easy for them, that it's "simple". It's not: it's incredibly complex.
⬐ SuoDuanDaoHaha, I was thinking of that as I wrote it. My first language was C++ back in the day, then I dabbled in various languages for a while, and finally really dove into Python because there was a project I couldn't figure out how to write any other way. If I had to work with one of the languages I learned earlier, my first instinct would now be to write the solution in Python and pass it to the legacy program. Perfect example of what the speaker is warning of.If you haven't seen this talk; watching it will make you a 10x better programmer. This is what I take for my definition of complex and it applies broadly in a very practical manner.⬐ heinrich5991⬐ nohuck13>watching it will make you a 10x better programmer.That sounds wrong. Can we drop this rhetoric?
⬐ Ma8ee⬐ simongrayIt's obviously hyperbole.⬐ radicalbyte⬐ thwartedIt needs to be rephrased into this:"Watching this video will make you into a developer who is respected 10x more by their peers."
⬐ coldteaWould it?⬐ radicalbyteNo it's hyperbole.However if you go from writing spaghetti code to something more structured (i.e. loosely coupled, however that is expressed in your language) then you're team mates will hate you less.
⬐ _jalWell, no, but it will make you 10x richer.⬐ Ma8ee⬐ criddellharharProbably not, but it's fun to think about.If respect is measured by an integer, going from level 2 to 20 is great. But if you have no respect, then gaining 10 times as much still leaves you at none.
If you are disrespected DON'T WATCH THE VIDEO unless you want to be disrespected more by a factor of 10!
What rhetoric? Are you confusing this with "the 10x programmer" meme?Claims of becoming a 10x better programmer aren't claims about making one a 10x programmer. The former is about relative self-improvement and motivationally hyperbolic; the latter is about relative comparison to others, is often used negatively to belittle, and is detrimentally hyperbolic.
⬐ kazagistarI would defensively be more hyperbolic and use a different number, just because 10x is tainted by stupid ideas in programming. But your intent was pretty clear to anyone paying attention... that's just a high bar sometimes.⬐ Dylan16807> motivationally hyperbolicIt's such a ridiculously high number that it ceases to be motivational.
Also: try out Clojure (... the programming language created by Rich Hickey based on this principle).⬐ pixelrevisionWas 100x for me. My boss unfortunately did not agree with me.⬐ ErikAugustI've measured between 2x - 3.5x for every 12 minutes of a Rich Hickey talk. What's even more staggering is this continues even for repeated viewings.The speaker is Clojure creator Rich Hickey, but the talk is about a mental model for thinking about complexity.Inherent complexity involves tradeoffs.
Incidental complexity you can fix for free.
"And because we can only juggle so many balls, you have to make a decision. How many of those balls do you want to be incidental complexity and how many do you want to be problem complexity?"
The article is about the former. I bet the latter dominates day-to-day line-of-business coding.
Highly recommend the talk, as other have said.
⬐ masswerkSimplicity is often a matter of perspective, a function of a certain perception of a complex subject and the set of expectations that go with this perception. There is no absolute in analysis and in modelling synthetic propositions from the atoms used by the particular analysis.(E.g., we may analyse and model an action in terms of verb-noun or of noun-verb, with major differences in what may be perceived as "simple" in the respective model.)
⬐ astrobe_⬐ nohuck13> Simplicity is often a matter of perspectiveComplexity was formally defined by Kolmogorov, using with Turing machines even. Hence, Simplicity is also objectively defined.
⬐ masswerkReferring to the above example of verb-noun vs noun-verb grammar: take for example the infinitive verb form. With the former (verb-noun) it's just the verb devoid of any context, simplicity in its purest, which is also, why and how it's listed in a lexicon. Looking at this from the noun-verb perspective, you've to construct a hypothetical minimal viable object, which will be also – as you want to keep things simple – the object every other object inherits from, the greatest common denominator of any objects that may appear in your system. By this, you arrived at the most crucial architectural questions of your system and its reach and purpose. While it's still about simple things, neither the task nor the definitions derived from the process will be simple at all. Nor is there a universally accepted simple answer, as a plurality of object oriented approaches may testify for. The question is on an entirely different scale and level for the two approaches. On the other hand, for a verb-noun approach, similar may appear for anything involving relations, which are already well defined in an object oriented approach. And, as you've arrived at these simple fundamentals of simplicity in your system, what may be simple or not in your systems will depend on the implicit contracts included in these definitions and how well they stand the test of time and varying use and purpose.Later in the talk, he draws a distinction between inherent complexity (the focus of the article) and incidental complexity (which you can fix without tradeoffs). Tradeoffs can be critically important, but the latter kind of complexity probably dominates my day-to-day life. I find this oddly encouraging, in a free-lunch sort of way."And because we can only juggle so many balls, you have to make a decision. How many of those balls do you want to be incidental complexity and how many do you want to be problem complexity?"
Watch the talk.
⬐ loquorOn a related note, the late Patrick Winston strongly states in his MIT AI Course that simple is not the same as trivial. Simplicity is powerful.Simple points may sound trivial and obvious, but simple things can add up to make something magnificent.
⬐ blondinwouldn't say simple is the opposite of complex though? especially when talking about software systems or other systems in general. what i am thinking is that some complex systems can be made of very simple components.the best example is our complex brain being made of simpler components working together. maybe the opposite of complex is chaotic? i don't know...
⬐ mnsc⬐ hinkley> maybe the opposite of complex is chaotic?Cynefin would agree!
⬐ cuddlecakeI imagine that a software system that is made of simple components can still be complex. So I'd still go for simple vs complex⬐ nkriscA very big object can be made of lots of small objects, but that doesn't mean big isn't the opposite of small.⬐ ajdegolSimple systems can indeed be made of complex components; however it is a measure of interconnectedness. The key concept is that we can only hold a finite amount of complexity in our heads at any one time, and so if we can minimise that we can be more efficient and effective.The analogy is a lego castle vs a wool castle. A lego brick is very simple and contained, and from this you can build wonderful structures; in addition if you wish to change out a portion it is easy to do because changing on part of the system (i.e. implementation) doesn't affect the rest so long as the contract between components is maintained.
Contrasting: should you pull on a thread in a wool castle it will affect other parts of the castle. A lot of software is like this, which makes it very hard to reason about.
⬐ roenxiAnd the Lego analogy works in particularly nicely considering just how much effort, precision and design work needs to go in to making the blocks simple [0]. This is a nice analogy for how keeping software components simple and making them interface cleanly is a difficult task.⬐ hyperpallium"Interconnectedness" is also a measure of resistence to hierarchical decomposition (or factoring ax+bx -> (a+b)x); irreducable complexity.One technique is redefining the problem, to smaller or bigger:
Work on only part of a problem, a subset, leaving something out. e.g. git's data model does not represent renames as first class constucts, enabling it to be disproportionately simpler.
Expand the problem, a superset, to integrate lower or higher level or associated parts that aren't usually included. Previously scattered commonalities may then appear, enabling decomposition.
I think it's important to note that 'simple' can be used as an epithet.⬐ username90They key takeaway that you should strive to be a simple person, not an easy person.⬐ leggomylibroI had a math teacher in primary school who used to shout with an exaggerated accent, "simple is not the same as easy!" She really wanted to drill the idea into our heads that just because you know exactly how to do something, doesn't mean that it will be quick or easy to accomplish.Like, for a schoolchild, long division. The rules are simple, but given big enough numbers you'll probably mess up at least once. And then the same thing turns out to be true with algebra, geometry, derivation/integration, and on. It's not a bad mantra.
⬐ amboo7https://arxiv.org/abs/0707.4166 is nice⬐ mumblemumble> I had a math teacher in primary school who used to shout with an exaggerated accent, "simple is not the same as easy!"I can imagine no more poetic description of the experience of reading Wolfram's A New Kind of Science.
⬐ paggle⬐ Ma8eeCan you elaborate?"It is straightforward to show that..." means that you could probably do it with your current knowledge, but it will take 6 dense pages, four false starts and about a week of focused work.⬐ andreareinaIf you were Feynman you'd even call it "elementary"https://mavenroundtable.io/originalpath/path-helpers/feynman...
⬐ hinkley'You' being personified here, rather than the general you.Straightforward tends to suggest we don't have to have a bunch of meetings about it, because the right person either has the knowledge or we know precisely where to get it.
⬐ Ma8ee⬐ MaxBarracloughIt depends on the context. I had the math professor lecturing her students in mind.Like the joke about writing math textbooks.Forgotten the proof? Not a problem. The proof of this is elementary and is left as an exercise for the reader.
⬐ bitwizeI used to joke that when a solution was known to exist the problem was "trivial"; when a solution was not known to exist it was "nontrivial". A problem that's bloody well impossible is "decidedly nontrivial".
I’d suggest you watch Rich’s talk “Simple made easy”. [1]It’s one of his main points that something like a language being “hard to approach” can be overcome by spending a little effort to learn it (as opposed to sticking with something like Kotlin just because its easy to pick up because it’s familiar). The benefits of learning the unfamiliar (in his case, he’s speaking specifically about Clojure) being that it allows you to write code that is much simpler to reason about.
I have no particular beef with Kotlin (or most any languages... right tool for the job and all), but I have lately become infatuated with Clojure and many of Rich’s viewpoints.
⬐ BoorishBearsEh, I've used languages that were "hard to approach", one of my favorites (Erlang) is one of those (I use quotations especially because learning all of Erlang's syntax takes about a day).This is a misapplication of the presentation really. It speaks to a level above selecting a language and is really about the design of systems.
Picking up Kotlin or Clojure is not "harder to approach" by virtue of what's provided in this context, it's harder because Clojure syntax uses parenthesis.
Like that's literally it.
Clojure with the same exact constructs represented with more C-like syntax would, at the level the presentation speaks to, allow the same level of simplicity.
I think a lot of developers feel "It looks funny" is not a fair critique of a useful tool, but just look at Erlang vs Elixr. I love Erlang, much more than I like Elixr, but Elixr gained mind share in large part because it's Ruby-like.
Cognitive overhead is lower working with a language that at least "looks like", what you're used to, and more developers know C-like languages, thus a language like Kotlin is "easier to approach" but necessarily "easier" in the way the presentation talks about
⬐ ISO-morphism> Clojure with the same exact constructs represented with more C-like syntax would, at the level the presentation speaks to, allow the same level of simplicity.I don't think this is true. I think it would be easier for "most people," but definitely not simpler. Easy meaning close at hand, simple meaning one strand, one braid, independent, less context necessary. Clojure syntax is the AST of the program, right there in front of you, in literal notation. There are fewer special cases, fewer moving parts interacting. C syntax requires spinning up a virtual machine in your mind and executing multiple statements. C is easier because we've already spent the time and effort to familiarize ourselves with it, but it has more complexity. Compare a 954 line ANTLR grammar for C [1] with a 261 line Clojure grammar [2].
> Cognitive overhead is lower working with a language that at least "looks like", what you're used to, and more developers know C-like languages, thus a language like Kotlin is "easier to approach" but necessarily "easier" in the way the presentation talks about.
I would agree, using Rich's definitions of simple and easy, that Kotlin is easier for the majority of developers than Clojure. This follows immediately from the definition of easy.
> This is a misapplication of the presentation really. It speaks to a level above selecting a language and is really about the design of systems.
I would recommend Rich Hickey's talk "The Language of the System" [3]. The programming language(s) used are part(s) of the system and have an effect on its design. I don't think this is a misapplication of the "Simple made Easy" presentation, I think it hits the nail on the head.
[1] https://github.com/antlr/grammars-v4/blob/master/c/C.g4 [2] https://github.com/antlr/grammars-v4/blob/master/clojure/Clo... [3] https://www.youtube.com/watch?v=ROor6_NGIWU
⬐ BoorishBearsI feel like this comment is throwing semantics in a blender and pouring it out into the shape you want... but I guess that's the thing about arguing semantics, it usually devolves to that...So I guess I'll just keep my recommendation to Kotlin and you can keep your recommendation to Clojure
⬐ iLemming> I feel like this comment is throwing semantics in a blender and pouring it out into the shape you wantI don't think it is, though. But it is clear that you are arguing with absolute confidence about a thing you have never given a heartfelt attempt to try first. You are debating like a medieval 13th-century mathematician that Roman numerals are elegant and more comfortable to understand, and people been using them for centuries and no need for this Indo-Arabian numeral non-sense that Leonardo, son of Bonacci so passionately keeps talking about.
I don't want to sound patronizing (I guess I'm already are, although not intentionally), but let me give you an advice - never trust your inner skepticism, fight it, dig for the answer - why are you so skeptical about it. Progress pushed forward by individuals who continuously challenge their beliefs. And from what I can see - you are not a mere consumer of progress, you too, do want to be at the front line where it is being made.
⬐ BoorishBearsHahahaThank you for the laugh, I imagined you typing that last paragraph, reading it, and thinking you had said something pithy and being proud to share that hackneyed screed with the world.
Up until this point I haven't even shared my opinions of Clojure (which I've used) in absolute terms, did you realize this is all in relation to OP's description of "dorky languages", so I was speaking to OP's PoV as someone who probably doesn't use non C-like languages, not myself. Erlang, my pet language is plenty dorky, you seem to have confused "dorky" with "bad" or lacking utility.
But alas, let me just be straight forward, Clojure is bad.
A masturbatory aid for bored developers burning perfectly good time and money for their own overinflated sense of accomplishment and their quirky resumes.
Imagine being a language that literally lists it's half it's rationale as "our customers who won't let us run what we want, so we stuck what we actually wanted to make, on this JVM thing that they all know real well".
Clojure code bases devolve into contrived spaghetti so blindingly fast, but by god will the people writing it get off to how dense the code they're writing is while the decent into madness marches on, and boy will they enjoy how they're really sticking it to those stupid Java guys with no types... while 90% the code they interop with was clearly designed to be used in a typed setting.
And you can count down on a M-F calendar view how many days before the codebase will feature a different DSL for each programmer who's touched it which allows them to define complex business rules as a new sub-language instead of icky "normal" shudder code. Java did only a few things right, and no macros was one, imagine thinking undoing that is the right choice.
Clojure devs love to hold up the few high-profile successes and a bunch of no name success stories that are small enough to probably have served just as well by anything from Clojure to writing out Java bytecode in pico.
The funny thing is the most common successful cases actually went and tacked on a freaking type system! https://typedclojure.org/
Have they heard of F#? And if they're so allergic to types, good god why are you on the JVM and trying to interop with JVM code. If you're not trying to interop with JVM code, why Clojure? Why not Elixir or Erlang, which kick Clojure's ass at the other half of the rationale it always gets, concurrency and immutability.
Actually, don't answer that, we already know. Because JVM contains Java, and Java = business, and you're not going to get to jerk off at work with an unproductive language if it doesn't have something a business type can latch onto! You don't want to admit "we want to use this language with a much smaller hiring pool, much less mindshare, unnecessary barriers to interop with one of the largest ecosystems in tech, which is very prone to creating unmaintainable nightmares in the long term by it's very nature."! You want to express it as "we want to use Java but with parenthesis can we huh can we pls pls k thnx".
Clojure is a garbage language that always gets defended with "you just don't get it". What a joke.
The distinction between Simple and EasySimple Made Easy by Rich Hickey
Rich Hickey describes simple as unbraided, like a class is identity, state and schema all braided togetherAnd easy as close by and accessible i.e. npm i latest-framework might be easy but not simple
⬐ setrisn't the same idea exactly covered by the term "(de)coupled"?⬐ modwest⬐ modwestIt can include decoupling, but no it's not synonymous.This presentation had an outsize influence on my professional development as a programmer. If I've watched it once (and I have), I've watched it a dozen times.edit: The "Limits" slide (go to 12:30 in the vid) is one that I really internalized early on. And looking at it again years later, the principles from that slide absolutely guide my app development:
- We can only hope to make reliable those things we can understand
- We can only consider a few things at a time
- Intertwined things must be considered together
- Complexity undermines understanding
For understanding complexity watch this video https://www.infoq.com/presentations/Simple-Made-Easy/Another way to thing theory of programming logic is a general understanding of language logic for which I recommend https://www.amazon.com/Philosophy-Language-P-Martinich/dp/01...
I am going through that book myself right now. It came to me highly recommended. I don’t have a computer science degree.
Here's the original location that has synced slides: https://www.infoq.com/presentations/Simple-Made-Easy/
https://www.infoq.com/presentations/Value-Values/https://www.infoq.com/presentations/Simple-Made-Easy/
https://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hi...
If you're going to watch any of these, at least watch "The Value of Values".
If people wonder, this is NOT the same notion of 'simplicity' at all than in the classic 'Simple Made Easy' talk: https://www.infoq.com/presentations/Simple-Made-Easy/I think a more relevant title for this post would be: "any paradigm made straightforward in Perl 6".
Step 1) Buy a lot of paper. Too many ideas, concepts, and problems in programming are really really big and we have no idea how to effectively tackle them. Being able to take notes, write down your thoughts, create diagrams and pictures, etc is invaluable in being able to learn. Being able to go back and checkout your thoughts in the past helps a lot.Step 2) You'll want to check out these videos and pass them along as you feel they are appropriate: John Cleese on creativity: https://www.youtube.com/watch?v=Pb5oIIPO62g
Philip Wadler on the beginnings of computer science: https://www.youtube.com/watch?v=2PJ_DbKGFUA
Rich Hickey's Simple Made Easy: https://www.infoq.com/presentations/Simple-Made-Easy/
Types and why you should care: https://www.youtube.com/watch?v=0arFPIQatCU
80-20 rule and software: https://www.youtube.com/watch?v=zXRxsRgLRZ4
Jonathan Blow complains about software: https://www.youtube.com/watch?v=k56wra39lwA
I've got a list of videos and other links that is much longer than this. Start paying attention and building your own list. Pass on the links as they become relevant to things your kids encounter.
Step 3) I spent a decade learning effectively every programming language (at some point new languages just become a set of language features that you haven't seen batched together before, but don't otherwise add anything new). You can take it from me, all the programming languages suck. The good news is, though, that you can find a language that clicks well with the way you think about things and approach problem solving. The language that works for you might not work for your kids. Here's a list to try iterating through: Some Dynamic Scripting (Lua, Python, Javascript, etc); Some Lisp (Common Lisp, Racket, Clojure); C; Some Stack (Forth, Factor); Some Array (R, J, APL); Some Down To Earth Functional (Ocaml, ReasonML, F#); Some Academic Functional (Idris, Haskell, F*); C#; Go; Rust
Step 4) Listen to everyone, but remember that software development is on pretty tenuous ground right now. We've been building bridges for thousands of years, but the math for CS has only been around for about 100 years and we've only been doing programming and software development for decades at most. Everyone who is successful will have some good ideas, but there will be an endless list of edge cases where their ideas are worthless at best. Help your kids take the ideas that work for them and not get hung up on ideas that cause them to get lost and frustrated.
> the difference of "simple" and "easy"Don't know if you were already referring to Rich Hickey's talk on this, but if you weren't, it might appeal to you. Simple Made Easy: https://www.infoq.com/presentations/Simple-Made-Easy
"Okay, the other critical thing about simple, as we've just described it, right, is if something is interleaved or not, that's sort of an objective thing. You can probably go and look and see. I don't see any connections. I don't see anywhere where this twist was something else, so simple is actually an objective notion. That's also very important in deciding the difference between simple and easy."
One of the best engineering talks is about this notion that simple!=easy : https://www.infoq.com/presentations/Simple-Made-EasyThis is surprisingly often not understood, even by people I showed the video. And I am not sure why. But I do think it's necessary in out field to start understanding this much more deeply, especially for senior engineers.
Don't mistake easy with simple.https://www.infoq.com/presentations/Simple-Made-Easy
JavaScript is a simple language that can be made extremely complicated via "simple" tooling. You can open the node_modules folder and see how sausages are made. :-)
C++ is dealing with essential complexities, there is no silver bullet:
https://www.infoq.com/presentations/Simple-Made-EasyMy favorite part is the knitted castle.
Agreed. Here’s a link: https://www.infoq.com/presentations/Simple-Made-Easy
Simple Made Easy by Rich Hickey https://www.infoq.com/presentations/Simple-Made-Easy
WordPress is _easy_. It most definitely isn't simple.Highly recommend watching: https://www.infoq.com/presentations/Simple-Made-Easy
The issue seems to be that they are not typically watched on youtube. For example, the "simple made easy" linked above is a low-quality pirate youtube copy, the proper place to watch it is here:
This may not be a good introductory overview but will contain a bunch of interesting ideas: http://aosabook.org/en/index.htmlOld but good: http://sunnyday.mit.edu/16.355/parnas-criteria.html
More ideas:
https://www.infoq.com/presentations/Simple-Made-Easy
http://misko.hevery.com/2008/07/30/top-10-things-which-make-...
I interpreted this as advocating for using a model with the lowest-level abstraction that you think will work. If you start with the simplest abstraction possible, you produce a simpler and more maintainable system. You're also in a better position to incorporate further abstraction later as your understanding of the problem space evolves.This seems like a good opportunity to recommend Rich Hickey's talk "Simple Made Easy": https://www.infoq.com/presentations/Simple-Made-Easy
This is great, but completely lost on the crowd if what Simple means isn't understood.One of the best clarifications of what it means to be Simple, to put it out there, is [1]; but the key point: Simple != Easy.
Simple means minimal coupling, high-cohesion etc etc.
Yet IME many developers do not understand the distinction and mistakenly believe that easy is the same as simple, and are willing to couple the hell out of the world under some false notion of "simplicity"...
⬐ yen223That talk transformed the way I think about software development. I highly recommend watching it.⬐ bluetomcatIn a way, simplicity is the end result of reducing the complex and correct solution without affecting its correctness.As in math, you come up with the "simple" solution of 0.5 only after you've realized that the "complex" solution is, for example, "sin(pi/4) * cos(pi/4)". There might be no other way to discover the simple solution.
I always suggest this https://www.infoq.com/presentations/Simple-Made-Easy
I'd like to propose the "YAML-NOrway Law.""Anyone who uses YAML long enough will eventually get burned when attempting to abbreviate Norway."
Example:
`NO` is parsed as a boolean type, which with the YAML 1.1 spec, there are 22 options to write "true" or "false."[1] For that example, you have wrap "NO" in quotes to get the expected result.NI: Nicaragua NL: Netherlands NO: Norway # boom!This, along with many of the design decisions in YAML strike me as a simple vs. easy[2] tradeoff, where the authors opted for "easy," at the expense of simplicity. I (and I assume others) mostly use YAML for configuration. I need my config files to be dead simple, explicit, and predictable. Easy can take a back seat.
[1]: http://yaml.org/type/bool.html [2]: https://www.infoq.com/presentations/Simple-Made-Easy
⬐ lomnakkusThis is a very good example of the problems of YAML and it's one of those things that has really preplexed me about the design of YAML. (I suppose it's a sign of the times when YAML was designed.)It's[1] just so blatantly unnecessary to support any file encoding other than UTF-8, supporting "extensible data types" which sometimes end up being attack vectors into a language runtime's serialization mechanism, autodetecting the types of values... the list goes on and on. Aside from the ergonomic issues of reading/writing YAML files, it's also absurdly complex to support all of YAML's features... which are used in <1% of YAML files.
A well-designed replacement for certain uses might be Dhall, but I'm not holding my breath for that to gain any widespread acceptance.
[1] Present tense. Things looked massively different at the time, so it's pretty unfair to second-guess the designers of YAML.
⬐ aldanorThis was fixed in YAML 1.2 though? So, e.g., in Python you'd just use ruamel.yaml instead of pyyaml.That doesn't help you, of course, when using a multitude of existing systems whose yaml parsers are based on 1.1...
⬐ bmurphy1976I've been bit by the string made out of digits and starts with 0 thing a couple times. In this case it gets interpreted as a number and drops leading zeroes. I quickly learned to quote all my strings.I'd still love for a better means to resolve ambiguities like this, but I've found always quoting to be a fairly reliable approach.
⬐ clarkevansThe implicit typing rules (ie, unquoted values) should have been application dependent. We debated this when we got started and I thought there was no "right" answer. Alas, Ingy was correct and I was wrong.⬐ allanbreyesI appreciate your humility and professionalism in a discussion thread that holds a lot of criticism; suffice it to say, I should have practiced a bit more humility and a bit less "Monday morning quarterbacking" in my original post. And I should have read your comment on YAML's history. To right the record: you got _so_ much right with YAML, and it's unfair for me to cherry-pick this example 20 years later. Sincere apologies...As the saying goes, "there are only two kinds of languages: the ones people complain about and the ones nobody uses." YAML, like any language, isn't perfect, but it's withheld the test of time and is used by software around the world—many have found it incredibly useful. Sincere thanks for your contribution and work.
⬐ RetraAs someone who doesn't really use YAML much, your comment provides a good introduction to the kinds of things one needs to know before choosing formats in the future.
We Really Don't Know How to Compute: Gerry Sussman - https://www.youtube.com/watch?v=O3tVctB_VSUZebras All the Way Down: Bryan Cantrill - https://www.youtube.com/watch?v=fE2KDzZaxvE
Jonathan Blow on Deep Work: Jonathan Blow - https://www.youtube.com/watch?v=4Ej_3NKA3pk
Simple Made Easy: Rich Hickey - https://www.infoq.com/presentations/Simple-Made-Easy
Effective Programs - 10 Years of Clojure: Rich Hickey - https://www.youtube.com/watch?v=2V1FtfBDsLU&t=845s
The Last Thing D Needs: Scott Meyers - https://www.youtube.com/watch?v=KAWA1DuvCnQ
⬐ christophilusThe first time I watched Simple Made Easy, I didn't like it, even though I'd written quite a few situated programs in my day. A year later, I'd learned Clojure and re-watched it, and it all made so much sense. It's now one of my favorite tech talks.⬐ alecco(via Deep Work)How to Depth Jam: http://chrishecker.com/The_Depth_Jam
⬐ DaviedGabrielI hope I found We Really Don't Know How to Compute: Gerry Sussman talk with better resolution and camera on the board⬐ leraxGerry Sussman talk is awesome and reflects very well the currently state of computer programming. It's a shame. The worse part: there is people around us with a lot of pride ABOUT DON'T KNOWING TO COMPUTE BUT STILL DOING [INNEFICIENT] THINGS. (sorry for the caps, good bye)⬐ 0xbadcafebeeRich Hickey's Greatest Hits: https://changelog.com/posts/rich-hickeys-greatest-hits⬐ corysamaMore Rich Hickey: https://github.com/tallesl/Rich-Hickey-fanclub⬐ stretchwithmeRich Hickey is great. I remember his Simplicity Matters keynote at Rails Conf 2012. So clear and insightful.Being able to explain a complex topic to diverse audiences is not easy to do. Rich does it very well.https://www.youtube.com/watch?v=rI8tNMsozo0⬐ afro88Link: https://youtube.com/watch?v=rI8tNMsozo0⬐ stretchwithmeThanks. Forgot about that.
One of the big benefits of clojure being dynamic is that everything is data (e.g. a map, set, vector or list).This is what allows reuse.
- The vast core library of functions that manipulate those data structures can be used for everything in your program, cos it's all data.
- Most clojure libraries take and/or return data, reducing the need for clumsy adaptors, or even worse not being able to get at the data you need cos the library writer was really enthusiastic about encapsulation of everything they thought was of no use to consumers.
- You don't have a person class, you have a map with a first name and last name. Now the function that turns first + last name into full name can be reused for any other map with the same keys. (A rather spurious example, but a real one would take a large codebase and an essay to describe)
I can only recommend watching some of Rich Hickey's talks, particularly these ones, they're not entirely about types, but they express the above ideas much better than I can:
- Simple made easy https://www.infoq.com/presentations/Simple-Made-Easy
- Effective programs https://www.youtube.com/watch?v=2V1FtfBDsLU
- Are we there yet? (this one is more about OOP, but unless you're using something like haskell, idris etc its relevant for your type system of choice) https://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hi...
⬐ mbrodersenThe data types in Clojure can be very easily (and better) expressed in (say) Haskell. For example: http://tech.frontrowed.com/2017/11/01/rhetoric-of-clojure-an...⬐ joncampbelldev⬐ wtetznerThe main issue is that Haskell is not a data-oriented language by default, this means its no fun to push it to be that. For example, I also have to use java in my job, I use persistent (functional) data structures all the time, but Java is not built for it, its not fun. (Although definitely more fun that using Java's mutable structures, ewww)Also I personally find that to be too much overhead and ceremony in return for some type checking at compile type, as opposed to spec checking at runtime.
⬐ tome> The main issue is that Haskell is not a data-oriented language by defaultWhat do you mean by "data-oriented language"?
⬐ joncampbelldevIn the grandparent comment's link (showing clojure data in haskell): I'm pretty sure that is not how people code in Haskell, its not how the libraries are usually designed etc etc. Using only data is definitely possible in Haskell, but it's not encouraged by default, the core abstractions are used for concretions of information.In the same way you can do immutable and functional stuff in java, it's not going to mesh with the rest of the ecosystem or language around you.
> One of the big benefits of clojure being dynamic is that everything is data (e.g. a map, set, vector or list).What about this can't be done with types? Simple parametric-polymorphism gets you pretty far. Row types allow you to handle "maps as records" in a type-safe way. The rest is just having support for some kind of ad-hoc polymorphism so that you can re-use your functions on that small set of types (type classes, ML-style functors, interfaces, protocols, etc.).
⬐ joncampbelldevAgain, I would refer you to the Rich Hickey talks, I'm not very eloquent on this. I think its about the manual overhead that constructing your hierarchy of types, plus the cognitive overhead of doing all the fancy things in your brackets.I'm familiar with the advantages of type systems (my progression was Java -> Haskell -> Idris) but I found my personal productivity (even in larger systems built in a team) was best in clojure. I didn't feel that the guarantees given to me by the type system were worth the mental overhead, a lot of people feel differently (you amongst them I'm guessing :p)
As a closing point, if I were to ever build something that truly had to be Robust in a "someone will die if this goes even slightly wrong" way, I would reach straight for Idris and probably something like TLA+. However most of my development revolves around larger distributed systems communicating over wires, still resilient but in a different way. Mainly I use clojure.spec in core business logic and at the edges of my programs, for generative testing and ensuring that the data flowing through the system is sensible.
This looks like the perfect example to illustrate the point that Rich Hickey tries to make in "Simple made easy" [1].This huge call stack has been designed to make your life as a developer easy but the price you pay is an enormous amount of complexity.
I've been working a lot with a similar Java web stack and I feel how painful this complexity is. What is worse, is that I think that a lot of this complexity is incidental. There are libraries and frameworks designed to make some things easier, but in the process end up creating a lot of problems that then requires another library or framework to overcome that problem which also has other problems and so on... The result is a huge stack like this.
One concrete example of this is Hibernate. A tool designed to make it easier (apparently) to work with databases, but in the end create so many problems that the medicine ends up being much worse than the disease.
Resolving an HTTP request that returns a the result of a database call should not be this complicated! HTTP is simple! Why do we need so many calls to so many things. I'm not advocating for a flat stack of course, but certainly a stack this deep is a clear sign that something is wrong.
I very much agree with Rich Hickey, we need to stop thinking about how to make things easier and start thinking how to make them simpler.
⬐ gerbilly>One concrete example of this is Hibernate. A tool designed to make it easier (apparently) to work with databases, but in the end create so many problems that the medicine ends up being much worse than the disease.Sure.
At our startup we had the choice to let 20 programmers write custom individual SQL statements for 100s of CRUD operations, or create entities and let Hibernate generate them for us.
We used hibernate and it has worked out well.
I can't imagine how it would have been to debug 100s of bespoke SQL queries and associated object mapping code, each written in the developers unique style after a few years.
That would have been fun.
⬐ ceronman⬐ commandlinefanThanks for sharing your experience. I have worked in both kind of projects. Both very big and heavy based in database access. One using Hibernate and one using plain SQL. We've had considerably more problems with the added complexity of Hibernate.Hibernate does not save you from writing queries. You are still writing queries, just in a language different than SQL (e.g. JPA). It's an abstraction layer. The problem is that this abstraction is very leaky, so if you really want to write performant code with Hibernate you do need to understand how SQL and your database works. And if you really understand how it works, you end up realizing that the abstraction is kinda pointless because SQL is already a really fine abstraction over your database.
And if you need to scale, for example working with a replication setup with multiple db servers and having to deal with eventual consistency, then Hibernate really complicates things.
I think Hibernate is a good example of something that makes things easier at the beginning. At the cost of enormous complexity and difficulty in the long term.
⬐ gerbillyI think ORMs help the most when you have a lot of entities and you need to enable CRUD operations on them.By all means you can use a combination of raw SQL and an ORM.
⬐ le-markLet's be clear, this discussion applies to all ORM's not just hibernate. And yes, any team that adopts an ORM hammer and attempts to use it for all database access, is going to have a bad time. Use ORMs for CRUD, for anything else, use SQL. Hibernate actually makes this really easy.Gavin King:
Well in fairness, we used to say it over and over again until we were blue in the face back when I was working on Hibernate. I even remember a number of times getting called into a client site where basically my only role was to give the team permission to use SQL for a problem that was clearly unsuited to ORM. To me it's just a no-brainer that if ORM isn't helping for some problem, then use something else. [1]
[1] https://www.reddit.com/r/programming/comments/2cnw8x/what_or...
What I can't fully get my head around is how defensive people get about things like Hibernate. I've tried it out, and it doesn't do much for me, but it doesn't really get in my way, either; I can work just as fast with Hibernate as I can with JDBC. I think part of the reason for that, though, is that I can work at either level; I can work out in my head what Hibernate is doing and work with it rather than against it. Somebody higher up retorted with, "why not just write your own web server?" Indeed, why not? I've done it for relatively simple REST-API type cases; as long as you don't need a lot of the more complex HTTP cases like continuation messages, caching, digest authentication and redirects, why not? It's nice to have everything under your control and it's almost definitely faster than any third-party solution that's going to have been written to deal with dozens of corner cases that aren't relevant to what you're doing.⬐ realharo>This huge call stack has been designed to make your life as a developer easy but the price you pay is an enormous amount of complexity.This particular problem could be solved by just having a good filtering UI.
You don't have to analyze the stack in its raw text form.
That being said, I agree that complexity in the Java world is often much higher than it needs to be, and sometimes the tradeoffs are not worth it.
⬐ le-markResolving an HTTP request that returns a the result of a database call should not be this complicated! HTTP is simple! Why do we need so many calls to so many things. I'm not advocating for a flat stack of course, but certainly a stack this deep is a clear sign that something is wrong.Http is pretty simple, executing sql queries against a database is simple-ish (close those connections!). Authentication, authorization, marshalling, unmarshalling, transaction boundaries, ..., are not so simple, especially not when all taken together.
People bemoan java as you are doing here, but the reality is other languages and frameworks, any that attempt to address the same problems and concerns have the same level of complexity. Java has the advantage of kick ass tooling, debugging, and monitoring infrasture, a lot in the jvm itself (visualvm).
⬐ ceronmanJust to clarify, I am not criticizing the Java language. I'm criticising the use of excessive layered frameworks that increase complexity.I like Java. It's simple and performant and has excellent tooling. I just don't like that sometimes I see a lot of incidental complexity in its ecosystem.
Rick Hickey's Simple Made Easy permanently made me a better programmer: https://www.infoq.com/presentations/Simple-Made-EasyAlso his talks on transducers in clojure changed the way I think about functional programming
⬐ daryllxdOh I forgot about that! I actually have some notes: https://github.com/daryllxd/lifelong-learning/blob/master/pr...
I agree. If not “killing” at least “severely” slowing us down. This Rich Hickey talk deserves a link here and it’s right on point: https://www.infoq.com/presentations/Simple-Made-Easy
It's not by the author but Rich Hickey (creator of clojure) has a great talk titled "Simple Made Easy"[1] which I always recommend.Furthermore I have been using Golang and would say it is very simple language that anyone could pick up and become productive with quickly. One of Go's proverbs is "Clear is better than clever."[2] At the expense of a little verbosity there is much less ambiguity in the intent of code.
1. https://www.infoq.com/presentations/Simple-Made-Easy 2. https://go-proverbs.github.io/
> Rich Hickey has this thing where he talks about "simple versus easy". Both of them sound good but for him, only "simple" is good whereas "easy" is bad.I don't think I've ever heard anyone mischaracterize his talk [1] this badly.
The claim is actually that simplicity is a fundamental property of software, whereas ease of use is often dominated by the familiarity a user has with a particular set of tools.
⬐ spiralganglionAgreed, but I have see a lot of people come away from the talk with an unfortunate disdain for ease. Ironically, in disentangling "simple" and "easy", Rich created a lot of confusion about the value of ease.
You mistake simplicity for performance. Simplicity is about lack of interleaving of abstractions, it's about one concept, one task, one role, single responsibility etc. I recommend Rich Hickey's talk "Simple made easy" for that matter: https://www.infoq.com/presentations/Simple-Made-Easy
⬐ austincheneyPerformance is faster execution and lower resource consumption. Perhaps this isn’t so much a factor anymore with low level languages, but in high level languages with several layers of abstractions and giant frameworks there are huge opportunities for writing faster code.
I agree that Redux is a horrible pain.A week ago I started searching for a simple yet powerful solution for the state problem in React. After trying 3 libraries (Baobab, Cerebral and react-cursor) and discarding without trying a bunch more (Derivable, partial-lenses, Cycle and others), I ended up writing the app in Elm (still doing it).
Federal seems like a better Redux, but still too complected[0]. Ideally, I would want something like Baobab (a central store with cursors/lenses and event emitters), but with immutable data structures (not Object.freeze) and without the bugs. Since this ideal will never come (and I won't write it myself) I'll probably use Federal for my next app that could not be written in Elm.
⬐ truesyHmm interesting - I'll check out Baobab
"- My favourite thing: everyone tells you how easy and simple Rx is: it's just observables. In his book on RxJava the creator of RxJava says that it took him several months to understand Rx. While being tutored by one of the creators of ReactiveX. It's "easy and simple" in the same sense as "Haskell is easy and simple" or "rocket science is simple and easy" or <any branch of human knowledge> is simple and easy once you know and understand it."The problem here is that "simple" and "easy" are two completely different concepts. "Simple" is absolute, "easy" is relative. https://www.infoq.com/presentations/Simple-Made-Easy
⬐ dkerstenRx is neither simple nor easy, for non-trivial projects. Its an incredibly leaky abstraction and you end up having to understand the internals to do non-trivial things. Understanding when something runs in what thread (and in RxJava knowing when to use subscribe/subscribeOn/observeOn was much harder than it claimed to be), how to correctly handle errors, retry failed operations, apply backpressure without dropping data — these things essentially force you (in my experience, at least, but I’m no Rx expert, just used it for a few months) to dig into the internals to understand how they work: ie not simple.But because of its lack of simplicity, it was also incredibly hard to use, to make it do what you want. So it was neither simple nor was it easy.
(And yes, I buy into the differences between simple and easy)
If you haven't watched it before, I'd recommend "Simple Made Easy" by Rich Hickey. [0]The reason I say that is because you say "conceptually simple" as if that's a bad thing. Maybe we have to agree to disagree, but in choosing a framework I would much, much rather go for the one that is conceptually simple (at the cost of some extra verbosity in certain cases) over one that is conceptually complex but covers up that complexity with a terse-but-incomplete API.
You're not going to understand the benefits of the Vue vs. React choice by looking at idealized code samples, which is all your comment is showing. You'll only know it once you get into the edge cases. For example for list iteration in Vue...
- ...how do you change that example to omit the last item?
- ...how do you change that example to render a different element for every other item?
- ...how do you render something different if there are no items?
That's what makes the JSX approach simple. Once you understand that you can use any Javascript expression you want, you don't need to learn further. All of those questions can be guesstimated by a newcomer.
But with Vue you have to learn each and every "directive" and "modifier", and consult the docs again each time you forget them.
20 minutes vs an afternoon is probably not a great gauge for making technology choices.I highly recommend watching Rich Hickey's "Simple Made Easy" [1] talk which covers how the right ("simple") choice may not be the "easiest" (convenient, most familiar) one.
⬐ sametmaxI agree. Hence "that and".⬐ alloverI don't mean to be an arse, but if you agree with my point, then maybe you can see why I disagree that your "that and" is a valid strike against React/in favour of Vue.⬐ ZenoArrowSimplicity makes picking up the unfamiliar easier. You can't accurately deduce from time alone that the time to pick up Vue was based on familiarity with similar libraries.⬐ allover> Simplicity makes picking up the unfamiliar easier.The talk I referenced talks about how the opposite is often true. Tools that result in objectively simpler systems can come with a initially steeper learning curve.
> You can't accurately deduce from time alone that the time to pick up Vue was based on familiarity with similar libraries.
True, I was really just suggesting questioning instincts when evaluating tools based on the initial 'time to get started'.
⬐ ZenoArrow> "The talk I referenced talks about how the opposite is often true. Tools that result in objectively simpler systems can come with a initially steeper learning curve."I'm aware of Rich Hickey and Clojure. In my experience with Lisps, although they are superficially simple, they make you do more abstraction work than is necessary in more commonly used high-level imperative languages. Lisp seems to strongly encourage building a high number of helper functions, which is fine if you're highly opinionated about how a job should be done, and less so if you just want to import some battle-tested libraries and write something that gets the job done. I suspect this is where the learning curve with Clojure really comes in, in that it's more closely related to being learn how to architect an application in a Lisp-friendly way than it is about getting familiar with the language.
⬐ alloverTotally agree actually, I love all Rich's talks and agree with almost every word of Simple Made Easy but I don't necessarily agree with the conclusion he takes it to (Clojure).I've heard it suggested somewhere that possibly the leap is in believing that 'a simple thing + a simple thing = a simple thing'.
I submitted this link before I had watched the whole thing. As someone who has only dabbled in Clojure I think there are a lot of interesting ideas in there but found the type-system bashing pretty off-putting.I am now watching his "Simple Made Easy" talk [1] after I have heard it recommended on a few functional programming related podcasts. Again really interesting stuff but I encountered another cheap shot at typed functional programming ("You can't use monads for that! Hurr hurr hurr").
Given how well received these talks seem to be by people that enjoy programming with advanced type systems I would have have really expected a more balanced discussion and some acknowledgement of the trade-offs between dynamic and statically typed functional programming.
⬐ gldalmasoI really like Rich's views and find Clojure very interesting as well. That said, as a Java shop with Javascript frontend, nowadays the bulk of complexity in our code base seems to accumulate in the frontend due to mixed skill levels of the team and lack of opinionated structure in the language. This leads to some rather messy code that even skilled devs are afraid to touch because of lack of feedback from the IDE that some refactor is working without loose ends.The same problem with the same people just doesn't happen in the backend and I link that to static typing and IDE maturity. We have started to adopt Typescript and are seeing improvements already.
We just have to live with the fact not all developers working in the code are mature enough to avoid language and code organization pitfalls. Refactoring should be mostly a safe endeavor, even if only structurally.
This is the main reason I wouldn't suggest Clojure for our team.
⬐ hellofunk⬐ sheepmulletI agree that there is definitely added discipline needed to succeed well in large dynamically-typed projects. I also think that learning to build large projects in such languages is like running your marathon training high in the mountains, so when you get back to sea-level your body feels the joy. You are forced to write very clean code in Clojure if you want to easily maintain it later. That's a great skill that translates to any other language where less discipline might still get you far.⬐ lilactownI think it's something else, as well. Rich even mentions it in his talk: languages like Java (which I'm reading to mean "statically typed") are great at mechanical tasks. Front end programming is mostly filled with mechanical tasks: scaffold this structure/layout. Wire up these events. Make this thing blue/bold/etc. Change the state when these events happen. It's fairly predictable in structure in line-of-business apps, at least once you're following an intelligent structure, e.g. the Elm architecture.UI/Front end dev, IMO, can gain quite a bit from static typing. I'm a huge fan of clojurescript, it's what I reach for whenever I want to work on something, but I'm super excited about ReasonML for the future of my team; we struggle with our JavaScript code base right now due to the lack of imposed structure and feedback for our weaker developers.
I love Clojure and I think it makes sense in a lot of domains; most of my back end development is "take this data, transform it according to some nebulous business rules, and poop it out to some other place," which Clojure is amazing for. It's great for applications that don't require a lot of "wiring", and require a lot of "flow". UI programming is, for the most part, wiring things up. It's not that Clojure/Script is not up to the task (I think e.g. re-frame, and the stuff being done with Fulcro, is amazing) but I definitely see the benefits of static typing more in that domain.
And like Rich said, if you're doing UI it will usually completely dominate the problem space you're working in. So pick the right tool for the job. I'm not convinced TypeScript is the way exactly, but like I said, ReasonML and Elm are super promising.
> but found the type-system bashing pretty off-putting.Why do you think it is type system bashing?
He is justifying why he didn't add types to Clojure. In his experience they add more complexity than they are worth.
The reason he talks about it at all is there are a lot of static typing enthusiasts who talk about static typing being a game changer.
In my experience static typing is a +-2-3% productivity influencer. You get a bit better IDE experience and refactoring is easier. On the other hand I've also found I need to refactor my C# code far more often than my Clojure code.
⬐ whalesaladGotta take the good with the bad. Tons of knowledge and wisdom to be gained from the FP folks but sometimes they do have the cheap shots and the bias of the community.Ie, It’s easy to hate and joke about things like SQL databases and JSON when you live in your own utopian fairy land where everything is Datomic and EDN.
⬐ joncampbelldevI believe the quote you're referencing about monads is "this is meant to lull you into believing everything I say is true, because I can't use monads for that" (referring to an animation of a stick figure juggling)⬐ hellofunkThe new Conj talk is certainly an interesting look at one man's (or one community's) look at static typing. However, as much as I admire Rich, some of the points he made don't resonate with me, particularly the one about how compile-time checks to catch minor bugs in syntax are not a particularly useful feature of static typing. I certainly disagree. As someone who writes Clojure all day long right now for a living, I am constantly dealing with runtime errors that are due to minor typos in my code that I have to track down, and this time would be greatly saved by having a compiler tell me "on line 23 you looked for :foo keyword in a map but you meant to type :foobar, so that's why that was nil" and many other similar woes.I love Clojure but I really miss static type checks.
The other item in his talk I do not agree with, he says (slightly paraphrasing) "in static typing, you can pattern match on something 500 times but if you add a case, you have to update those 500 matches to handle the new case, when really they don't care about this new case, only the new logic needs to consume this special case, it's better for the producer to speak directly to the consumer". Well, in languages like OCaml, Swift, Haskell, it is a feature that pattern matches much be exhaustive. This prevents bugs. In most cases, I'd expect that if I add a case to an enum, the chances are good my existing logic in pattern matches should know about that. Maybe not all, but a lot of them will. It's nice to have the compiler guide you to those places.
I certainly like how fast I can write programs in Clojure, and I like the minimal amount of code that makes refactoring and rewriting fairly straightforward since there is not a lot of time investment in the existing number of lines, and I like the incredible elegance of Clojure's approach to functional programming.
But I do miss having much greater compiler assitance with typos, mis-typed argument order to functions, mis-typed keyword names, etc. Would really save a lot of time.
⬐ DigitalJackStill reading your comment, but after the first paragraph, I would kindly suggest looking at clojure.spec. It's helped me immensely in similar problems.⬐ hellofunk⬐ keymoneI suppose you'd have to use spec/assert for every instance of destructuring or "get" or "get-in" to avoid common mistakes. That's a lot of asserts everywhere.⬐ DigitalJackI don't understand this comment.I spec types, and then I spec functions that need that type. But not all the function, just the heavy use ones.
I usually don't instrument the spec'd functions unless I'm actively debugging.
edit:
after having a minute to think on it, do you mean to catch a typo in the use of get, get-in, etc? I haven't tried that.
I suppose you could wrap get, get-in with a nil check or something.
⬐ hellofunk> I suppose you could wrap get, get-in with a nil check or something.Indeed I suppose the solution would be write wrappers around common getters that allow you to pass a spec to the query and have them automatically assert that everything is what you expect.
> As someone who writes Clojure all day long right now for a living, I am constantly dealing with runtime errors that are due to minor typos in my code that I have to track down, and this time would be greatly saved by having a compiler tell me "on line 23 you looked for :foo keyword in a map but you meant to type :foobar, so that's why that was nil" and many other similar woes.i wonder if this is because it really takes a quantum leap in one's development style between <insert your previous programming language> and clojure/<insert your favourite lisp>? as long as your environment allows for effortless evaluation of code you're writing, you'd be getting this feedback no slower than the edit/save/compile/retry cycle.
⬐ hellofunkIf your typos are triggered by UI events, then you often won't see these problems until interacting with your UI (I work mainly in Clojurescript). Further, these typos may not get noticed at all for a long time if a code path is never taken. Of course, that's what unit tests are for. But writing tests takes time also. I'm not sure it's worth the trade off to spend the time writing those tests that I could spend writing in a more statically-typed language that would catch some things that tests wouldn't be needed for. (Besides, writing tests for UI stuff is pretty hard).I am griping, really, because I cannot stress enough how nice it feels most of the time to write Clojurescript. But in complex projects, there is not doubt that a lot of time gets spent on things that wouldn't need to be spent if the language had even a very basic type system to back up the syntax for some things.
⬐ keymonewhich ui library are you using? not claiming to be an expert, but i always found it easier to test programs when logic is completely decoupled from event flow. but yeah, UI can be pita.also isn't clojure.spec useful for describing and asserting the shape of data taken and returned by functions?
⬐ hellofunk⬐ christophilusClojure.spec is useful for a lot of things, but unless you are adding spec/assert to nearly every destructuring or "get" or "get-in" then it's still easy get nils running through your data transformations because you mistyped a keyword or something.Also there is not a good answer for asserting the value of a function passed to another function; the return values of functions can be spec'd but they are not included in an assert test.
⬐ sooheon> the return values of functions can be spec'd but they are not included in an assert testI agree this is a shortcoming, but that is why this library exists: https://github.com/jeaye/orchestra
⬐ NoneNoneMy team recently settled on TypeScript instead of ClojureScript, as TS is the safer bet, more familiar, more consistent with the existing project's tooling, etc. But man... I've taken a handful of files and written them in both TS and CLJS. CLJS is just so much shorter and elegant. I sometimes think we made the wrong decision.⬐ athousandcountsClojureScript is great with Reagent or re-frame... If you write Angular use TypeScript. If you use React, ClojureScript! It's a match made in heaven.⬐ christophilusYeah. I've built toy apps with re-frame, and really liked the way the code looked. But my team is pretty Jr other than me, and I wasn't sure if ClojureScript would work well for us as a team. VS Code is our editor of choice, and it is just really a good environment when paired with TypeScript.Also, my experience with Rails really has me fearful of doing any serious, big work, in a dynamic language.
Just a quick comment. I think the differences go beyond values, to what you might call world views or paradigms (in the Kuhnian sense). Take, for example, the value of "simplicity". This is extremely overloaded. I doubt the speaker and I would agree on what is simple. I'm not familiar with a lot of the examples they used, but I'm going to guess they would consider C simple and something like Haskell as "not simple". I think that C is familiar but not simple (too much undefined behavior) and Haskell is simple but not familiar; more generally people conflate simple with familiarity. There is a nice Rich Hickey talk "Simple Made Easy" (https://www.infoq.com/presentations/Simple-Made-Easy) on this theme, or a blog post I wrote "Simple is Not Easy" (https://underscore.io/blog/posts/2015/07/21/simple-isnt-easy...).Similarly in the discussion of promises. I have written a lot of code using promises---though not in Javascript---and it's fine to debug. Javascript just makes a mess of it because it can't decide on what world view it wants. Is it trying to become a modern somewhat-functional language, which is the direction Ecmascript, Flow, Typescript, etc. are going? Or it is a primarily imperative language? If you go for the former you have very different expectations about how the language operates than the latter. It's notable that most functional programmers (which is my day job) don't make much use of debuggers and the kind of tools the speaker talks about building are not generally valued that much.
Now I don't want to give the impression that I think the speaker's world view is wrong. It's just different. Notable though is that we would have fundamental disagreements in how we view the world. It's not that we value, say, simplicity differently. We disagree on how simple is even defined.
It's like LEGO's. The blocks are sturdy and the rules of how blocks fit together are simple. But building a mini Taj Mahal is still not easy. You do have to know basic physics & structural engineering, but if you do, the task is very do-able. Even fun.Unlike if you were building a mini Taj Mahal out of match sticks, Elmer's glue, rope, and playing cards. Even a professional structural engineer would have a hard time with that. The rules of gluing a match stick and a playing card together are already complex (not to mention uncertainty about where to rope fits in), and it that makes it that much harder to make a final product.
This video goes into "simple" vs. "easy" https://www.infoq.com/presentations/Simple-Made-Easy
I think he goes by Pete ;)Edit: While I'm here, might as well link to the Simple Made Easy talk by Rich Hickey. The other thing (aside from inventing Clojure) that gave him prophet-like status in the community.
⬐ cutlerRich Hickey is one of the rare breed of thinkers in the programming world whose ideas have great relevance even if you're not interested in the language he invented.
After seeing Rich Hickey's excellent material on the matter^, I can no longer read anything talking about Simplicity and Complexity in programming without suspecting the author of being fast and loose with what those terms specifically mean.As it stands, they are recipe for different camps and sub-camps of programmers to talk past each other endlessly.
⬐ xyzzy_plughI tend to agree with you, but I think Cheney has done an excellent job here. Did you even read TFA?⬐ frou_dh⬐ taericYes - evidently not as impressed. It's against the site guidelines to ask that btw.For example, I cannot accept that having no means to define immutable structures makes for an overall "simpler" programming model. What could be simpler than allowing information to be information?
Whether having an additional concept makes Go more burdensome to learn and implement is another matter, and is on a different axis to Simplicity/Complexity (again, using Hickey's excellent deconstruction of simple/complex vs. easy/hard).
Not that you don't have a point, but I actually prefer fast and loose with most terms. Ironically, I find it leads to simpler conversations. :)It can lead to some misunderstandings, but I think those are usually given more voice than they are worth.
Also ironically given everything I just wrote, I found that an odd mark for a footnote. I instinctively look up when I see the caret. Usually for a superscript, but not seeing one my eye kept going.
⬐ sridca⬐ catnaroek> I actually prefer fast and loose with most terms. Ironically, I find it leads to simpler conversations.You mean simplistic conversations right?
The problem with being fast and loose with terminology is that it lacks precision; and with lack of precision comes ambiguity and misinterpretation, which beats the whole point of good communication.
⬐ taericSorta. I'm reminded of the point Feynman made about keeping everything as "layman" in explanation as possible. His point was basically not to hide behind jargon and highly specific terms in trying to explain something.So, if communication is hinged on highly specific meanings of words, the odds go way up that someone will not actually hear what you think you are saying.
Instead, keep conversations high level and do not rely on the specific meanings. It requires more thought from the listeners, in some ways, but it actually relies on less pre existing knowledge from the listeners.
It is tempting to think you have narrowed your audience down to non laymen. This is often an incorrect assumption, though.
And in writing, this can go out completely. There is a place for highly specific and very precise language. It is usually best along side the non-specific language.
Simplicity is very easy to objectively measure. Write down a formal semantics for the programming language in question, and count how many pages you used.But, of course, nobody will actually do this, because it would expose the inherent complexity of designs advertised as simple. Many people's feelings would be hurt in the process.
⬐ majewskyAs long as the result is shorter than 1500 pages (afair), your language is simpler than C++.⬐ catnaroek⬐ woahAnd the C++ specification isn't even a formal one.Why don't you do it?⬐ catnaroek⬐ MereInterestBecause I have no time to study languages I dislike, and the one that I do like (Standard ML) already has a formal semantics and a type safety proof.I would argue that is a good measure of the simplicity of the language itself, but not a measure of the simplicity of the use of the language. By that measure, Malbolge is a simple language than C++ by a factor of ~1000. However, it is still much simpler to write code in C++ than in Malbolge.⬐ catnaroekI said absolutely nothing about ease of use.⬐ codygmanFor many simplicity is defined by ease of use though.⬐ catnaroekEase of use is subjective. It depends on people's goals, skills and even tastes.
Sounds like you're confusing 'simple' with 'easy'. Rich Hickey does a good job of contrasting the two in Simple Made Easy[0].The essential part of Redux is only 44 lines of simple code [1]. You can understand everything that it is doing. That is simple. It doesn't mean that it's going to be a great experience to work with (you might want to add some abstraction on top to make it also 'easy'), but it is definitely simple.
[0]: https://www.infoq.com/presentations/Simple-Made-Easy
[1]: https://gist.github.com/gaearon/ffd88b0e4f00b22c3159#file-sl...
functional is simple, oop is easyhttps://www.infoq.com/presentations/Simple-Made-Easy?variant...
> Rust doesn't compile that way -- you can't compile individual modules at once, only the entire crate.I think we have a terminology mixup. I was using 'module' in the win32 LoadModule() sense: a shared dynamically loaded library (ie. a .DLL in windows or .SO in linux.) I'm not sure how Rust crates (or other compilation units) map to those - my guess would be that a given crate will be compiled into (in win32 terms) a .exe .lib or .dll
I /think/ the Rust equivalent of the case I'm describing would be that you have a struct that's part of the public API of a crate, and it's being used across multiple crates in a large project where you don't want to fully recompile the world in order to test your changes.
> Of course you may be in a situation where you can't rely on the debuginfo (stripped binary or something?), in which case this will be annoying. But it's really a similar situation as you have with inlining when you don't have debuginfo.
In my C++ experience there end up being plenty of cases where it's really useful to be able to inspect raw memory (ie. hex dump, with no debugger or without enough context for the debugger to help you) and figure out what was going on. Obviously Rust is designed to dramatically reduce the frequency of that kind of debugging, but to me this still feels more like a simple-vs-easy trade off [1] than a strict win.
> The presence of ADTs in Rust mean that the layout of many types isn't immediately obvious without debuginfo anyway.
Pardon my Rust ignorance, but is this scenario significantly different from C++ templates? The layout of a (judiciously) templated C++ class may not be "immediately obvious" but in practice it's often still very straightforward to infer.
⬐ dbaupp> I'm not sure how Rust crates (or other compilation units) map to those - my guess would be that a given crate will be compiled into (in win32 terms) a .exe .lib or .dllYou're correct.
> but to me this still feels more like a simple-vs-easy trade off [1] than a strict win.
If you're meaning the easy side is stopping people having to reorder fields themselves, it's more than that: generics plus C++-style monomorphisation/specialisation mean there are cases when it's impossible for the definition of the type to choose the right order. For instance: given struct CountedPair<A,B> { x: u32, a: A, b: B }, all three of CountedPair<u64, u64>, CountedPair<u64, u8> and CountedPair<u16, u8> need different orders.
⬐ Manishearth> I think we have a terminology mixup.Not really -- my core point was that C++ compilation units are usually smaller than Rust.
Most C++ codebases I've dealt with will be of the kind where there's a single stage where all the cpp files get compiled one by one. Not a step by step process where one "module" gets compiled followed by its dependencies.
For these codebases, you have a huge win if you can touch a header file and only cause a small set of things to be recompiled. For Rust codebases, it's already a large compilation unit, so you're usually already paying that cost (and with incremental compilation the compiler can reduce that cost, but smartly, so you get a sweet spot where you're not compiling too much but are not missing anything either).
But yes, being able to skip compilation of downstream crates would be nice.
(You're right that a crate is compiled into a .exe or .so or whatever)
> Pardon my Rust ignorance, but is this scenario significantly different from C++ templates? The layout of a (judiciously) templated C++ class may not be "immediately obvious" but in practice it's often still very straightforward to infer.
ADTs are tagged unions. There's a tag, but it can sometimes be optimized out and hidden away elsewhere.
You can mentally unravel templates to figure them out. Enums are a whole new kind of layout that you need to understand.
⬐ CAMLORNThere are two specific cases here where the layout is not obvious.The first is the null-pointer optimization (I think this is the official name but I swear I question myself every time I mention it), in which we use knowledge that an inner struct contains a reference to avoid enum discriminants. that is, Option<i32> will have an extra field up front saying if it's None or Some, but Option<&i32> will just encode None as the null pointer because references can't be null. This also optimizes something like Result<&i32, ()>. The net result is that a lot of stuff that looks expensive is basically free. There has been discussion of extending this to use multiple pointers so that we can hit more complicated enums like Option<Option<(&i32, &i32)>>, but this has thus far not happened.
The second is enums themselves. The discriminant algorithm is not obvious. If you want a discriminant of a specific size, you can pick it with a repr. But otherwise it's implementation defined.
And there is one third thing we have discussed doing but haven't yet. If you have a bunch of enums nested inside each other, having multiple discriminants is a waste. There is no reason the compiler can't just collapse them down into 1 in a lot (but not all) cases.
For anyone who wants to know the specific algorithm for all of this, it's now all in one place: src/librustc/ty/layout.rs
Beautiful insightI wish I could take credit for this one! I learned the distinction from a (rather famous) Rich Hickey talk. [0]
I don't think about "less code" when I'm writing code. You write something (ideally) once, and you read it many times. It's very inefficient to optimize for code-writing when the most expensive activities are learning, re-learning, and maintaining code. If your code is twice as long but easier to understand, you should just make it twice as long.As far as more code reuse, the tools I mentioned don't affect that. A good rule of thumb is not to write the same code twice. If you write it a third time, move it into a reusable function. I actually rarely write the same code even twice.
So yes, most of the savings come from 1) not having to debug and 2) not doing maintenance until I want the code's behavior to change. With great static analysis and a type system, you might spend 5x more time writing before you run your code the first time, but it always just works when you do run it the first time. It's amazing.
This is a famous talk by Rich Hickey that will discuss some of these issues much better than I can:
https://www.infoq.com/presentations/Simple-Made-Easy
(Video on the left)
⬐ kenshiThank you for taking the time to respond and the link.
Yes, fallacies of definition are one of the primary reasons for misunderstanding, e.g. we both are using the same word, we both have an idea of what the word means and/or are using it in a specific way; however, we both think the word means something different, and we both assume the other person is using the word in the way we are. Piles of disagreements have been built on this one simple fallacy.https://en.wikipedia.org/wiki/Fallacies_of_definition
That's one of the reasons why I like how Rich Hickey begins all of his talks with precise deconstructions of the definitions for the words that are integral to the theme of his talk, as he does in "Simple Made Easy":
https://www.infoq.com/presentations/Simple-Made-Easy
Once you establish a common understanding for the meaning of the words you are using, you have not only cleared up any potential misunderstandings, but you have also implicitly established points of agreement and have established a solid foundation to build on.
⬐ mmphosishttps://github.com/matthiasn/talk-transcripts/blob/master/Hi...⬐ romanivThis is a classic. Definitely worth watching for everyone working within IT.⬐ nailerOne thing I've found super helpful on my current project (which happens to be node) is using OSS concepts and npm as a unit of modularity.Eg, everything is just a grab bag of functions in an npm module (sometimes with a closure holding some state - I either reject or don't understand FP people when they claim FP doesn't have state).
Each module has tests, dependencies, a README, and if it is reusable by other projects, is even OSSd and published. Writing software as if it's going to be published makes me be more modular. Being modular makes things easier to reason about and therefore has stopped by codebase from becoming complex to work with.
⬐ chowells⬐ swahFP people have never claimed they don't have state. That's a straw man used to argue against something no one is saying.The claim is that there is no hidden state - everything is made explicit.
⬐ nailer⬐ steinuilI have no argument against FP, not am I making one here. But plenty of FP advocates claim FP "avoids state". It's not a straw man, it's just experience from asking people to explain FP.> I either reject or don't understand FP people when they claim FP doesn't have state).But that's not what state is, closures are just an easier way to define lots of functions with similar parts.
EDIT: Sure, you can call "whether or not f() or x are defined at the moment of calling (y) => f(x, y);" a form of "state", but this is called late binding and is simply not a thing in purely functional languages like Haskell; the existence of f() and x is checked at compile time.
⬐ kazagistarI think you might be confusing state and values. Pure functional programming has plenty of values. If you need a new value, you just return the new value, instead of reaching into an existing data structure and messing with it.If a function closes over immutable values, then the resulting closure is an immutable value. If a function closes over mutable state, then its mutable state, often even uglier then mutable objects or structs which actually make the exact contents easier to identify at least.
⬐ mdgart"I either reject or don't understand FP people when they claim FP doesn't have state" FP has state, but it makes it explicit avoiding side effects inside functions and using persistent data structures, that means, instead of mutating the state you create a new state. Without state basically any program is totally useless.At some point it felt like Clojure was the future, the new thing, so amazingly better - was that just a feeling of novelty? Or something went wrong with its use case?Of course, these days its about Rust, Swift and LLVM, but it doesn't have those lispy properties we love...
⬐ mej10⬐ NoneHave been using Clojure in production for several years.It is great language to work in. I have found it very suitable for solving a wide range of problems. Many companies are using it successfully.
Sounds like your view of reality is based on the HN hype cycle. As far as I can tell there are many more companies using Clojure in production than Rust. (nothing against Rust, but just as an example of the bias)
⬐ chousukeI think Clojure is doing just fine. I've seen it used in "real-world" proprietary software (custom-made for a client by a third party). It's just usually packaged as a jar file, so no-one notices unless you look for certain tells.⬐ jcadamCurrently using Clojure on a side-project. It makes me so much more productive -- a real win when I don't have a ton of hours to devote to a project due to also having a day job :)If only I could find a day job using Clojure...
⬐ afandianI've been using it for 3 years and as I get my teeth further into my current project, I am grateful for Clojure every day.⬐ steinuilIt just got old. Those who wanted to check it out already have, those who liked it either got a job using it or have spent enough time with it to get bored, and those who didn't have probably forgotten about it already.People just need a change every now and then, you can't get excited about stuff you see or use every day after a while.
⬐ rlanderI felt like that, like Clojure was the future, around 2009/2010. But then Java libraries and their impossible stack traces got in the way.I've been waiting for a native Clojure implementation (or on top of Python or the Erlang VM) ever since.
⬐ swah⬐ madmax96Yep, I'd love something like Clojure with an implementation/tooling like Go's.⬐ pjmlpThere are few abandoned attempts.Writing from scratch those Java libraries, including a good quality AOT compiler and GC is not something to do as hobby on the weekends.
⬐ branchly2Don't need all those Java libraries if you've got good FFI with C libraries.Don't need AOT compilation; if you want performance, just stick with regular Clojure on the JVM.
I'd love to just see a small general-purpose interpreted Clojure (quick start up, small memory footprint, easy access to C libs), even if it lacked concurrency features.
⬐ pjmlp⬐ nickikFor that I fail to see the point of why not use a Scheme or Common Lisp compiler instead.⬐ KingMob⬐ KingMobYeah, for native executables, CL and Racket are much further ahead.⬐ branchly2Thank you. Though I really like having Clojure's:* literal syntax for maps, vectors, sets, and regexes
* keywords
* clear separation of functional constructs (`for`, `map`, etc.) vs side-effecting ones (`do`, `doall`, `when`).
* large standard library of built-in functions, with overall fairly nice naming of things.
I've looked at Scheme, but it appears to be missing those things. I think some of them may be provided by srfi's, but upon a quick reading I couldn't make much sense of how to include and use them.
⬐ nickikRacket is probably something you should look at. Im not sure it has all these things, but it is also a modern updated Lisp language based on Scheme.Lumo (https://github.com/anmonteiro/lumo) or Planck may fit your requirements, though they lack a C FFI. They're based off ClojureScript/Javascript, and startup way faster than the JVM Clojure. Could probably try the node-ffi library with Lumo.There's the abandoned ClojureC project (https://github.com/schani/clojurec). There's also JVM-to-native compilers like gcj or ExcelsiorJet.
But at the moment, it doesn't seem like there's an established way to do all that.
Hey. My attempted is not abandoned just sleeping :).The best chance to get it is to extend something that is ClojureScript based. I think you can get pretty close to it.
My implementation was never really targeting production use, but rather exploring some ideas in the VM.
I would love to continue working on it, but I simply do not have time for such a project.
See github.com/clojit if you are interested.
I think that you are right that Rust, Swift, etc. have the hype now.In my mind, this is a product of containerization. Java solved a lot of problems that we faced with deployment. Containers have made deployment even simpler, and suddenly the Java runtime is no longer as valuable as it once was. Furthermore, in a service-oriented architecture we don't really need too much interop with existing code.
I think that Clojure is a fantastic language, and I use it for my side projects as much as I can. But the promises made by Clojure dont sound as sexy as they did several years ago, hence the lack of hype.
⬐ nepeckmanI feel like every new language has a honeymoon period. Clojure is still alive and well (and growing bigger consistently) but it doesn't have that new language hype anymore.⬐ notduncansmithClojure's first stable release was in 2009 so it's either very young or very old, depending on how far you zoom out.Rust is exciting for use-cases that are very different from Clojure's, and the only thing I can say for Swift in this context is that I prefer it to Javascript, which I in turn prefer to other C-style languages.
I'm currently working on a single-person (but expected to grow) project in Clojure and really appreciate the concurrency and state primitives, the functional standard library, the ecosystem and community of high-quality standard tools and packages, and (while I seldom write them myself) macros, which enable you to you write amazingly readable code. The community has a strong preference to functions over macros, but used judiciously you can get things like Clojure's core.async. So you get the benefits of a Lisp without a lot of the drawbacks commonly pointed out regarding other Lisps. I enjoy it a lot.
None⬐ rcarmoNeeds a (2011) in the title. Still a very good session, though.⬐ nailer⬐ corysamaDone.Simple Made Easy is a great introduction to the Rich Hickey Fanclub [1] ;)Other recommendations for early viewing are "Hammock Driven Development", "The Value of Values" and "The Design of Datomic".
⬐ ameliusHickey may be a brilliant software architect, but I'm wondering how high he ranks as a business leader. How is his company Datomic doing? Also in the light of the new database service Cloud Spanner just launched by Google.⬐ Scarbutt⬐ pmarreckDidn't see anything about time-series features in spanner.⬐ pmarreckI would love to know how using Datomic is vs. rolling your own data-immutability solution via other mechanisms but using off-the-shelf SQL/big-data tools.⬐ rchAnecdotal, but I've run into a couple of companies currently using Datomic in analytics and ML (with Clojure).⬐ mh8hDatomic is very different from the typical database in terms of the operations it supports. I don't think Google Spanner, or the other similar products, are direct competitors.I don't know much about how they are doing financially though.
You forgot "Are We There Yet?", which blew my mind at the time ("with respect to other code, mutability is an immutable function with a hidden time argument") and which was MY introduction to this fanclub.https://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hi...
Rich Hickey's talk on simplicity is a must watch.https://www.infoq.com/presentations/Simple-Made-Easy
And one of the most useful talks of all time for building organizations is by Ed Catmull (of Pixar)
⬐ Phorkyas1In a similar vein like the first one, maybe, but with the addition of some physicist's humor if you are in into that kind of thing: https://www.youtube.com/watch?v=lKXe3HUG2l4⬐ michaelsbradleyI saw Simple Made Easy live, in person, in Saint Louis (where I live), back in Fall 2011. I remember the experience very well ~ forever changed the trajectory of my personal and professional efforts at software development.I was so under-exposed to non C-family languages at the time that I asked the guy next to met whether the code used to demo the ideas "was Haskell or something else?" I felt embarrassed at the shocked look on his face; my grand exploration of Clojure (and other functional languages too!) began shortly thereafter. The previous evening, I'd accidentally had dinner with Dr. Gerald Sussman... what a conference, what an experience was Strange Loop 2011!
⬐ lewisl9029The Front End Architecture Revolution by David Nolen is one of my all-time favorites, and was probably the biggest single influence on the trajectory of my own development career: http://www.ustream.tv/recorded/61483785
Not sure if unthinkable is the right word:Simple Made Easy: https://www.infoq.com/presentations/Simple-Made-Easy
David Nolen talks about how immutable structures work: https://youtu.be/SiFwRtCnxv4?t=504
Objects are Marionettes: https://www.youtube.com/watch?v=VSdnJDO-xdg&feature=youtu.be...
⬐ grzmNot sure if unthinkable is the right wordThat's exactly what I'm asking about. I'm familiar with Hickey and Nolen.
> That seem to go against the definition of simple: easily understood or done; presenting no difficulty.That's not a great definition of 'simple' to apply to software dev. Simple != easy, because easy is inherently about familiarity. See Rich Hickey's excellent talk on the subject [1].
⬐ daenneyThat talk doesn't relate to the whole discipline of software development though. He's mostly arguing that if you chose ease over simplicity in your programming/code it can heavily effect the output of your work and its long term viability. It's about not introducing complexity in the design and your product.But this is about the process and workflows of collaboration on code, not the code or the product itself. Some of these concepts certainly apply but just because it is in the realm of software development doesn't mean that particular definition always applies.
⬐ nilliamsHmm, not quite how I'd see it. You're right to point out different considerations are required for 'process and workflows', but I think Rich's simple/easy definitions still hold up in those situations, and are more useful than munging the two terms together.So instead I'd say that when it comes to 'process and workflows' easiness becomes more important, because if it's an action you're literally doing everyday, you want that to be easy. In fact you might be willing to write more 'complex' underlying code/infrastructure (as we do when we setup CI) to make the process 'easy'.
Rich Hickey(Creator of Clojure) has talked about this. Type-specific lingo prevents one from applying common patterns of transformation. Check https://www.infoq.com/presentations/Simple-Made-Easy
⬐ CoolGuySteveI find myself referencing parts of this talk a lot when talking with my coworkers. In particular, the guardrail and knitted castle analogies are quite elegant.⬐ sidcoolThis is posted every week in one form or the other. A classic talk though.
Coming from the HFT side, I find C++ surpasses C in a lot of ways for optimization work. Mainly you can use integer template arguments and generic functions to abstract all the boilerplate in a way that is more safe than C macros.For a semi-contrived example, instead of writing a do4Things() and do8Things() to unwind some loops, I can write template<int> doThings() where the int argument is the bound on the loop.
And having things like a universal template<typename Whatever> toString() that operates on enum classes is nice.
The downside is that it's horribly easy to invoke allocations and copy constructors by forgetting an ampersand somewhere, and the std library isn't well suited to avoiding that behavior either. You have to be vigilant on your timings and occasionally callgrind the whole thing.
The other downside is that your colleagues are more likely to "knit a castle" with ridiculous class hierarchies or over-generalization. ( https://www.infoq.com/presentations/Simple-Made-Easy )
⬐ majewskyI have a friend who makes a living writing CUDA kernels as C++ templates. His job will be safe for decades to come because noone will be able to decipher the code. :)⬐ alfalfasproutYeah, the nice thing about C++ is that you can generally hide highly optimized portions of code behind nice templates or class interfaces. And with templates you can write libraries that let a lot of compile time logic happen to inline a bunch of stuff and not have to resort to virtual methods.But when it comes to using things like custom allocators, etc. it's a nightmare. Or a lot of the compile time "traits".
Typed data was already possible with schema [1], which is now maintained by the plumatic (former prismatic) team. Which also says something about the way Clojure is awesome. Everything is optional, you arent forced to use anything to get to a working solution. Stuart Halloway and Rich Hickey also have some great talks on this subject. If you are interested you might want to check out "Radical Simplicity" [1] by Stuart and "Simple Made Easy" [2] by Rich to see why Clojure wipes the floor with almost any other programming language, especially the likes of C# and Java.I am not surprised at all Bob Martin loves it. Any principled software engineer would.
[1] https://skillsmatter.com/skillscasts/2302-radical-simplicity
> If you're gonna spend many thousands of hours using a language, don't use initial learn-time as the one thing to optimize for!That reminds me of this wonderful talk by Rich Hickey called Simple Made Easy, https://www.infoq.com/presentations/Simple-Made-Easy.
We've been using Pouch in a progressive web app designed to be used on the field in remote locations, and while there was a learning curve in understanding how the replication protocol works, and as highlighted in another comment the way Chrome stores data for a web app - we can't be happier with pouch/couch.Additionally, moving out of Cloudant and into CouchDB with an openresty based reverse proxy has made things even better, and really fun. This is one of those stacks that feels easy and simple at the same time. (Ref:https://www.infoq.com/presentations/Simple-Made-Easy).
⬐ karmelappleAny guidance on moving from Cloudant to CouchDB? Are you hosting it yourself? If so, has the amount of maintenance been more than you expected, or was it mostly setup time and then forget about it?⬐ azr89Yup, hosting it ourselves. Its a peach. There are few things that it doesnt come with out of the box - clustering, Full text search, geoindexing, chained map reduce, auto compaction, index auto-updation. Once thats done, if anything it was more forget about it than Cloudant, which bills on requests / thoroughput. This can catch you out because continuous replications between databases on the same cloudant account are also counted as requests and billed as such. And continuous replication is very chatty. So if you have a particularly creative multi-master setup, like a per user db -> masterdb kind of thing going, this can eat up your thoroughput / push up your bills with no practical benefit.Its really openresty + couch that does it for me. The idea of writing security / validations / routing etc right into ngnix combines beautifully with the CouchDB way of thinking.
⬐ skrugerWe (Cloudant) recently changed the pricing model to help with this. You can now take a fixed-cost plan that charges based on reserved throughput capacity instead of metered use. This should help with the replication scenario. Seehttps://www.ibm.com/blogs/bluemix/2016/09/new-cloudant-lite-...
Stefan Kruger, IBM Cloudant Offering Manager
⬐ kocoloskAh, yeah, you weren't the only one bitten by that. We actually went and changed the Cloudant metering model recently so that you're billed on provisioned throughput rather than total request volume. You get dramatically more predictable billing, with the tradeoff that clients need to handle a 429 Too Many Requests response if the Cloudant instance is under-sized. More here:https://www.ibm.com/blogs/bluemix/2016/09/new-cloudant-lite-...
Rich Hickey gave one of my favorite talks that I recommend to all programmers no matter which language they code in:
I prefer to go with Rich Hickey's definition of "simple" (https://www.infoq.com/presentations/Simple-Made-Easy).That's why I chose Elixir for our product, and am so glad I did; it may be shiny and new, but it's dead simple.
The "boring" familiar choice would have been Ruby / Node, etc.
I think the problem is when people jump on shiny new bandwagons just because of the shiny factor. When instead they should ask: "Does this shiny new technology radically simplify something that is currently complex and is at the core of my application?" (again, going with the above talk's definition of "simple")
Nice article but i think it touches two problems, but then offers a solution to one.Every program has a code structure. Certain programs have better code structure than others. These are properties independent from the programming language. Javascript evolved from a single entry point, being the [in]famous $.ready() to set behaviors of some html elements, to full blows ES6 single page applications.
It all started as a toy language.
But it simplicity is also its flaw: it enables every human with a not so deep understanding of computer architecture to write a button that changes color on click. The absence of a type system and a solid class paradigm (introduced in ES6) spoiled programmers to pass any object down to any function breaking well known software paradigms: Law of Demeter (https://en.wikipedia.org/wiki/Law_of_Demeter), Open/Close Principle (https://en.wikipedia.org/wiki/Open/closed_principle) and the Liskov Substitution Principle (https://en.wikipedia.org/wiki/Liskov_substitution_principle).
I'm in the Web space professionally from 15+ years and those are the 3 rules i see JS devs break the most, generating complected code (for more understanding of the term have a look at https://www.infoq.com/presentations/Simple-Made-Easy ), hard to maintain and extend like the example shown in this article.
The advice to build interfaces around data structures, proposed as solution, is no different than the Liskov Substitution Principle.
The other problem the article cites is the event loop.
At the time o $.ready() there was no event loop. Developers were just attaching functions to user events: clicks, hovers, blurs, focus. Just a direct mapping between an element and a function. You can simply come to the conclusion that the trigger and the action to be performed were not loosely coupled, but indeed tight together. Easy, yet not scalable.
Tieing events to the dom structure was another sin opening more questions: should an element that is not interactable fire events? bubble them ? every browser had its own answer to those questions. Things got even more complicated with single page applications which html element in the page can be added and removed. So here comes the event loop, like other well known ui stacks did in the past.
The concept of an event loop is not a novelty, it is indeed bound to the architecture of our computer: clock cycle, interrupts, kernel events. In the case of windows is the well known WPF (https://en.wikipedia.org/wiki/Windows_Presentation_Foundatio...) which has, among a lot of other things like any Microsoft product, the concept of a dispatcher that is central to the flux architecture.
In 2015/2016 with React/Flux Javascript and the Web is moving out of puberty, enabling developers to write clean, decoupled, extensible code. Thus no all devs are ready to grasp those architecture that are so obvious in other ecosystems. To cite Poul-Henning Kamp in A generation lost in the bazaar (http://queue.acm.org/detail.cfm?id=2349257):
"So far they have all failed spectacularly, because the generation of lost dot-com wunderkinder in the bazaar has never seen a cathedral and therefore cannot even imagine why you would want one in the first place, much less what it should look like. It is a sad irony, indeed, that those who most need to read it may find The Design of Design entirely incomprehensible."
my 2 cents
It's a pretty nuanced phrase and difficult to replace. I might make the case that "easy to reason about" <=> "simple" in the sense that Rich Hickey uses it[1] but that doesn't do anything for the verb itself.The phrase has a high correlation with subjects that are themselves highly correlated with smug proponents; functional programming is one of the greater ones of these.
Personally I like the phrase. Then again I self-identify as a (non-smug) SmugLispWeenie[2] so of course I like it.
[1] https://www.infoq.com/presentations/Simple-Made-Easy [2] http://web.archive.org/web/20160709054130/http://c2.com/cgi/...
Good luck my good friend with having tied your professional fortune to a small company that you are not affiliated with. This is not politics, this is simply dangerous and I do feel that way every time I see someone with a copy of Sublime. Since I'm a lecturer, I see this issue of lock-in and easy vs. simple/powerful a lot. I'm not taking this lightly, I want the best for my fellow professionals that are just too young to know better. You personally, might be older and more experienced, and I do not have a grudge with your opinion. I was simply stating mine for the reasons given without trying to step on your foot.As for simplicity, there is nothing that I have seen in any editor that is simpler than VIM modal editing or a LISP-machine to do everything. Having a shiny GUI is inherently not simple, but complex.
If you are not familiar with yhe original meanings of these terms, there's a qualified speaker: https://www.infoq.com/presentations/Simple-Made-Easy
That a tool is not easy in the beginning is ultimately irrelevant if it is simple. That is, if you've got enough time to master and profit from it. Which is what every professional software engineer has.
⬐ CJeffersonVIM's modal editing isn't remotely simple. There is a huge language to learn, and most keys do not form useful patterns which are easy to remember.The problem with "you need to invest the time, trust me", I'd the same argument can be used for vim, Emacs, sublime, atom, vscode, eclipse, intellij, and any other editor. I can't invest the time in all of them to become expert.
The difference with Emacs and vim is that they require a sizable time investment just to become competent, as they refuse to fit into the OSes they are running in (in the case of windows and Mac).
⬐ preek⬐ oblioWell, to make a long story and potential flame war short: My original post was not about VIM or Emacs. It was stating happiness about an editor (Lime) that tries to be easy to get started, yet is open source.⬐ krylon> VIM's modal editing isn't remotely simple.While it is highly non-intuitive at first, one can learn the basics in a day or two, from then on it's mostly transferring what you learn to muscle memory. I suppose one can do more advanced stuff in vim that is more complex to learn, but the basics are pretty easy. (Full disclosure: I used to to use vim for a couple of years but switched to emacs about ten years ago. I still use vi for quickly editing a config file on a regular basis.)
> As for simplicity, there is nothing that I have seen in any editor that is simpler than VIM modal editing or a LISP-machine to do everything. Having a shiny GUI is inherently not simple, but complex.I'm a Vim user. But it's exactly this kind of thing that pushes newbies away. Yes, Vim is "simple" conceptually. But in this real world we live in, Vim often makes things more complicated. It's one more thing to learn - and a weird one.
On top of that, Vim's architecture is ancient and not everything has aged gracefully.
⬐ preek⬐ falcolasI concur. That's why the only good thing that I said about VIM is the modal editing which is the most pleasing and efficient mode of editing text that I have ever seen.However, all your points are very correct! That is why I have switched to Emacs where I can still have full VIM modal editing with the other issues you mentioned not being an issue. Emacs has a mode called 'evil' which fully emulates VIM.
Best of both worlds^^
> Good luck my good friend with having tied your professional fortune to a small company that you are not affiliated withYou say that as if Sublime HQ Pty Ltd were to suddenly go out of business, the editor is immediately and completely useless.
This is obviously not the case, in any way, shape or form. It could go out of business tomorrow, and Sublime Text would be perfectly usable (and extensible) until the OSes changed in a way which stopped it from working.
Being open source provides no more guarantee of future development than being closed source does.
⬐ KarunamonThat's just it - I've done nothing of the sort. Sublime has no "unique" features that don't have equivalents in form and function on other editors.So this "lock in" simply does not exist in the case of Sublime.
That naturally leads to the question of "Why it, and not a free alternative?"
I said it elsewhere in this thread, but the main reason I'm on Sublime and not Atom or an equivalent competitor is speed. It's fast, it's developed conservatively, and watching other editors hitch and stutter when they open large files or scrolling or start up or process syntax highlighting probably doesn't have much time impact on my productivity, it does cause a great deal of annoyance, hence stress, which probably does impact productivity in some way.
The other reason is that it lacks in bloat, which to me, means it lacks a ton of features I will never use, something I cannot say about Vim (macros, registers, hundreds of ancillary commands) or Emacs (an entire Lisp vm) and their associated complexity. However, it can be trivially extended with Python, which means any functionality it lacks has likely been worked around by someone in the community.
On top of all that, the author has made indication that he'd rather see the editor go open source than be abandoned[1], but I don't share the common belief that no updates for years means "abandoned" either.
⬐ audunw> Good luck my good friend with having tied your professional fortune to a small company that you are not affiliated with. This is not politics, this is simply dangerous and I do feel that way every time I see someone with a copy of Sublime.This is just wild exaggeration. It doesn't take more than a few weeks or so to become reasonably productive with another text editor. We like to think that the many plugins and shortcuts we build up over years of using an editor adds like 100% speed increases, while at best its increments of a few fractions of a percent.
And most of us developers are probably familiar with at least two editors anyway. Personally I'm intimately familiar and productive with both emacs and sublime, but still prefer sublime. If sublime were to suddenly close down shop and not release their sources, I could switch on a dime.
> As for simplicity, there is nothing that I have seen in any editor that is simpler than VIM modal editing or a LISP-machine to do everything.
In theory, yes. In practice, I've found it much more complex to work with emacs plugins than with Sublime plugins. My conclusion is that overly simple languages like LISP just transfer complexity from the language itself to the code that you're writing.
I'm sure some people find a kind of simplicity there that they like, but people are different.
VIM modal editing is also a thing that may be nice to some people, but personally I find modes to be annoying. It's this state that I always have to keep in sync between me and the editor, and I don't like it. I get the point and the benefits, and I've tried several times, but it just doesn't click for me. So I don't experience that as a simplicity.
> Having a shiny GUI is inherently not simple, but complex.
I wouldn't call Sublimes GUI shiny. In fact it's quite minimalistic. Even more so than Emacs' GUI if you ask me, especially once you've added all the plugins to match functionality.
Again, it's something about the transfer of complexity. In theory, in its base implementation, Emacs is simpler because it makes few assumptions. But this transfers a lot of complexity to plug-in writers, because you get conventions instead, which often causes problems when plug-ins interact.
⬐ ue_>My conclusion is that overly simple languages like LISP just transfer complexity from the language itself to the code that you're writing.Can you give some examples please? Python is even simpler than CL however I don't regard it to be transferring any complexity to the programmer.
I fear you will be unable to recognize when that burger was your choice and when it was a reaction. You probably won't notice. And that is harmless.I also fear you will be unable to notice in which areas of life and information the distinction between choice and reaction is harmless and which it isn't.
Of course, I'm not talking about "You" you, but just people. Me as well. I feel we are widening the field of unconscious decisions and I see that as inherently bad - in my fellow humans as well.
You could say that Plato wanted us to make easy things simple (link for distinction: https://www.infoq.com/presentations/Simple-Made-Easy).
I believe this to be a move in the opposite direction. We should have a care.
⬐ ubercoreTo my mind, leading a simple life is enjoying a burger at a restaurant/bar I frequent already. Simplicity _is_ accepting that Google algorithmically noticed a trend and just helped me do things I already do.⬐ Eupolemos⬐ tekromancrBefore replying, you could at least have made an effort to understand what I meant with the distinction between simple and easy.If you do not care what I say, why even reply?
⬐ verytrivialSorry, who's mind? It sound like you are renting it out.⬐ orpheansodality⬐ KoshkinDo you never use digital tools to outsource mental effort? Seems like a similar argument could be made for using a calculator.⬐ ocdtrekkie⬐ ubercoreCalculators provide you a completely fair assistance with your query. There is zero bias in a calculator. If you ask it what two plus two is, you're going to get four.Google is designed to sell ads, and subtly influence your behavior towards the most profitable results. Please do not confuse a fact-based tool with an ad generator.
⬐ euyyn> subtly influence your behavior towards the most profitable resultsThis is the very common theory that a company will (shadily) try to offer you a worse product to make more profit. It fails to account for competing companies that would jump on that opportunity to offer their better product, and get the market share.
But what's funny here is that the suggested alternative is to not get any product at all. As in: "Poor OP, didn't realize that it wasn't really him who was enjoying that burger he was enjoying."
⬐ ocdtrekkie"Worse" is often subjective. And the problem is often just the removal of the possibility of a better product to take hold. For example, Google prioritizes Google services. It gets you on as many Google services as possible. Let's use, say, that it pushes you towards Play Music when you search for songs.Maybe Play Music is the best thing. Maybe it is not. Neither of us can answer that. But if a definitively better product comes along it will have no way to make a foothold because Google is still pushing everyone to their own product, from their other product (Search), and even when people try your product, if they use Google's other products, they'll tend to stick to other Google products.
Honestly, the worst problem with companies like Google is vertical integration. The ability to provide a wide product line where you integrate best with other products your own company makes has an incredibly chilling effect on competition, and therefore, innovation.
And if your theory that companies prioritizing results for profit would lose to companies that always prefer the best products, why is DuckDuckGo still in what... fourth or fifth place?
⬐ euyyn> And if your theory that companies prioritizing results for profit would lose to companies that always prefer the best products, why is DuckDuckGo still in what... fourth or fifth place?You'd need to argue that DuckDuckGo's search results are better; I don't think they are. That's what made Google first among many competing search engines, before there was even a clear business model in it. Today the incentive to outperform is bigger.
If a product Y definitely better than X comes along, and only Google Search fails to rank it higher, people will start thinking "I rather search on Bing too, as it finds better products in this category".
Presumptuous much? Comments like yours are what makes discussions like this so difficult, and so much less interesting.Yes, traps are usually designed so that it is simple to get into them. It is not that cheese is bad, it is that you are trapped.⬐ blhackAre you comparing something designed to kill a rat with something designed to help me go to a burger place I like, or leave on time for work?⬐ marcosdumayYes. How does Google make money of this service again?⬐ Sargos⬐ mikestewBy having burger places pay money to get on the list of places it helpfully gives us when we want to eat a tasty burger. I still get my tasty burger.Yes, because when one has already decided that feature $FOO is a trap, any further discussion is likely to be limited to describing how "yes, just like a trap is designed to...so is the thing we're talking about" whether the analogy is apt or not. Something something supporting a narrative.That's the thing though. I reject the notion that you ever actually make a choice. I would posit that 100% of the actions you take are simply the deterministic reactions when the current world state is filtered through your brain. Then, after the fact, your brain gets busy inventing a reason that you took a particular action and calls it a "choice" when really you were just going to do what you were going to do anyway."I ordered this burger because I was hungry and it tastes good" vs "I ordered this burger because Google was able to successfully predict that I would be receptive to having burgers, or the idea of burgers, placed in my environment"
⬐ samastur⬐ empath75In effect you argument is that we don't have free will, right?I wonder what is then causing inefficiency when we read restaurant's menu and can't decide what we will have.
I'm with those who think we make choices and decisions far less often than we think, but that we still do make them.
⬐ princeb⬐ bbctoli am no longer intrigued by the privacy discussion but the actual possibility that we are just consciousnesses controlled by the google hivemind.this is like absolutely full on plugged into the matrix world. and we're living right in it.
these guys are like the ones who've taken the red pill, and gone on to find out how far the rabbit hole is going.
(edit: i'm even more intrigued by the possibility that the future is not just the matrix singularity, but an oligopoly of several large singularities, all fighting to plug us in)
Sure, but philosophical musings on the nature of free will aside, there's a practical worry about the amount of power a private company has over your actions. I'd rather be ordering burgers because they taste good than because a company wanted me too--I expect this will lead to greater happiness for me in the long run.⬐ majewskyYes, but only because your happiness metric maximizes when you exercise your freedom of choice.Other people's happiness metrics work differently, and all popular web services are popular precisely because they satisfy the unconscious desires of the majority of people.
I think for quite a large number of people, allowing AIs to make decisions for them will probably be better for them.⬐ tedunangst⬐ WallowC_33Imagine some day your doctor advises to cut back on burgers and alcohol. Is Google going to incorporate that advice in its bar recommendations?⬐ icebraining⬐ iniminoWhy not? As long as you're clicking their ads, they'll make money regardless of whether you're buying a burger or a salad.⬐ aqzmanIs it Google's responsibility to? I would say no. If algorithms detect that an individual is going to a bar every Monday and Thursday night, and then starts providing information about said bar on Monday and Thursday nights I don't see the problem.But I think it would be a problem if every Monday and Thursday night Google Now started providing information about AA meetings in the area, instead of bar information. It's up to the user to make the choice, Google Now just detects trends and then displays information based on those trends.
I go to the gym every Monday, Tuesday, Thursday, and Friday morning. And each of those mornings Google Now tells me how many minutes it will take me to get to the gym from my current location. Should Google Now start giving me directions to the nearest breakfast place instead? No, not unless that starts becoming my pattern.
⬐ daveguyIt may not be their responsibility (although if it had that information it would be the morally correct choice). However, regardless of the responsibility -- the CEO of the company saying "we're going to make your life better!" by an AI pushing products is almost certainly not going to make your life better.> Should Google Now start giving me directions to the nearest breakfast place instead?
That may depend on how much Waffle House pays for advertising, and that is the problem.
⬐ tedunangstIf you're trying to change your lifestyle, it's more difficult when you have a bad friend constantly enabling the behavior you're trying to cease.Google may not have a responsibility to be a good friend, but personally I'd prefer not to have a bad friend always following me around, thus I'm a little less excited about this feature.
⬐ whonutYou can just tell it to stop. It's not hard.⬐ kodablahI think many would rather tell it when to start instead. What's hard about telling it to stop is when you can't tell it's started because it's something more nuanced than the obvious diet plan.That rather depends on the objectives of the AI.If you replace "AI" with "marketing" would you still make that statement?
⬐ oldmanjay⬐ convolvatronIf you replace "ai" with "your spouse" would that change be as intellectually useless?don't you think thats a pretty severe statement wrt to free will and agency? if i'm just a consumer wired up to a machine thats deciding whats best for me (even with the best of intentions), doesn't that make me less human?should I just be a actor playing through a set itinerary of vacations and movies and burgers and relationships? maybe you think its that way already, except less perfect than it might be, but thats a pretty frightening notion to me.
⬐ pjlegatoThe same argument was historically made to justify slavery.⬐ majewsky⬐ Super_JamboAnd to justify the continued existence of the electoral college.When the AIs are working in service of corporations this seems incredibly unlikely.We already see what happens when peoples decision making is coloured by mass media advertising. An obese population trapped by debts taken out to fuel consumption.
It is in other peoples best interests for you to work like a slave, be addicted to unhealthy habits & run up vast debts in order to buy their products.
We keep allowing those with power to distort the markets gaining themselves more money and more power at the expense of the little guy. I don't see any reason why AI in the service of the powerful will do anything but accelerate that.
Given all the other points in life where, despite my awareness, I don't have much choice, how is an AI just directing me really any different?My culture, education and skills limit what work I can do.
Our culture places limits on a vast number of experiences. On the road and the only thing is fast food? Welp, eating fast food. Live somewhere that only has one grocery store or cable provider?
I don't really see AI in the form Google is peddling as really all that much different. We're just 'more aware' that the world around us is really guiding us.
I may be somewhere new, and can only see the immediate surroundings without a lot of exploring. And let's be real, in the US, most cities are the same when it comes to restaurants/hotels and such. There are differences in culture but we don't usually see them if we're just visiting. Not in a way that matters.
Google will let me know that the things I prefer back home? there are equivalents nearby.
Fencing ourselves in is what we do. Who knows, perhaps a digital assistant would help us stick to our personal goals and decisions better. Rather than just having to accept what's there.
⬐ cm2012Almost all decisions are unconscious decisions. whether or not Google is involved. We usually rationalize our reasoning after the decision is made.⬐ jccalhoun> I feel we are widening the field of unconscious decisions and I see that as inherently badI'm curious why you think this is bad. I don't necessarily think it is good but I also don't necessarily think it is actually happening
⬐ Eupolemos⬐ JackFrWhich news-sources do you use?Which news-sources are you going to learn about?
Which news-sources are you for some reason very unlikely to encounter?
Now apply a real-time AI filter-bubble, able to also include government policies in its decision-making, onto those questions.
I believe the most important thing in life is thinking. I believe a key element of thinking is looking at "easy stuff", the stuff we just live with every day and don't think about, and for some reason be forced to think about it and make it simple.
Take the Snowden-leak. We lived a nice life being the good guys and that kind of surveillance was publicly thought of as conspiracy theories. Suddenly we were forced to look at what was going on. How much of it are we okay with? On the grounds of what principles and tradeoffs? This is all very unpleasant, but we're all better off for facing those questions and work towards new principles. We take a chaotic gruel of cons and pros, and try to hammer them into a few simple principles our societies may function by. For instance, the separation of power into 3 has served us well.
I fear that we end up in a world where raising such unpleasant questions becomes almost impossible - and we'll never even notice. Not because of AI (I believe AI to be inevitable and fascinating) but because of the way AI is used.
Living a life assisted by an AI, made and paid for by someone else, seems like the epitome of naivete to me.
> I fear you will be unable to recognize when that burger was your choice and when it was a reaction.Maybe the illusion is that it was a choice . . .
⬐ tedunangst⬐ Ph0XNot far from the mark. People have quite different behaviors when asked "what do you want?" vs a constant stream of "do you want X?" questions.I'm sorry but that just sounds like blind fear mongering. What you're saying is vague and doesn't really mean much.It's like saying we shouldn't use prescription glasses, or medication, or cars, because it's not "us".
Humans invent all these tools and systems to improve and optimize our life. Make our vision better. Make our health better. Make us move around faster. In the case of AI, make us do perform certain things more efficiently.
Imagine it wasn't an actually computer. Imagine it was a personal secretary you had that gave you the EXACT same information. Gave you your flight information, turned on the light when you asked, gave you the weather and your schedule. Would you think that was wrong? That this isn't "you"? No, it's just optimizing your life, but now available for a wider population rather than rich people.
⬐ SylosWhat he's saying is that this is not "humanity inventing something to make life better". It's a company inventing something to make money.And it's not a simple product like glasses where you pay with money and then they improve your vision. It's a product which goes far beyond your understanding and for which you don't pay money.
Google isn't interested in making your life better. What they are interested in is getting you to believe that they want to make your life better and to then recommend going to that bar, because the bar owner has given Google money to advertise for the bar.
Yes, you might actually like that bar, but Google isn't going to recommend going there in intervals which are beneficial to you. They'd rather have you go there a few too many times. Because that's what makes them money. It's not improving your life, which makes them money. Their AI will always work against you, whenever it can without you noticing.
⬐ mcguireImagine that you were trying to quit smoking and your electronic secretary kept updating you on the cheapest place to find your favorite cigarettes? With no way to tell it not to do that.⬐ Ph0X⬐ EupolemosSo your issue is your secretary doing it's job poorly?First, there is a way to tell it to not do that. With Google Now, you simply tap the menu and say "No more notification like this". With the assistant, you will probably be able to ask directly.
Second, let's be honest, humans fail pretty often too, so that's just a weak argument.
Lastly, I think it's unfair to dismiss a new technology just because it could maybe fail, without having even tried it.
⬐ Terr_> So your issue is your secretary doing it's job poorly?I think the real issue is the casual deception which you just fell for: It isn't "your" electronic secretary, and the thing it just did might actually be a "good job" from the perspective of those who control it.
⬐ ethanbondHow about if the system is working exceptionally well, you're a depressed person, and the next ad you see is auctioned off between a therapist, a pharma company, and a noose supply store in the 100ms it takes to render your MyFaceGram profile?The awful success cases are far more interesting than the awful failure cases.
⬐ dsaccoI have no problem with ads for therapists or pharma companies competing for advertising space in front of me because they have algorithmically determined that I am a qualified lead. That actually sounds great from a mental health perspective.Your noose example is pretty contrived, however.
⬐ ethanbondObviously the first two aren't the problematic ones. The issue is that an algorithm wouldn't know what distinguishes those from the third, obviously.How about sleeping pills? Opiates? Local extortionist cult?
⬐ euyynI think that algorithms, and AI specifically, are perfectly able learn what distinguishes those. Maybe even better than someone who might not be in their best state of mind.⬐ ethanbondThe handwaviness is telling. Why would an algorithm or its creators even care about the difference? The highest bidder is the highest bidder.⬐ euyynBecause the whole of Google's ad business stands on people wanting to click on the ads shown, and buy the products offered through them. That's why they spend resources on detecting misleading or fraudulent ads, which by your reasoning they wouldn't care about as long as they paid. PR is very important for this business to be sustainable: If the goal was for every user to click through one ad, and then never again, that might not even pay one engineer's salary.⬐ ethanbondWhat's misleading or fraudulent about those ads? Maybe you mean "morally reprehensible," in which case I ask where you draw the line between the morally reprehensible (auctioning off the method of suicide to a depressed person) and the morally questionable (say, auctioning off the final bankrupting car purchase to a financially irresponsible person)?⬐ euyynDetecting misleading and fraudulent ads is just an example of things they wouldn't spend resources on, if following your reasoning of "short-term money is the only thing they care about."There's not only the "morally reprehensible" metric ("Don't be evil"); there's also the "absolute PR catastrophe" metric that printing such an ad for a rope would mean.
I think you misunderstand me by a large margin.I'm not saying we shouldn't use AIs. We should, however, think about how we use them.
To build on your example, what are the dangers of having a personal secretary on the payroll of anyone but you?
What I am expecting from this is a super devious filter bubble - because that's how you make money. Google's old slogan "Don't be evil" is long gone. "For a greater good" might be more on point.
⬐ eli_gottlieb>In the case of AI, make us do perform certain things more efficiently.What does the Google Assistant help me do more efficiently? In all honesty, I can't figure it out. I don't need or want a secretary, and I can do written planning for myself.
I need less paperwork and fewer web forms and identities, but the Google Assistant only promises more of that crap.
I'm never buying one. It's a sacrifice of privacy for zero to marginal gains in convenience.
⬐ xanderstrike⬐ jerfIf you can't come up with uses for it, you weren't its target audience in the first place.⬐ eli_gottliebSure, but then I'm not sure anyone I know is the target audience. Not that many people really need or want personal secretaries in the first place, let alone want to make financial and privacy sacrifices so they can have a mentally retarded AI pseudo-secretary.Most people get through their daily lives just fine on their own.
⬐ j2kunIgnoring your derisive tone, the statement "most people get through their daily lives just fine without it" applies to every new technology. Yet here we are, typing away on the internet."Imagine it was a personal secretary you had that gave you the EXACT same information. Gave you your flight information, turned on the light when you asked, gave you the weather and your schedule."In your metaphor, you are implicitly paying the secretary, so the secretary is incentivized to maintain your interests.
How much have you paid Google for its free services?
Your metaphor is inapplicable. You don't have a secretary telling you these things; you have a salesman trying to sell you things, and the salesman is getting smarter every day while you aren't. Not the same thing at all.
⬐ witty_usernameGoogle earns most of their money through ads.⬐ pjlegatoYes. Google is selling you, to advertisers, quite literally.When you aren't paying anything for something of value, YOU are the product.
⬐ dragonwriter⬐ jerf> Google is selling you, to advertisers, quite literally.No, that would be slavery, which is illegal.
Google is selling advertising space on various channels that you provide in exchange for Google services to advertisers.
> When you aren't paying anything for something of value, YOU are the product.
No, when you aren't paying money for something of value, you are probably paying something else of value for it; often, something that the person with which you are trading is then selling for money, making you a supplier of an input to the good or service they are selling for money.
That's why I called them a salesman. They sell things. Their interests are not simply your own.It seems to be a theme here today... a company can't serve both advertisers and customers. In the end, one of them has to win, and given the monetary flows, it's not even remotely a contest which it will be. https://news.ycombinator.com/item?id=12644507
⬐ Ph0XThey don't sell things. They forward you towards people who do sell things which you may be interested with. You're free to ignore it, and if you're not interested in what they're showing you, that means they failed at their job.It's funny how bad of a stigma ads have gotten, but at the core, if you think of it, it's not necessarily a bad thing. Think of a friend recommending you a restaurant, a new game to play, a movie to go watch. In that case you'll be super interested, but now if this AI who probably knows your taste better than your friend suggests you something, you are instantly turned off and annoyed.
I think the root cause of this is that there is so much mediocre ads out there that ruin it for all. Your mind just blindly blocks all ads now.
Rich Hickey "Simple Made Easy" https://www.infoq.com/presentations/Simple-Made-Easy
⬐ muhic+1 for Hickey's talks. The Changelog compiled a selection of the best: https://changelog.com/rich-hickeys-greatest-hits/⬐ vram22His "Hammock Driven Development" talk is good too:http://jugad2.blogspot.in/2016/03/tech-video-rich-hickey-ham...
A couple of comments there by me.
Simple Made Easy is one of those talks that never gets old to me. Never heard anyone talk about the power of reducing complexity in such a clear way.Here's the link for those who are interested. https://www.infoq.com/presentations/Simple-Made-Easy
⬐ cgagThis is my favorite. I also really like hammock-driven development (https://www.youtube.com/watch?v=f84n5oFoZBc)
Simple Made Easy by Rich Hickey
⬐ lgasI would say all of "Rich Hickey's Greatest Hits":
As Rich Hickey argues[1], 'simple' can be an objective statement. Though I agree that without an explanation of what exactly makes this library 'simple', the better word may be 'easy'.
As a side note in his talk "Simple Made Easy" (https://www.infoq.com/presentations/Simple-Made-Easy, around minute 42) Rich Hickey mentions, that conditional statements are complex, because they spread (business-)logic throughout the program.As a simpler (in the Hickey-sense) alternative, he lists rule systems and logic programming. For example, keeping parts of the business logic ("What do we consider an 'active' user?", "When do we notify a user?", etc...) as datalog expressions, maybe even storing them in a database, specifies them all in a single place. This helps to ensure consistency throughout the program. One could even give access to these specifications to a client, who can then customise the application directly in logic, instead of chasing throughout the whole code base.
Basically everyone involved agrees on a common language of predicates explicitly, instead of informally in database queries, UI, application code, etc...
But Hickey also notes that this thinking is pretty "cutting-edge" and probably not yet terribly practical.
⬐ goldbrickIt can work. My current company uses a rule system to represent most of our business logic since it is so dynamic. The downside is that we have to rebuild the entire graph into memory (times the number of threads, times the number of app servers) every time anything changes (which is constant).Facebook wrote about rebuilding a similar system in Haskell that only changes memory incrementally, so it's definitely possible to do better.
⬐ ComNikInteresting note, thank you. Are you referring to "Sigma" https://code.facebook.com/posts/745068642270222/fighting-spa... ?⬐ goldbrickThat's the one.
The point is not about "hand-coding" at all.It's about reading the code, and having a good mental model of what is happening. This is the point Rich Hickey tried to drive home with his talk "Simple Made Easy".
https://www.infoq.com/presentations/Simple-Made-Easy
If you are a developer and haven't watched this yet, you really, really should. Very important distinction to keep in mind any time you are writing software.
Haven't read the Active Record source code, but would be interesting to find out where it falls on the "Simple vs. Easy" continuum.
⬐ spacemanmattSimple Made Easy is a really great talk.
If you haven't already done so, listen to this talk by Rich Hickey (the creator of Clojure). This should clear it up for you. https://www.infoq.com/presentations/Simple-Made-Easy
⬐ ilyashThanks! Added link from the post to the lecture.
Here's a very objective and powerful way to measure complexity: dependencies and volatility.Otherwise we're all saying "complex" but not being clear and likely meaning different things.
For example, a lot of people believe that "not easy" = "complex" but as Rich Hickey articulates that's a counterproductive way to think of complexity. (See http://www.infoq.com/presentations/Simple-Made-Easy)
⬐ dustingetz"dependencies and volatility" But what does this even mean? I'm okay with using Rich Hickey's definitions. But I don't recall that in Rich's talk.⬐ AnchorIf your system's design results in your stable components depend on the non-stable (volatile) components, your system is complex. This is because volatile components change often and these changes ripple to your stable components effectively rendering them volatile. Now the whole system becomes volatile, and the changes to it become very hard to reason about - hence complex.Avoiding this problem has been captured, among others, by the Stable Dependencies Principle (http://c2.com/cgi/wiki?StableDependenciesPrinciple), which states that the dependencies should be in the direction of the stability. A related one is the Stable Abstractions Principle (http://c2.com/cgi/wiki?StableAbstractionsPrinciple), which states that components should be as abstract as they are stable.
In a typical jQuery/Backbone kind of app, you've got some data in something like Backbone models and you've got state stored in the DOM. Keeping those two in sync bring complexity in. The React model is simpler (in the non-intertwined sense... see Simple Made Easy[1]) in that you have data in one place, a function that transforms the data to UI and the browser DOM is managed automatically from that.It's not perfect but it reduces complexity.
This reminds me of the talk given by Rich Hickey named "Simple made Easy":
The "Clojurians don't like testing" meme probably has more to do with Rich Hickey's famous "guard rail programming" [1] comment than anything else. Of course, even at the time, the joke within the community was, "Yes, Rich Hickey doesn't need to write tests....you do!"[1] http://www.infoq.com/presentations/Simple-Made-Easy (15:30)
⬐ sheepmullet> The "Clojurians don't like testing" meme probably has more to do with Rich Hickey's famous "guard rail programming" [1] comment than anything else.And Rich Hickey isn't against testing. He was having a jab at test driven design.
Hi there, thanks for the comment. Author here.No, poor technical user is not the entire premise. What I was trying to convey is to give the reader a chance to reevaluate the decision to send parameters that way, rather than trying to accept it as it is. It is hard for experienced people to think that way because they have become accustomed, but most of the time, in programming, we don't realize simpler solutions are possible. It helps to reevaluate from the eyes of a beginner.
Rich Hickey has a great talk on this called Simple Made Easy: http://www.infoq.com/presentations/Simple-Made-Easy
> web application
The blog post mentions getting an article, but basically the web applications nowadays move complexity to the client and see the server as a single API. Having that as a single URL is the natural derivation of that. Any request queries or mutations are sent to that URL.
I have updated the demo link so that it now starts with a real query, rather than an empty page. See an example at: http://bit.ly/1Qa4h00
⬐ pdkl95> we don't realize simpler solutions are possibleI'm not seeing a "simpler solution" - your URL is far more complex, and is probably even harder to parse by people that have learned how URLs work. Making non-technical people learn yet another new way to do things isn't helping.
Also, at some point, you're just going to have a complicated interface. T
> move complexity to the client
It's not your computer, so you don't get to decide how the client handles the page. If you want your content to be read, try actually sending it.
Note that this is a statement of fact, not an opinion about how I wish computers worked. You do not know what the client is doing when it renders a page (adblocking is a common example), so moving complexity to the client unnecessarily is risky. So far I'm still only seeing a search interface, which is (by definition) purely server side.
> sent to that URL
Ok, I think I get what you're excited about: you're reinventing #respond_to/#respond_with[1], so the URL can be reused for different mime-types.
[1] http://edgeapi.rubyonrails.org/classes/ActionController/Resp...
> rather than an empty page.
(by the way - curl complains about that URL. Something about bracket? It may be some advanced feature of curl? No matter, wget is fine)
It's still an empty page.$ wget -O /tmp/page.html 'http://graphql-swapi.parseapp.com/?query=%23%20Welc ... %0A}' $ </tmp/page.html sed -ne '/<body>/,/<\/body>/ p' | sed -e '/<script>/,/<\/script>/ d' <body> </body>⬐ ludwigvanTry this:The query param is just for easy sharing online when you build a query.curl 'http://graphql-swapi.parseapp.com' \ -H 'content-type: application/json' \ --data-binary '{"query":"{ allFilms(first: 3) { films { title, director } }}"}'⬐ belovedeagle> The query param is just for easy sharing online when you build a query.Gee, if only there were a way to encode that data into the URL itself without embedding an almost-JSON document! Someone should invent something like that.
⬐ trowaweeGet outta here, that's nuts.
I strongly disagree with this notion of "simplicity" as being attributable to scarcity of language features. Some of the languages that I felt were the easiest to use had quite a number of language features, but had simple semantics. I think Rich Hickey nailed this in his "Simple Made Easy"[1] talk. Complexity is not about additivity, it's about entanglement.
⬐ bjwbellHow do you have a large set of language features with them not interacting?In Java, serialization and generics interact with practically everything.
In C++, RAII interacts with exceptions, which is the point but isn't exactly pleasant.
⬐ catnaroek⬐ nulltype> How do you have a large set of language features with them not interacting?The ability to write interesting programs in a language comes from the interaction between its features. The real problem is features that interact in unpleasant ways, which almost always results from a lack of foresight on the language designer's part.
> In C++, RAII interacts with exceptions, which is the point but isn't exactly pleasant.
The interaction between control effects (of which exceptions are a particular case) and substructural types (of which C++'s RAII is a very broken particular case) is certainly nontrivial [0], but this doesn't mean we should give up on either feature. Control effects make it easier to design and implement extensible programs. Substructural types allow you to safely manipulate ephemeral resources, such as file handles, database connections or GUI objects.
[0] http://users.eecs.northwestern.edu/~jesse/pubs/substructural...
⬐ bjwbell⬐ i_sNice phrasing, unpleasant was the feeling I was going for.Sometimes I wonder about giving up.
⬐ pron> The interaction between control effects (of which exceptions are a particular case) and substructural types (of which C++'s RAII is a very broken particular case) is certainly nontrivialA nitpick, but what constitutes an effect is rather arbitrary. An effect in the PFP sense is not an operational definition (other than IO) but a linguistic one. This is why I think that handling errors well, handling mutation well and handling IO well are three completely different problems that are only accidentally bundled into one by PFP for no cognitive/empirical reason other than that the lambda calculus happens to be equally challenged by all three.
There is a fourth effect, which is just as operational as IO (and thus a "truer" effect than errors or mutation) and is often the most interesting, yet it happens to be the one that baffles PFP/LC most: the passage of time. This is why there are usually two ways to sleep in PFP languages, one considered an effect, and the other is not (but happens to be much more operationally disruptive, and thus a stronger "effect").
⬐ catnaroekI was talking only about control effects, not I/O or mutation. Control effects are basically stylized uses of continuations, with less insanity involved.⬐ pronI understand. I just said that classifying non-linear transfer of control (whether exceptions or proper continuation) as an effect at all is quite arbitrary, and is just a common usage in the PFP world.Of course, substructural types are also a language concept (that does indeed interact badly with non-local jumps), which is why I said it was a nitpick about the use of the word "effect".
⬐ catnaroek> I just said that classifying non-linear transfer of control (whether exceptions or proper continuation) as an effect at all is quite arbitrary, and is just a common usage in the PFP world.What exactly makes it arbitrary? It's pretty sensible, even if you don't have substructural types.
> Of course, substructural types are also a language concept (that does indeed interact badly with non-local jumps)
Control effects and substructural types don't interact “badly”. They just require care if you want them together. If you desugar control effects into delimited continuations (that is, normal higher-order functions), it becomes clear as daylight how to correctly handle their interaction with substructural types.
⬐ pron> What exactly makes it arbitrary?The word effect in the PFP world denotes anything that a language-level function does which may affect other functions and is not an argument or a return parameter. That definition is not valid outside of PFP/LC, because it defines as effects as things that are indistinguishable from non-effects in other models of computation. E.g. it calls assignments to certain memory cells "effects" while assignments to other memory cells non-effects.
Again, my (very minor) point is that the word "effect" as you use it simply denotes a PFP linguistic concept rather than an essential computational thing. The only reason I mention it is that the word "effect" has a connotation of something that's real and measurable beyond the language. That's true for IO and time (computational complexity, which, interestingly, is not generally considered an effect in PFP), but not true for jumps (or continuations) and mutation.
> delimited continuations (that is, normal higher-order functions)
Again, you are assuming PFP nomenclature. Delimited continuations do not require language-level functions at all, and higher-order functions can be defined in terms of delimited continuations just as the opposite is true. Delimited continuations are no more higher-order functions than higher-order functions (or monads, rather) are delimited continuations. PFP is not the only way to look at abstractions and not the only fundamental nomenclature.
⬐ telPurity can be defined very nicely against the arrows in a compositional semantics of a language and then effects follow as reasons for impurity.This is absolutely just a choice. It all ends up depending upon how you define equality of arrows. You could probably even get weirder notions of purity if you relax equality to a higher-dimensional one.
So, it's of course arbitrary in the sense that you can just pick whatever semantics you like and then ask whether or not purity makes much sense there. You point out that "passage of time" is an impurity often ignored and this is, of course, true since we're talking (implicitly) about "Haskell purity" which is built off something like an arm-wavey Bi-CCC value semantics.
A much more foundational difference of opinion about purity arises from whether or not you allow termination.
I'd be interested to see a semantics where setting mutable stores is sufficiently ignored by the choice of equality as to be considered a non-effect. I'm not sure what it would look like, though.
⬐ catnaroekI don't agree with pron overall, but he does have a point. Termination and algorithmic complexity do matter, and the techniques Haskell programmers advocate for reasoning about programs have a tendency to sweep theese concerns under the rug. This is in part why I've switched to Standard ML, in spite of its annoyances: No purity, higher kinds, first-class existentials or polymorphic recursion. And no mature library ecosystem. But I get a sane cost model for calculating the time complexity of algorithms. And, when I need laziness, I can carefully control how much laziness I want. Doing the converse in Haskell is much harder, and you get no help whatsoever from the type system.As an example, consider the humble cons list type constructor. Looks like the free monoid, right? Well, wrong. The free monoid is a type constructor of finite sequences, and Haskell lists are potentially infinite. But even if we consider only finite lists, as in Standard ML or Scheme, the problem remains that, while list concatenation is associative, it's much less efficient when used left-associatively than when used right-associatively. The entire point to identifying a monoid structure is that it gives you the freedom to reassociate the binary operation however you want. If using this “freedom” will utterly destroy your program's performance, then you probably won't want to use this freedom much - or at least I know I wouldn't. So, personally, I wouldn't provide a Monoid instance for cons lists. Instead, I would provide a Monoid instance for catenable lists. [0]
By the way, this observation was made by Stepanov long ago: “That is the fundamental point: algorithms are defined on algebraic structures.” [1] This is the part Haskellers acknowledge. Stepanov then continues: “It took me another couple of years to realize that you have to extend the notion of structure by adding complexity requirements to regular axioms.” [1]
Of course, none of this justifies pron's suspicion of linguistic models of computation.
[0] http://www.westpoint.edu/eecs/SiteAssets/SitePages/Faculty%2...
⬐ pron⬐ None> Of course, none of this justifies pron's suspicion of linguistic models of computation.Of course. :)
But my view stems from the following belief that finally brings us back to your original point and my original response: there can be no (classical) mathematical justification to what you call linguistic models of computation because computation is not (classical) math, as it does not preserve equality under substitution. The implication I draw from this is not quite the one you may attribute to me such as an overall suspicion, complete rejection or dismissal of those models, but the recognition that their entire justification is not mathematical but pragmatic, and that means that the very same (practical) reasons that might make us adopt the (leaky) abstraction of those models, might lead us to adopt (or even prefer) other models that are justified by pragmatism alone -- such as empirical results showing a certain "affinity" to human cognition -- even if they don't try to abstract computation as classical math.
⬐ catnaroek> because computation is not (classical) mathOf course, computation is more foundational. It's mathematics that's just applied computation.
> as it does not preserve equality under substitution
You just need to stop using broken models.
> but the recognition that their entire justification is not mathematical but pragmatic
I don't see a distinction. To me, nothing is more pragmatic to use than a reliable mathematical model.
> the (leaky) abstraction of those models
Other than the finiteness of real computers, what else is leaky? Mind you, abstracting over the finiteness of the computer is an idea that even... uh... “less mathematically gifted” languages (such as Java) acknowledge as good.
> such as empirical results showing a certain "affinity" to human cognition
Experience shows that humans are incapable of understanding computation at all. But computation is here to stay, so the best we can do is rise to the challenge. Denying the nature of computation is denying reality itself.
⬐ pron> You just need to stop using broken models.No computation preserves equality under substitution. If your model assumes that equality, it is a useful, but leaky abstraction.
> Other than the finiteness of real computers, what else is leaky?
The assumption of equality between 2 + 2 and 4, which is true in classical math but false in computation (if 2+2 were equal to 4, then there would be no such thing as computation, whose entire work is to get from 2 + 2 to 4; also, getting from 2+2 to 4 does not imply the ability to get from 4 to 2+2).
> Experience shows that humans are incapable of understanding computation at all.
Experience shows that humans are capable of creating very impressive software (the most impressive exemplars are almost all in C, Java etc., BTW).
⬐ catnaroek> The assumption of equality between 2 + 2 and 4, which is true in classical math but false in computationUsing Lisp syntax, you are wrongly conflating `(+ 2 2)`, which is equal to `4`, with `(quote (+ 2 2))`, which is obviously different from `(quote 4)`. Obviously, a term rewriting approach to computation involves replacing syntax objects with syntactically different ones, but in a pure language, they will semantically denote the same value.
Incidentally:
0. This conflation between object and meta language rôles is an eternal source of confusion and pain in Lisp.
1. Types help clarify the distinction. `(+ 2 2)` has type `integer`, but `(quote (+ 2 2))` has type `abstract-syntax-tree`.
> very impressive software
For its lack of conceptual clarity. And for its bugs. I'm reduced to being a very conservative user of software. I wouldn't dare try any program's most advanced options, for fear of having to deal with complex functionality implemented wrong.
⬐ pron> Using Lisp syntax, you are wrongly conflating `(+ 2 2)`, which is equal to `4`It is not equal to 4; it computes to 4. Substituting (+ 2 2) for 4 everywhere yields a different computation with a different complexity.
> but in a pure language, they will semantically denote the same value.
The same value means equal in classical math; not in computation. Otherwise (sort '(4 2 3 1)) would be the same as '(1 2 3 4), and if so, what does computation do? We wouldn't need a computer if that were so, and we certainly wouldn't need to power it with so much energy or need to wait long for it to solve the traveling salesman problem.
> For its lack of conceptual clarity. And for its bugs.
That's a very glass-half-empty view. I for one think that IBM's Watson and self-driving cars are quite the achievements. But even beyond algorithmic achievements and looking at systems, software systems that are successfully (and continuously) maintained for at least a decade or two are quite common. I spent about a decade of my career working on defense software, and that just was what we did.
⬐ catnaroekIf you can't distinguish object from meta language, I'm afraid we can't have a reasonable discussion about computing. This distinction is crucial. Go get an education.⬐ pronIf you don't understand what I'm saying -- and that could be entirely my fault -- you can just ask. If you (mistakenly) assume that by 2 + 2 I mean the expression "2 + 2" rather than the computation 2 + 2, why not assume that you may have missed something (which is the actual case) rather than assume that I don't understand the basics (which is not)?Since I don't wish to discuss this topic further with rude people, but I do wish to explain my point to other readers, I'll note that the entire concept of computational complexity, which is probably the most important concept in all of computer science (and is at the very core of computation itself -- there can be no computation without computational complexity), is predicated on the axiom that in computation 2+2 does not equal 4 (in the sense that they are "the same"), but is computed to be 4. If 2+2 were actually 4, there would be no computational complexity (and so no computation).
As a matter of fact, an entire model, or definition of computation (another is the Turing Machine) called lambda calculus is entirely based on the concept that substitution is not equality in the theory of computation, by defining computation to be the process of substitution (which is what lambda calculus calls reductions). If 4 and 2+2 were the same (as they are in classical math), there would be no process, and the lambda calculus would not have been a model of computation but simply a bunch of trivial (classical) mathematical formulas.
Indeed, some people confuse the LC notation with classical mathematical notation (which it resembles), and mistakenly believe that 2+2 equals 4 in LC in the same sense that it does in math (I assume because the same reductions preserve equality in math). This is wrong (in LC reductions do not preserve "sameness" but induce -- or rather, are -- computation). To their defense, LC does make this fundamental distinction easy to miss in hiding 100% of what it is meant to define -- namely, computation -- in operations that classical mathematicians associate with equality[1], and in itself does not have a useful formulation of complexity[2]. Nevertheless, those people might ignore computational complexity, which is the same as ignoring computation itself, and while they may turn out to be great mathematicians, you would not want them specifying or writing your traffic signal or air-traffic control software.
[1]: Although I believe most notations take care to not separate consecutive reductions with the equal sign but with an arrow or a new line, precisely to signify that reduction is not equality. Also, unlike in math, LC reductions are directional, and some substitutions can't be reversed. In this way, LC does directly represent one property of time: it's directionality.
[2]: The challenge complexity poses to LC is great, and only in 2014 was it proven that it is not just a model of computation but one of a "reasonable machine": http://arxiv.org/abs/1405.3311
⬐ telComputation is something different. Models like call by push value make this very clear. LC does as well, though, but LC tends to be joined up with an equality semantics which intentionally sweeps computation under the rug for simplicity.This is a big hairy problem in untyped LC, though, since untyped LC has non-termination and therefore is not confluent. This is what I mean by taking non-termination seriously is one way to force "time" and "computation" back into models. It means that LC has no beta-equivalence the same way that, say, simply typed LC does.
So anyway, you're wrong to say that LC has no notion of complexity—people count reduction steps all the time—but right to say that often this is intentionally ignored to provide simpler value semantics. It's foolish to think of this as equivalent to LC, though.
This paper is interesting. I think what they prove was at least folk belief for a long time, but I've never seen a proof.
⬐ pron> you're wrong to say that LC has no notion of complexityI didn't say that it has no notion of complexity; I said it "does not have a useful formulation of complexity", as reduction step count are not very useful in measuring algorithmic complexity, at least not the measures of complexity most algorithms are concerned with.
> It's foolish to think of this as equivalent to LC, though.
Oh, I don't think that at all, which is why I specifically said that some people make the mistake of confusing LC reductions with classical substitutions (equality). They may then think that computation can be equational (false), rather than say it may sometimes be useful to think of computation in equational terms, but that's an abstraction -- namely, a useful lie -- that has a cost, i.e. it is "leaky" (true).
⬐ telFair enough.None⬐ pron> A much more foundational difference of opinion about purity arises from whether or not you allow termination.Termination or non-termination? One of the (many) things that annoy me about PFP is the special treatment of non-termination, which is nothing more than unbounded complexity. In particular, I once read a paper by D.A. Turner about Total Functional Programming that neglected to mention that every program ever created in the universe could be turned into a total function by adding 2^64 (or a high enough counter) to every recursive loop without changing an iota of its semantics, therefore termination cannot offer a shred of added valuable information about program behavior. Defining non-termination as an effect -- as in F* or Koka (is that a Microsoft thing?) -- but an hour's-computation as pure is just baffling to me.
> I'd be interested to see a semantics where setting mutable stores is sufficiently ignored by the choice of equality as to be considered a non-effect. I'm not sure what it would look like, though.
I think both transactions and monotonic data (CRDTs), where mutations are idempotent, are a step in that direction.
⬐ telNon-termination, my bad!And of course that's true! Trivially so, though, in that we could do the same by picking the counter to be 10 instead of 2^1000, since we don't appear to care about changing the meaning of the program.
If we do, then we have to consider whether we want our equality to distinguish terminating and non-terminating programs. If it does distinguish, then non-terminating ones are impure.
Now, what I think you're really asking for is a blurry edge where we consider equality module "reasonable finite observation" in which something different might arise.
But in this case you need partial information so we're headed right at CRDTs, propagators, LVars, and all that jazz. I'm not for a single second going to state that there aren't interesting semanticses out there.
Although I will say that CRDTs have really nice value semantics with partial information. I think it's a lot nicer than the operational/combining model.
⬐ pron> If we do, then we have to consider whether we want our equality to distinguish terminating and non-terminating programs.But this is what bugs me. As someone working on algorithms (and does not care as much about semantics and abstractions), the algorithm's correctness is only slightly more important than its complexity. While there are (pragmatic) reasons to care about proving partial correctness more than total correctness (or prioritizing safety over liveness in algorithmists' terms), it seems funny to me to almost completely sweep complexity -- the mother of all effects, and the one at the very core of computation -- under the rug. Speaking about total functions does us no favors: there is zero difference between a program that never terminates, and one that terminates one nanosecond "after" the end of the physical universe. Semantic proof of termination, then, cannot give us any more useful information than no such proof. Just restricting our computational model from TM to total-FP doesn't restrict it in any useful way at all! Moreover, in practical terms, there is also almost no difference (for nearly all programs) between a program that never terminates and one that terminates after a year.
Again, I fully understand that there are pragmatic reasons to do that (concentrate on safety rather than liveness), but pretending that there is a theoretical justification to ignore complexity -- possibly the most important concept in computation -- in the name of "mathematics" (rather than pragmatism) just boggles my mind. The entire notion of purity is the leakiest of all abstractions (hyperbole; there are other abstractions just as leaky or possibly leakier). But we've swayed waaaay off course of this discussion (entirely my fault), and I'm just venting :)
⬐ telI don't think at all that "value semantics" without any mention of complexity is an end in and of itself. Any sensible programmer will either (a) intentionally decide that performance is minimally important at the moment (and hopefully later benchmark) or (b) concern themselves also with a semantic model which admits a cost model.Or, to unpack that last statement, simulate the machine instructions.
I'm never one to argue that a single semantic model should rule them all. Things are wonderful then multiple semantic models can be used in tandem.
But while I'd like to argue for the value of cost models, at this point I'd like to also fight for the value-based ones.
Totality is important not because it has a practical effect. I vehemently agree with how you are arguing here to that end.
It's instead important because in formal systems which ignore it you completely lose the notion of time. Inclusion of non-termination and handling for it admits that there is at least one way which we are absolutely unjustified in ignoring the passage of time: if we accidentally write something that literally will never finish.
It is absolutely a shallow way of viewing things. You're absolutely right to say that practical termination is more important that black-and-white non-termination.
But that's why it's brought up. It's a criticism of certain value-based models: you guys can't even talk about termination!
And then it's also brought up because the naive way of adding it to a theorem prover makes your logic degenerate.
⬐ pron> And then it's also brought up because the naive way of adding it to a theorem prover makes your logic degenerate.Well, I'd argue that disallowing non-termination in your logic doesn't help in the least[1], so you may as well allow it. :) But we already discussed in the past (I think) the equivalence classes of value-based models, and I think we're in general agreement (more or less).
[1]: There are still infinitely many different ways to satisfy the type a -> a (loop once and return x, loop twice, etc. all of them total functions), and allowing (and equating) all of them loses the notion of time just as completely as disallowing just one of them, their limit (I see no justification for assuming a "discontinuity" at the limit).
⬐ telIt's not the type (a -> a) which is troubling, it's the type (forall a . (a -> a) -> a) which requires infinite looping. It's troubling precisely because the first type isn't.⬐ pronOh, I see. It's an element in the empty set, which is indeed very troubling for constructive logic. Well, they're both troubling in different ways. Your example is troubling from a pure mathematical soundness perspective, and mine is from the "physical"[1] applicability of the model.[1]: The relationship between classical math and computation is in some ways like that of math and physics, except that physics requires empirical corroboration, while computation is a kind of a new "physical" math that incorporates time. In either case the result can be the same: the math could be sound but useless. In physics it may contradict observation; in computation it can allow unbounded (even if not infinite) complexity.
⬐ telIt causes trouble for non-constructive logics, too. Any logic with an identity principle will be made inconsistent with the inclusion of `fix : forall a . (a -> a) -> a`.By yours are you referring to `forall a . a -> a`? I don't see how that principle is troubling at all.
⬐ pronIt is troubling in the same way, but more subtly, and it has to do with the interpretation of the logic rather than the logic itself. The problem with (a -> a) -> a is that you can prove any a. Now, this is indeed a problem if you're trying to use types to prove mathematical theorems (one interpretation). But what if you're using types to prove program correctness (second interpretation, this one computational)? Why is it troubling? Well, it's troubling because you may believe you've constructed a program that produces some result of type x, but really you haven't, because somewhere along the way, you've used a (a->a)->a function (or forall a b. a->b). But the thing is that from one interpretation you really have succeeded. Your type is populated, but it is populated with a nonterminating function. Why is that a problem? It's a problem because it may cause me to believe that I have a program that does something, while in reality that program is useless.Now back to my issue. Suppose that somewhere along the way you rely not on a non-terminating function but on a high-complexity function (e.g. a function that factors integers). You may then believe you've constructed a program, but your program is not only just as useless as the non-terminating one, but useless in the same way. A program that takes 10000 years is much more equivalent to a non-terminating program than to one that completes in one second. Your types are still populated with "false" elements, and so your logic, while now useful for proving mathematical theorems, may still prove "false" programs, in the sense of useless programs.
HOWEVER, what I said has a practical flaw, which still keeps excluding non-termination but allowing high-complexity useful. And that is that it's much easier for human beings to accidentally create programs with infinite complexity, rather than accidentally create programs with a finite, but large complexity. I don't know if we have an answer as to why exactly that is so. It seems that there are many cases of "favored" complexity classes, and why that is so is an open problem. Scott Aaronson lists the following as an open question[1]:
The polynomial/exponential distinction is open to obvious objections: an algorithm that took 1.00000001^n steps would be much faster in practice than an algorithm that took n^10000 steps! But empirically, polynomial-time turned out to correspond to “efficient in practice,” and exponential-time to “inefficient in practice,” so often that complexity theorists became comfortable making the identification... How can we explain the empirical facts on which complexity theory relies: for example, that we rarely see n^10000 or 1.0000001^n algorithms, or that the computational problems humans care about tend to organize themselves into a relatively-small number of equivalence classes?
Nevertheless, it is important to notice that what makes non-termination-exclusion useful in practice is an empirical rather than a mathematical property (at least as far as we know). Which is my main (and constant) point that computation and software are not quite mathematical, but in many ways resemble physics, and so relying on empirical (even cognitive) evidence can be just as useful than relying on math. The two should work in tandem. It is impossible to reason about computation (more precisely, software), with math alone; there are just too many empirical phenomena in computation (and software in particular) for that to make sense. I feel (and that may be a very biased, wrong observation) that the software verification people do just that, while the PLT people (and by that I don't mean someone like Mattias Felleisen, but mostly PFP and type theory people) do not.
How can that look in practice? Well, observing (empirically) that the complexity spectrum is only sparsely populated with programs humans write (and that's true not only for instruction counts but also of IO operations, cache-misses etc.), perhaps we can create an inferrable type system that keeps track of complexity? I know that integer systems with addition only are inferrable, but I'm not sure about multiplication (I don't think so, and I know division certainly isn't). Perhaps we can have a "complexity arithmetics" that is inferrable, and allows "useful rough multiplication" even if not exact multiplication? A Google search came up with some work in that direction: http://cristal.inria.fr/~fpottier/slides/fpottier-2010-05-en... (I only skimmed it).
Most people consider garbage collection to be a net win in terms of simplicity. Have you thought about why? Not every feature interacts with other features in complicated and error prone ways.⬐ kevinr⬐ knucklesandwichI think the politest description I can provide of the experience of tracking down GC bugs is that they interacted with other features in complicated and error prone ways.⬐ i_s⬐ catnaroekBut was that code in the GC implementation, or your program? Because if its in the implementation, then that is a different matter. We have to distinguish between simplicity of implementation vs simplicity provided the user. I agree that if it is not implemented correctly, it can be a net loss in simplicity.⬐ kevinrIt was code in my program.You mean “ease of use”, not “simplicity”. Simplicity is the lack of (Kolmogorov) complexity.⬐ bjwbellThat's why I said large set. I haven't thought about garbage collection enough to have any insight on it.⬐ jcritesI believe that garbage collection is a net win because it allows software to be composed in simple ways when it would otherwise be difficult to compose.I can pass data from one part of the program to another without coordinating both parts to respect the same memory management convention, and without having to pass that information from one place to another. This makes it easier to compose software, and in particular to reuse software like libraries (that frequently end up as layers between one component and another). For a concrete example, in a Java program I can simply publish an event into a Guava EventBus [1] without worrying where it will end up at the time I write that code. There's no real risk that I'll end up with a memory leak. I can connect two things together that weren't designed to be used together, and I can do it while inserting intermediate layers that transform, copy, record, measure, that data.
Garbage collection significantly reduces the amount of coordination necessary between unrelated parts of the code base, thereby improving code reuse. This is what I would claim is less commonly recognized win, beyond the more commonly recognized wins from eliminating classes of obvious mistakes. EventBus is just one random example that involves plugging things together - the same effect is present all over Java libraries, from logging frameworks to collections to concurrent data structures.
Generics solve an occurrence of too much entanglement. That is, it solves entanglement of an abstract "shape" of computation with a specific set of type definitions. Generics actually allow you to not think about an additional dimension of your program (i.e. the exact types a computation or data type can be used with).Haskell programmers famously point this out with the observation that a generic fmap is safer than one that has knowledge of the concrete types it uses. The type signature of fmap is this:
fmap :: Functor f => (a -> b) -> f a -> f b
In practice, what this means is that you can be assured that your fmap implementation can only apply the passed function over the value(s) wrapped in the functor, because of the fact that it cannot have visibility into what types it will operate on.
In golang, because of a lack of generics, you can write a well-typed fmap function, but it will inherently be coupled with the type of the slice it maps over. It also means the author of such a function has knowledge of all the properties involved in the argument and return type of the function passed, which means the writer of an fmap can do all kinds of things with that data that you have no assurances over.
⬐ catnaroekExactly. Parametricity is the killer feature of statically typed functional languages. This why it saddens me when Haskell and OCaml add features that weaken parametricity, like GADTs and type families.⬐ js8Can you elaborate on your last sentence?⬐ catnaroek⬐ PeakerSorry, for some reason the “reply” link didn't appear below your post until after I had written my reply to Peaker. My reply to you is exactly the same:How do GADTs or type families weaken parametricity?⬐ catnaroekWithout either GADTs or type families, two types `Foo` and `Bar` with mappings `fw :: Foo -> Bar` and `bw :: Bar -> Foo` that compose in both directions to the identity, are “effectively indistinguishable” from one another in a precise sense. If you have a definition `qux :: T Foo`, for any type function `T` not containing abstract type constructors, you can construct `justAsQuxxy :: T Bar` by applying `fw` and `bw` in the right places.With either GADTs or type families, this nice property is lost.
⬐ PeakerThis nice property is not part of 'parametricity' as I know it, though.⬐ tomeAre you saying something like "All type constructors are functorial Hask^n x Hask^op^m -> Hask"?⬐ catnaroek⬐ lomnakkusIt's something weaker. Consider the groupoid of Haskell types and isomorphisms. Without GADTs and type families, all type constructors of kind `* -> *` are endofunctors on this groupoid.Note 1: And there are higher-kinded analogues, but I hope you get the idea from this.
Note 2: There are also exceptions, like `IORef` and friends.
However, GADTs and TFs are completely opt-in, so it seems a bit of a stretch to construe this as a generally bad thing. IME it's not as if library authors are arbitrarily (i.e. for no good reason) using GADTs or TFs instead of plain old type parameters in their APIs.⬐ catnaroekReflection, downcasts and assigning `null` to pointers are completely opt-in in Java too.With respect to type families, I'm probably being a little bit unfair. Personally, I don't have much against associated type families. (Although I think Rust handles them much more gracefully than GHC.) But very important libraries in the GHC ecosystem like vector and lens make extensive use of free-floating type families, which I find... ugh... I don't want to get angry.
⬐ lomnakkus> Reflection, downcasts and assigning `null` to pointers are completely opt-in in Java too.No, they're not -- not in the same sense, at least. A GADT/TypeFamily is going to be visible in the API. None of the things you mentioned are visible in the API.
There's a HUGE difference.
⬐ catnaroek> A GADT/TypeFamily is going to be visible in the API.Only works if you're never going to make abstract types. Which I guess is technically true in Haskell - the most you can do is hide the constructors of a concrete type. But the ability to make abstract types is very useful.
Don't get me wrong, I love Haskell. It's precisely because I love Haskell that I hate it when they add features that make it as hard to reason about as C++. (Yes, there I said it - type families are morally C++ template specialization.)
⬐ lomnakkusIf a type is abstract then the rest is up to the implementation of functions that operate on the data type -- and that could be hiding all kinds of nastiness like unsafePerformIO and the like. Yet, we usually don't care about that because it's an implementation detail.Am I missing some way to "abuse" GADTs/TFs to violate the abstraction boundary or something like that? (I seriously can't see what you think the problem is here. I mean, you can equally well abuse unsafeCoerce/unsafePerformIO to do all kinds of weird things to violate parametricity, so I don't see why GADTs/TFs should be singled out.)
Isn't that exactly what Rob Pike is saying with the vector space analogy?⬐ knucklesandwich⬐ catnaroekI think that's what he's appealing to, but I have a hard time reconciling that sentiment with many design characteristics of Go. Go's type system for instance... I don't think he fully grasps "what he's trying to solve" by having a static type system in golang, when the language has things like unsafe casting, null pointers, a lack of parametric polymorphism, etc. As a programmer tool, its hugely weakened by these design decisions... there are large classes of properties about code that are simply impossible (or are much more complicated) to encode using types in golang. And yet in their literature on some of these subjects, they make an appeal to simplicity [1]. I think there's a disconnect here between theory and practice.> Complexity is not about additivity, it's about entanglement.This. And nothing reflects entanglement better than a formal semantics. English (or any other natural language) always lets you sweep it under the rug. The only objective measure of simplicity is the size of a formal semantics.
I expand on this here: https://www.reddit.com/r/programming/comments/3sstis/for_bet...
⬐ NoneNone⬐ pron> The only objective measure of simplicity is the size of a formal semantics.If we accept that, then simplicity alone is not a desirable goal. Something may well be formally simple but at the same time incompatible with human cognition. Indeed, that may not be objective, but since when do we value things only by objective measures? That the only objective measure of simplicity may be the size of formal semantics does not mean that it is the most useful measure of simplicity (if we wish to view simplicity as possessing a positive value that implies ease of understanding).
⬐ fauigerzigerk⬐ tel>If we accept that, then simplicity alone is not a desirable goalOr maybe simplicity in terms of the formal semantics is a desirable goal, but not the simplicity of the language alone.
At the end of the day, what determines mental load is the complexity of solving a particular problem using a particular language.
I don't think this simplicity follows from the simplicity of the language itself. There may not even be the slightest correlation.
⬐ AnimalMuppet⬐ ZenoArrowIn general, the simpler the language, the more complex the code to implement the solution in that language, and so the harder it is to understand the code. But the more complex the language, the simpler (and easier to understand) the code, but the language itself is harder to understand. It's almost like you want the language to have the square root of the complexity of the problem.(This is in general. The big way around this is to pick a language that is well-suited for your particular problem.)
If you want an alternative explanation for simplicity, I'd say simplicity implies flexibility.Designing a simple implementation of something means that it is as close to the essence of what you've designed it for, and by doing so you've made it more universal, and therefore more flexible/adaptable.
⬐ catnaroek⬐ catnaroekThis would work if compilers were written in simple languages, and if target languages themselves were simple. In other words, in a parallel universe.> If we accept that, then simplicity alone is not a desirable goal.Agreed. Otherwise, Forth and Scheme would've taken over the world.
> Something may well be formally simple but at the same time incompatible with human cognition.
Do you have a concrete example?
> (if we wish to view simplicity as possessing a positive value that implies ease of understanding).
I don't particularly fetishize simplicity. What I want is the least effort path to writing correct programs. The following features help:
0. Simplicity - smaller formal systems have less room for nasty surprises.
1. Using the right tool for resource management - sometimes it's a garbage collector, sometimes it's substructural types.
2. Typeful programming - it's an invaluable tool for navigating the logical structure of the problem domain.
⬐ pron> Do you have a concrete example?Off the top of my head, and since we're talking about computation, I'd say SK combinator calculus. Or Church numerals.
> Typeful programming
It is, but it can also be a hindrance. Finding the sweet spot is a matter for empirical study.
⬐ catnaroek⬐ AnimalMuppet> I'd say SK combinator calculus. Or Church numerals.They're a PITA to use, but not because they're hard to understand.
⬐ AnimalMuppetBut for writing actual programs, the complexity of using matters as much as the complexity of understanding.(I recognize that this doesn't invalidate the point you are trying to make in the parent post. They aren't incompatible with human understanding. They're incompatible with writing programs in a reasonable amount of time, though.)
> > Something may well be formally simple but at the same time incompatible with human cognition.> Do you have a concrete example?
Brainfuck?
So I sort of agree with you here, but only as a partial converse:> If all the formal semantic models for a language are unwieldy then you've probably got a non-simple language.
Now, "simplicity" is a mental construct, a language UX construct. To handle this, I think of "unwieldy" as a bit of a technical term. What does it mean to be unwieldy? It means that there is significant non-ignorable complexity.
Significant here must be defined almost probabilistically, too. If there is significant complexity which is ignorable across 99/100 real-world uses of a language then it really should win some significant points.
Ignorable complexity is also an important concept. It asks you to take empirical complexity measures (you mention Kolmogorov complexity; sure why not?) and temper them against the risk of using a significantly simpler "stand-in" semantic model. I accept that the stand-in model will fail to capture what we care about sometimes, but if it does so with an acceptable risk profile then I, pretty much definitionally, don't care.
Now that I've weakened your idea so much, it's clear how to slip in justifications for really terrible languages. Imagine one with a heinous semantics but a "tolerable" companion model which works "most of the time".
From this the obvious counterpoint is that "most of the time" isn't good enough for (a) large projects (b) tricky problems and (c) long support timelines. Small probabilities grow intolerable with increased exposure.
---
But after all this, we're at an interesting place because we can now talk about real languages as being things with potentially many formally or informally compatible formal or informal semantic models. We can talk about how complexity arises when too few of these models are sufficiently simple. We can also talk about whether or not any of these models are human-inelligible and measure their complexity against that metric instead of something more alien like raw Kolgomorov complexity.
So here's what I'd like to say:
> Languages which hide intolerable complexity in their semantics behind surface simplicity are probably bad long-term investments.
and
> Languages which have many "workably compatible" semantic models, each of which being human-intelligible, are vastly easier to use since you can pick and choose your mode of analysis with confidence.
and
> Value-centric semantic models (those ones with that nasty idea of "purity" or whatever) are really great for reasoning and scale very well.
In particular, I'm personally quite happy to reject the assertion made elsewhere that value-centric semantics are not very human intelligible. On the other hand
> Simple operational semantic models are also pretty easy to understand
I just fear that they scale less well.
⬐ catnaroek⬐ EdiX> Now, "simplicity" is a mental construct, a language UX construct.My take on “simplicity” is very computational. To me, a programming language is a system of rules of inference, whose judgments are of the form “program is well-formed” (which covers syntax and type checking) and “program does this at runtime” (a reduction relation, a predicate transformer semantics, or whatever fits your language's dynamics best). Then, simplicity is just some measure of the language's size as a collection of rules of inference. Also:
0. Undecidable rules of inference (e.g., type reconstruction for a Curry-style System F-omega) are considered cheating. Undefined behavior (e.g., C and C++) is also considered cheating. Cheating is penalized by considering the entire language infinitely complex.
1. Languages (e.g., ML's module system) are allowed to be defined by elaboration into other languages (e.g., System F-omega). Elaboration into a language that cheats is considered cheating, though.
> To handle this, I think of "unwieldy" as a bit of a technical term. What does it mean to be unwieldy? It means that there is significant non-ignorable complexity.
I don't see any complexity as ignorable at all. I just see some complexity as worth the price - but you, the programmer, need to be aware that you're paying a price. For instance, the ease with which one can reason about Haskell programs (without the totally crazy GHC extensions) justifies the increased complexity w.r.t., say, Scheme.
> Significant here must be defined almost probabilistically, too. If there is significant complexity which is ignorable across 99/100 real-world uses of a language then it really should win some significant points.
This is ease of use, which is subject to statistical analysis; not simplicity, which is not.
⬐ telI don't want to deny that those "quantitative" measures exist. I want to cast doubt that they're the dominant mechanism for modeling how real people think when they're accomplishing a task in a formal system.> nothing reflects entanglement better than a formal semanticsA formal semantics is just a way to translate from one formalism to another.
It's rather obvious that choosing the target formalism determines how simple the language will appear, when you talk about "formal semantics" you should specify "which one": operational? denotational? axiomatic?
Stricly speaking a compiler or an interpreter represents a formal semantics for a language: operational semanthics rules are often very very similar to the code of an AST interpreter, for example.
One could interpreter your statement to mean that the smaller the compiler the simpler the language, which means that assembly language was the simplest language all along!
For example, in your reddit post you claim that := is problematic, and indeed its semantics is tricky and often trips beginners (and even experienced!) programmers. However := semantics is not actually that complicated "define every variable that isn't defined inside the current scope, otherwise assign them" and the errors stem from the fact that people assume that the scope lookup for := is recursive, which would arguably result in a more complicated formal semantics.
⬐ catnaroek> A formal semantics is just a way to translate from one formalism to another.Of course, we need to reach a gentleman's agreement regarding which formalism is a good “foundation” for defining everything else. My personal preference would be to define all other formal systems in terms of rules of inference.
> It's rather obvious that choosing the target formalism determines how simple the language will appear, when you talk about "formal semantics" you should specify "which one": operational? denotational? axiomatic?
I am fine with any, as long as the same choice is made for all languages being compared. What ultimately interests me is proving a type safety theorem, that is, a precise sense in which “well typed programs don't go wrong”, so perhaps this makes a structural operational semantics more appropriate than the other choices.
> Stricly speaking a compiler or an interpreter represents a formal semantics for a language: operational semanthics rules are often very very similar to the code of an AST interpreter, for example.
> One could interpreter your statement to mean that the smaller the compiler the simpler the language, which means that assembly language was the simplest language all along!
Sure, but the target languages used by most compilers are often themselves very complex. Which means a realistic compiler or interpreter most likely won't be a good benchmark for semantic simplicity.
⬐ EdiX⬐ pcwalton>Of course, we need to reach a gentleman's agreement regarding which formalism is a good “foundation” for defining everything else. My personal preference would be to define all other formal systems in terms of rules of inference.If you are interested in defining "low cognitive load" that's a poor choice, in my opinion.
>I am fine with any, as long as the same choice is made for all languages being compared. What ultimately interests me is proving a type safety theorem, that is, a precise sense in which “well typed programs don't go wrong”, so perhaps this makes a structural operational semantics more appropriate than the other choices.
I'm not aware of any such thing, the kinds of formal semantics that academics prefer deal very poorly with the realities of finite execution speed and memory, the kinds that pratictioners use (which usually isn't referred to as "formal semantics" but rather "what does this compile to") deal very poorly output correctness.
However this has little to do with cognitive load, even if such formal semantics existed it doesn't necessarily mean it would be easy for a human mind.
> Sure, but the target languages used by most compilers are often themselves very complex. Which means a realistic compiler or interpreter most likely won't be a good benchmark for semantic simplicity.
If you agree that formal semantics is just a translation from one formalism to another, you can't claim that a formalism A is semantically more complex than formalism B without picking a formalism C as a reference point.
⬐ catnaroek> If you are interested in defining "low cognitive load" that's a poor choice, in my opinion.I'm interested in “low cognitive load without sacrificing technical precision.” It's a much harder goal to achieve than “low cognitive load if we hand-wave the tricky details.”
> However this has little to do with cognitive load, even if such formal semantics existed it doesn't necessarily mean it would be easy for a human mind.
Which is exactly my point. I only consider a language simple if its formal description is simple.
> If you agree that formal semantics is just a translation from one formalism to another, you can't claim that a formalism A is semantically more complex than formalism B without picking a formalism C as a reference point.
No disagreement here. I even stated my personal choice of C.
⬐ EdiX> I'm interested in “low cognitive load without sacrificing technical precision.”You don't seem to be interested in low cognitive load at all, otherwise:
> No disagreement here. I even stated my personal choice of C.
you would have attempted to motivated your choice of reference point in terms of cognitive load. Even if induction mathematics was the way the human mind worked (which it isn't) it's very different from CPUs and there is a cognitive load (and semantical distance) in going from mathematics to CPUs.
⬐ catnaroek> Even if induction mathematics was the way the human mind worked (which it isn't)Even if it isn't how the human mind works, it's how computing itself works. Would you take seriously a physicist who denies gravity? I wouldn't take seriously a computer scientist who denies structural induction.
⬐ EdiX> it's how computing itself worksbut it's not the whole story when it comes to computers.
> For example, in your reddit post you claim that := is problematic, and indeed its semantics is tricky and often trips beginners (and even experienced!) programmers. However := semantics is not actually that complicated "define every variable that isn't defined inside the current scope, otherwise assign them" and the errors stem from the fact that people assume that the scope lookup for := is recursive, which would arguably result in a more complicated formal semantics.Clearer examples of unnecessary complexity in Go would be the function-scoped nature of "defer" (implicit mutable state is much more complicated than block scoping) and the inconsistent behavior of "nil" with the built-in collections (reading from a nil map returns zero values, but reading from a nil slice panics).
> Programming without pointer indirection seems like cycling without legsA study of functional programming will demonstrate this untrue. The paragraph you quoted from the paper elaborates to specifically why references are complicated and low level: "introducing the concept of reference ... immediately gives rise in a high level language to one of the most notorious confusions of machine code, namely that between an address and its contents ... They cannot be input as data, and they cannot be output as results. If either data or references to data have to be stored on files or backing stores, the problems are immense". Perhaps one reason why people love working in JSON so much is because it only encodes values.
> indeed high level languages often move the other way, abandoning value types altogether
FP languages strongly emphasize programming with values. Rich Hickey, creator of Clojure programming language, gave an amazing talk "Simple made Easy" which is probably the best place to start to dive into this: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ VeedracFP languages are almost exclusively pointer heavy; without it they could not do structure sharing which it what allows persistent data structures with efficient operations.FP languages also rely heavily on partial pattern matching, type classes with vtable-style indirection and even GC for cycle collection. Closures in FP languages are boxed, too, almost without exception.
In Haskell, even integers are boxed by default. You don't observe many of the problems of references due to their immutability, but this isn't to say they're not there. The "value-heavy" language closest to FP I know of is Rust, and many functional idioms are plain irritating to use because of it.
Maybe Clojure is different, but I'd be surprised. Perhaps you were in disagreement about the use of the word "value" in "value type", which I meant in the D or Rust sense of a stack-allocated, indirection-free type.
⬐ NoneNone⬐ ratboy666"even integers are boxed by default"Um... why? For example, 2 is.. 2. 2 is not 3. If I "box" 2, can I then make it 3?
Some very old FORTRAN implementations actually allowed this:
subroutine x(j)
write(,)j
j = 3
return
do 1 i = 1,2
1 x(4)
4
3
(sorry... it's been years). Note that the reference is immutable (j refers to a single location) -- but the value is boxed (4 is put into a memory location). And this is why this can even work.
FredW
⬐ Veedrac⬐ gary_bernhardtYour code is quite hard to read, especially as I don't know Fortran. Can I have it with indentation (indent each line 2+ spaces to make a code block)?---
Integers are boxed because Haskell's semantics almost exclusively deal with boxed types (eg. you can't pass unboxed types to most functions). The optimizer might specialize some functions for boxed types, but this is a transparent optimization and does not affect semantics.
You're talking about implementation now. The text you quoted said "references' introduction into high level languages", not "references' use in the implementation of high level languages". The quote was about languages' conceptual models, not their underlying implementation forced by a particular type of CPU that code written in the language happens to be running on. A language can present value semantics while doing structural sharing using references underneath, as Clojure's persistent data types do.
In Rich Hickey terminology, it seems people reject that it is simple (non-interwoven) because it does not strike them as easy (familiar / close to hand)."map of int to string" map [int] string "map of state to map of int to state" map [state] map [int] state( ...Any excuse to link to this excellent presentation: http://www.infoq.com/presentations/Simple-Made-Easy )
I think you mix the meanings of simple and easy here. Simplicity is an absolute metric and describes the number of dependencies a thing has, while ease is a relative metric describing your understanding of said thing.For example, a singleton is easy to learn and easy to use, but since every function using it adds a hidden dependency it quickly grows in complexity to the point its impossible to reason about it without forgetting something.
On the other hand, a Promise is simple as it depends on nothing but a producer and a consumer, no matter how much you compose them. Yet I've seen many experienced developers struggle to learn how to use them as they're not easy to understand at first.
This is somewhat related to meta ignorance. From my own experience I've seen a tendency in novice programmers to stick with things which are both easy to learn and use. Their projects go well initially but they grow less and less productive over time as complexity creeps in from the composition of all these easy to use things.
I've always said experience in our industry is knowing what not to use in order to stay productive in the long run.
Here's a link to Rich Hickey explaining it in depth: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ vezzy-fnordSpeaking of meta, I absolutely loathe how the basic distinction between simplicity and ease of use has since become a meme so persistently associated with Rich Hickey. There is nothing I can really do about it, but it nonetheless annoys me to no end.⬐ jeremiepI myself learned it from Rich in the very talk I linked to a few years ago and I'm the first to admit I didn't make that distinction beforehand. I've met more developers unaware of the distinction than otherwise, which is why I'm curious as to why you think it has become a meme?Also note that english isn't my first language (I'm french Canadian) and even here in french the distinction is seldom made.
⬐ NoneNone⬐ vezzy-fnordIn colloquial English, no.The distinction between two main types of simplicity, those of parsimony and elegance, has been a long-standing philosophical topic [1].
In engineering, the so-called KISS principle (first coined as such in the early 20th century) has always had the implication of minimalism and implementation simplicity, in contrast to mere ease of use.
Fred Brooks wrote a famous paper in 1986 [2] perfectly describing the differences between accidental and essential complexity, and of the semantics of complexity management in software projects.
Hickey has said absolutely nothing spectacular, but his name comes up every time from the typing fingers of the historically illiterate whenever simplicity and ease of use are brought up.
[1] http://plato.stanford.edu/entries/simplicity/
[2] http://www.cs.nott.ac.uk/~cah/G51ISS/Documents/NoSilverBulle...
⬐ stdbrouwI dunno, people use the same kind of argument to say that nobody's really done anything new in philosophy since Kant or even Aristotle. The KISS principle is not the same as a distinction between simplicity and ease. Accidental vs. essential complexity is orthogonal to simplicity vs. ease. And parsimony and elegance are both about simplicity rather than ease. Some people can be a little bit too historically literate for their own good.⬐ jeremiepThanks for the precision, definitely puts it all into perspective!I knew about KISS, but almost every time I hear someone mention it they think about ease not simplicity. I will also definitely check out Brooks' paper.
While I understand your position, I believe a lot of this has been lost to the new generations of engineers and what Rich did is remind them of it.
⬐ dasil003"historically illiterate" are pretty strong words. Actually everyone is historically illiterate by these standards because the ideas that any one person is familiar with is a vanishingly small percentage of all the ideas the human race has ever had. Furthermore, the origins of ideas are impossible to trace with any great precision. Is the most famous person the person with the best ideas? Was the person with access to the printing press the person with the best ideas? Frankly it strikes me as a form of intellectual hipsterism to be bothered so much by this.Rich Hickey gained fame for this because he stated an idea very clearly and compellingly, this is non-trivial and should not be so flippantly dismissed as just recyling old ideas—all your ideas are recycled too.
⬐ kinleyd"Rich Hickey gained fame for this because he stated an idea very clearly and compellingly, this is non-trivial and should not be so flippantly dismissed as just recyling old ideas."+100 for this.
⬐ jdcAlan Kay has similarly criticized the computer software industry and its "pop culture."
> The common theme was seeing complexity and, especially, abstraction as a universal good rather than something with real costsRich Hickey did a great service outlining some common problems when thinking about the word complexity itself: http://www.infoq.com/presentations/Simple-Made-Easy
I don't think it's about the engineers wanting to see complexity, so much as the problems you mention stemming from design-by-committee.
I have a client that is exploring Datomic, so I wonder if some of you can chime in on why this is popular at the moment and what your experiences are with it?I'm a big Rich Hickey fan. If you don't know who he is, he's the guy behind Clojure and Datomic. I don't use those tools, but his views on simplicity are wonderful.
Here's a great quote of his on the subject:
"Simplicity is hard work. But, there's a huge payoff. The person who has a genuinely simpler system - a system made out of genuinely simple parts, is going to be able to affect the greatest change with the least work. He's going to kick your ass. He's gonna spend more time simplifying things up front and in the long haul he's gonna wipe the plate with you because he'll have that ability to change things when you're struggling to push elephants around."
Here's his classic talk on simplicity if you haven't seen it yet: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ dasmothDatomic doesn't seem to have had a huge amount of marketing: it's been spreading largely by word of mouth, so a slow build-up makes sense.It does bring an exceptionally elegant design (well worth reading Nikita Prokopov's "Unofficial guide" if you're curious). Also, the time and transaction-annotation features are unmatched AFAICT -- if you're working with complex data where provenance matters, Datomic can save a HUGE amount of work building tracking systems.
⬐ blintzingI was very interested, but pretty disappointed that Datomic is completely closed source. Maybe this is a little mean, but what could be more "simple" than being able to read, understand, and modify the database you rely on?Neo4j, though marketed differently, is a similar approach (but the Community version is GPLv3 and Enterprise is AGPLv3). The Cypher query language is declarative in a similar way to Datomic - the biggest missing feature is transactions.
⬐ brianwawok⬐ jtmarmonFor sure, I would have played around with it, if it was open source and free to some small number of clients. But with so many FOSS databases, why use Datomic?⬐ joshdickRich Hickey has been criticized for that repeatedly. When asked, he's been transparent that Datomic is closed source so that he can put his kids through college. He also points out that he already gave us the whole Clojure language open source.It's hard for me not to sympathize with him on this.
We're using datomic in production. It's had its ups and downs. For one, having raw data available at in-memory speeds really changes the level of expressiveness you have in your code; you no longer are constrained to packing every question about your data into a giant query and sending it off - you can instead pull data naturally and as needed. Many of our queries make multiple queries and are high performance.The licensing is a huge pain in the ass. If I accidentally launch an extra peer over our license limit, our production environment will stop working until the extra peer comes down. This is really butting heads with the growing popularity of abstracting physical servers as clusters so I think the strategy is kind of a mistake on cognitect's behalf.
⬐ cliftonk⬐ ljosaPart of me wonders why they don't open source datomic and crank up the marketing effort on the consultancy and datomic/clojure/etc support portion of the business. It seems like a much more effective model for DB companies. For direct revenue streams, they can always have tuned/monitored clusters packaged as appliances.Datomic is probably getting more attention on HN in the wake of David Nolen's EuroClojure talk about Om Next (https://news.ycombinator.com/item?id=9848602).⬐ tallesI just can't get enough Hickey talks. The guy put on clear words things I always feel.⬐ taericI can't help but feel the quote ultimately embodies a false belief. Simplicity doesn't build you a rocket that can get to the outer solar system. Understanding and experimentation does.Sure, this was probably built up using simple experiments and designs. But consider the Mar's landing[1]. Simplicity would be to have a single mechanism for landing the Curiosity. Not 3. With one of them being a crane drop from a hovering rocket!?
I do feel there is an argument to up front simplicity. However, as systems grow, expect that the simplicity will be harder and harder to maintain and keep such requirements as performance met. To the point that it becomes a genuine tradeoff that has your standard cost/benefit analysis.
In the end, this falls to the trap of examples. If you are allowed to remove all assumptions from real use down to only a simple problem, you can get a simple solution. Add back in the realities of the problem, and the solution can get complex again. It is a shame that, in studies, so few real programs are actually looked at.
⬐ Skinney⬐ arohner> Simplicity would be to have a single mechanism for landing the Curiosity. Not 3. With one of them being a crane drop from a hovering rocket!?Why? Simple, in the way Rich Hickey advocates, means the opposite of complex, which means that things are woven together. You can have many landing strategies without them being tightly coupled together. A huge system isn't necessarily complex.
⬐ taeric⬐ jacobolusThat is the catch, all three landing strategies were coupled together. You couldn't do one without the one before it. More, previous steps had to take into account the baggage (literal) that was necessary to perform later steps.⬐ SkinneyI thought you were speaking about different strategies, but in this case you're describing three different stages of an overall landing strategy. That doesn't sound complex.⬐ sooheonIf that's the best they could do and what got the job done, good. It's as simple as was possible and necessary. What exactly does this prove against simplicity, again?⬐ taericThe difference between "simple" and "as simple as possible" is the crux.Mainly, the problem is that these speeches all talk about keeping things simple. In many problems, this can't be done. Understanding the simple helps. But the actual solution will not be simple. So any newspeak to get around that is just annoying.
⬐ SkinneyWhy not?⬐ taericSee my above post. As simple as possible is a far cry from simple. That is all I am saying.I extend that into saying that people that can understand complicated things, as well, will have an advantage.
⬐ SkinneyA simple system can solve complicated things. When Rich Hickey talks about simple, he is referring to tight coupling, "death by specificity" and hard to understand concurrency. Having a system that does multiple things, isn't necessarily a complicated system. A Mars landing, which in itself is a difficult (though not necessarily complex) problem, can be solved by a simple system. An example of this is Unix. A simple system that does complicated things.You should watch the talk(s), as your analysis here is entirely missing the context. What you’re talking about is what Rich Hickey and Stu Halloway call “complicated”, which is different from what they call “complex”.⬐ taericI've seen them. They are nice and very alluring. So are a lot of false things. :) And I should note that I am mainly asserting this as false so that I can further explore the idea.The idea to generate a new word that is hard to blur from existing ones and depends entirely on context is amusing in this context.
That is, what separates complicated from complex is one of context. Yet... contexts change. And often the first thing you do when building a solution to a problem is to reduce the problem to something easier to solve.
In this angle, I fully agree. Simplify your problem as much as you can. But do not be misled into thinking you can keep it simplified. As you add in more and more of the realities of the problem, they will reflect in the solution. And, often, the worst thing you can do is to try and cling to the "simple" solution that solved a different problem.
That is, understand the simple things well. See how they map onto the complicated things. Don't cling to the idea that they can be merely composed into the complicated solution. Often, several simple solutions can be subsumed by a more complicated one. Much in the same way that higher math can subsume lower maths.
I love datomic. It's a relational, ACID, transactional, non-SQL database.The upsides:
SQL is a horrible language, yet all other noSQL DB also throw away the relational, transactional and ACID features that are great in postgres. Postgres with datalog syntax would basically be a win by itself. Datomic queries are data, not strings. Queries can be composed without string munging, and with clear understanding of what that will do to the query planner.
The schema has built-in support for has-one, has-many relationships, so there's no need for join tables.
I've never met a SQL query planner that didn't get in the way at some point. If needed, you can bypass the query planner, and get raw access to the data, and write your own query.
You can run an instance of it in-memory, which is fantastic for unit tests, so you don't have Postgres in production, but SQLite when testing.
The downsides:
It's closed source.
Operationally, it's unique. Because it uses immutable data everywhere, its indexing strategy is different. I don't have the experience of what it will do under high load.
The schema is 'weaker' than say, postgres. While you can specify "this column is type Int", you don't have the full power of Postgres constraints, so you can't declare 'column foo is required on all entities of this type', or "if foo is present, bar must not be present", etc. It should be possible to add that using a transactor library, but I don't think anyone has done serious work in that direction yet.
Compound indexing support isn't in the main DB yet. I had to write my own library: https://github.com/arohner/datomic-compound-index
⬐ sgroveDefinitely agree re: datalog/pull syntax for SQL backends. Quite surprised it hasn't happened yet.
If you are using python code for serving static files, probably you are not seeing lots of traffic yet, I guess you should reconsider your decision and watch "Simple made Easy"[1] talk by Rich Hickey
⬐ danneuLooks like Whitenoise can gzip your assets, add a hash to the filename, serve them with far-future headers, and then selectively serve the gzipped version based on Accept-Encoding headers.Put that behind Cloudflare and your origin server is only hit when an edge location is warming its cache.
Sounds Hickey-tier simple to me, especially compared to your advice of "just use and configure Nginx".
I completely agree it takes discipline and experience to write clean code in any language.What I'm saying is that it takes more discipline to cleanly use Java or C++ than it does to use Haskell or Clojure. For the simple reason that most of the abstractions provided by the former languages add to the program's complexity rather than remove it.
There's an excellent explanation by Rich Hickey in Simple Made Easy: http://www.infoq.com/presentations/Simple-Made-Easy
If you haven’t seen them, I recommend the Clojure guys’ talks about the subject of simplicity. They reached into the etymological history of the word “simple” to pull out its early definition, which is quite precise and IMO tremendously useful in this context, unlike the confused muddle of modern definitions.Rich Hickey, “Simple Made Easy”: http://www.infoq.com/presentations/Simple-Made-Easy
Stu Halloway, “Simplicity Ain’t Easy”: https://www.youtube.com/watch?v=cidchWg74Y4
⬐ bjeanesI too would encourage people seeing the parent comment to definitely watch those videos. The Rich Hickey talk especially has shaped a lot of my thinking in the last few years.
Both watch Rich Hickey's excellent presentation on the matter and establish whether you agree on the definitions.
A question I'm asking myself more often as I get older: What is the value of changing somebody's mind?To that end, rather than prove someone else's code is complex, we can emphasize the virtues of simplicity with what we do. Refactoring someone else's code in smaller increments would be the passive aggressive middle ground.
There are more opportunities with code that hasn't been written yet. Maybe suggest watching this lecture as a group and then just discussing it without any additional agenda: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ spacemanmattHaving worked a couple decades in the trade, occasionally with some very unstable people, I have seen one suicide. I doubt it had anything to do directly with work but it's been a reminder to be nice to people, even when they are wrong.
> I'd caution against referring to all such explorations as complexity. Complexity is a highly overloaded term in our field.The difference between complex & hard, easy & simple has been put very elegantly by Rich Hickey in Simple Made Easy [1]. That doesn't mean everyone agrees with his definitions, which is why he revives the word "complected" to mean objective interleaving of concepts, and pulls out "hard" from the way people use complex to mean something one is unfamiliar with. I like his definitions, so I use them. :)
> Sometimes it refers to the number of steps a given algorithm takes to compute
This can still create ambiguity since it could be either time or memory complexity, but still easy to infer, especially if there's a big O.
> depth and breadth of a program's syntax tree
Lisp overloads the parens for difference concepts, which is complex. This could also be hard if one's not familiar with the syntax.
> tendency to branch out and create cycles
Sounds like time complexity!
> Sometimes it's mistakenly used to refer to concepts which are in reality simple but merely unfamiliar or non-intuitive.
This is the ambiguity, is he saying Haskell complex because it has a lot of interleaving with it's concepts, that other languages do not? Or is it just unfamiliar? I would think it's simpler because it forces one to think about how time interleaves the program, which could make things harder! I'm guessing this is what the grand parent means, since ML is impure. Though, either case is empty without examples.
⬐ chongliYeah, I've seen that presentation. Rich's ideas were what I had in mind when I wrote my reply.In general, use of highly overloaded words is ambiguous in these discussions.
There are some things about software that are objective, such as simplicity. Rich Hickey talks a lot about this.
⬐ raverbashingSimplicity is never simpleAnd is most often ruined by the real world and its exceptions
Exactly. This is why I like Rich Hickey's Simple Made Easy [1] so much. Basically with easy constructs it becomes harder to build simple systems, even though the simple constructs are harder to learn.
⬐ mreilandyep, I love that talk and I find myself pointing people towards it all the time :)⬐ malkiaI love this talk, and Rich Hickey's talks in general, but I think this goes beyond that.At one point you want full control of the HW, much like you did with game consoles..
On the other you want security: This model must work in a sandboxed (os, process, vm, threads, sharing etc.) environment, along with security checks (oldest one that I remember was making sure vertex index buffers given to the driver/api must not reference invalid memory, something you would make sure is not the case for a console game through tests, but something that the driver/os/etc. must enforce and stop in a non-console game world - PC/OSX/Linux/etc.)
From little I've read on this API, it seems like security is in the hands of the developer, and there doesn't seem to be much OS protection, so most likely I'm missing something... but whatever protection is to be added, definitely would've not been needed in the console world.
Just a rant, I'm not a graphics programmer so it's easy to rant on topics you just scratched the surface...
----
(Not sure why I can't reply to jeremiep below), but thanks for the insight. I was only familiar with one I posted above (and that was back in 1999, back then if my memory serves me well, drawing primitives on Windows NT was slower than 95, because NT had to check all index buffers whether they were not referencing out-of-bounds, while nothing like this was on 98).
⬐ monocasaGPUs these days have MMUs and have address spaces allocated per context. It's implemented internally to the driver though so you don't see it. And it's normally mapped differently, but the point of AMD's HSA stuff is to make the CPU's and GPU's MMU match up.⬐ jeremiep(To anwser the lack of a reply button:)This is just hn adding a delay until the reply link appears related to how deeply nested the comment is. The deeper the longer the delay. It's a simple but effective way to prevent flame wars and the likes.
⬐ jeremiepSecurity is actually much easier to implement on the GPU than on the CPU. For the simple reason that GPU code has to be pure in order to get this degree of parallelism. A shader is nothing more than a transform applied to inputs (attributes, uniforms and varyings) in order to give outputs (colors, depth, stencil).Invalid data would simply cause a GPU task to fail while the other tasks happily continue to be executed. Since they are pure and don't interact with one another there is no need for process isolation or virtualization.
Basically, its easy to sandbox a GPU when the only data it contains are values (no pointers) and pure functions (no shared memory). Even with the simplified model the driver still everything it needs to enforce security.
⬐ pandamanYou are describing GPU from 1990s. Modern GPU is essentially a general purpose computer sitting on the PCIe bus and able to do anything the CPU can. It does not have to run pure functions (e.g. see how it can be used for normal graphics tasks in [1]) and can write any location in the memory it can see. Securing it is as easy/hard as securing a CPU: if you screw up and expose some memory to the GPU it can be owned just like the memory exposed to a CPU task[2].1. https://software.intel.com/en-us/blogs/2013/07/18/order-inde...
2. http://beta.ivc.no/wiki/index.php/Xbox_360_King_Kong_Shader_...
> I don't think anyone would say that .... Clojure is simple language, or that simplicity is a core goal for it.Good god you are so wrong.
Watch yourself some of Rich Hickey's trove of excellent presentations, including the one where he breaks down the detailed etymology of the word "simple" and how much he strives for that.
Seems like a good context to recommend the wonderful 'Simple Made Easy' talk by Rich Hickey, the creator of Clojure.
I cannot help but think that the overwhelming desire to support immutability and functional constructs here, as well as in nearly all other modern languages, gives significant evidence that functional programming is finally winning out over OOP.In the future, I hope that FP will be the default design choice, with objects being used where needed such as for components, plug-ins, and ad-hoc dictionary-passing-style tools.
After all, simplicity is the most important property of any software system - http://www.infoq.com/presentations/Simple-Made-Easy
⬐ munificent> I cannot help but think that the overwhelming desire to support immutability and functional constructs here, as well as in nearly all other modern languages, gives significant evidence that functional programming is finally winning out over OOP.You're making an either/or distinction here without any reason. You could just as well say, "The number of cars that recently added anti-lock brakes gives significant evidence that ABS is winning out over seat belts."
I don't see these languages removing any OOP features, so I think what it shows is that functional features are either useful independent of OOP features, or complement them. (My personal belief is the latter: the languages I enjoy the most have both.)
⬐ DrDimensionBTW, I must admit I misspoke on the last sentence - obviously the property of a software system working and doing what the user needs is more important than simplicity.Too short a road from the obvious to the assumed...
⬐ noblethrasherImmutability was never incompatible with OOP, just the opposite in fact. Even Alan Kay often criticized languages like C++ and Java for encouraging the use of setters and, thus, “turning objects back into data structures”.C# is still one of my favorite languages (even though I use F# most of the time now), but I do admire Java for making it significantly more painful to write mutable rather than immutable classes; it's too bad that fact was lost on so many programmers.
Kudos for sharing the Rich Hickey video; it's one of my favorites of all time.
⬐ azth> but I do admire Java for making it significantly more painful to write mutable rather than immutable classes;Out of curiosity, how does it do that? As far as I know, everything in Java is mutable by default.
⬐ noblethrasherYou have to go through the extra ceremony of writing a setter.⬐ azthThe same applies to C# though, correct? Plus, I was thinking more of the lines of something like:Which Java does not prevent.class Foo { private int x = 0; public void bar() { this.x += 1; // Whoops! } } Foo x = new Foo(); x.bar(); // Mutating call.⬐ noblethrasherYes, the same applies to my beloved C#, but that language was much less hostile to immutability. Indeed, the prettier mutator syntax was even positioned as a feature once upon a time.To be clear, I'm the guy that insists on defining classes as either abstract or sealed, and almost always marks fields as readonly. But, I'm okay with the kind bounded mutability that you mentioned; clients of a `Foo` instance have to treat it as immutable.
Here is how I do OOP:
* I make classes to hide state, and hidden state is the same as being stateless.
* As I learn more about the problem, I start subdividing classes into smaller classes (not necessarily via inheritance).
* So, as my understanding of the problem increases, the number of class division increases, and by the pigeonhole principle, the amount of state approaches zero.
People that enjoyed this talk should check this out http://www.infoq.com/presentations/Simple-Made-Easy
Very interesting related talk about complecting things - "Simple Made Easy" - by Rich Hickey, inventor of Clojure:http://www.infoq.com/presentations/Simple-Made-Easy
If you're a Ruby person, maybe watch this version instead, since it's almost the same talk but for a Rails Conference, with a few references:
It might do that wildly inefficient thing...Or, you might do something where you have a list of pointers, and you point at a different value instead of mutating an existing value.
I haven't dug into the details of how immutable data structures can be made to work efficiently, but part of the charm is that in many cases you don't mutate the array at all. What I mean is, there are certain behaviors around mutation that programmers do because they can.
When you take away the ability to mutate data, you design differently and without side effects. All of a sudden testing becomes easier, faster, cheaper for large parts of your codebase. You have simpler solutions that are potentially easier to reason about because the complex (and sometimes elegant) solutions aren't so readily available.
A few talks that are around this style of thinking:
https://www.destroyallsoftware.com/talks/boundaries
https://www.youtube.com/watch?v=WpkDN78P884
https://www.youtube.com/watch?v=tq5SQ4W3gRI
http://www.infoq.com/presentations/Simple-Made-Easy
Boundaries are good, values are good, simple things that work together are good. The more we can take the good parts and form them together into a cohesive language/framework/platform, the better our software will be.
What I'm hearing is that Meteor doesn't play well with others and that you should make the decision to go with Meteor carefully since changing your mind later will require a ground-up refactor.This is pretty much my experience as someone who started working on a project where the lead dev had decided to use Meteor and then quit leaving a wonky prototype with "reactive data", poor performance and missing functionality.
Now, some would say "it's not Meteors fault the UI wasn't made well!" and then I'd reply "sure, but if Meteor didn't encourage (and it seems, require) tight coupling of the data access and presentation layers, then maybe we wouldn't have spent the last 3 weeks rebuilding the entire app from the ground up just to add some missing functionality and fix UI bugs".
Honestly, I really can't figure out the lack criticism I see of Meteor around here. All these comments to congratulate on an arbitrary step in version number? I see other articles of accomplishment with a fraction of the positive encouragement and many times the criticisms. Is there a silent majority, or did I spend the last few months being underwhelmed by Meteor because I'm missing something?
Meteor embodies, for me, a tool that makes things 'easy', rather than one that makes things 'simple'.
http://www.infoq.com/presentations/Simple-Made-Easy
Anyways, that's just one developers experience and opinion, take if for whatever you feel it's worth.
⬐ lingoberryMeteor doesn't require tight coupling between data access and presentation layers. Personally I use meteor with react.⬐ adamorsA lot of criticism of "new shiny tech" gets downvoted/flagged on HN so people don't even bother anymore, while another useless library in Go/Javascript gets pushed to the top of the front page.⬐ sferozeMeteor does make things easier, by making things simpler.It is much simpler dealing with Meteor's API's then working with documentation from 3 or 4 different frameworks that you need to accomplish the same kind of stuff Meteor does.
Meteor gives you a set of clean coherent APIS to work with to get stuff done.
Whenever the topic of "simplicity" in software comes up, I feel obligated to point to the superb "Simple Made Easy" talk:http://www.infoq.com/presentations/Simple-Made-Easy
From my personal perspective, I do not see Go achieving the kind of simplicity Rich talks so eloquently about. Instead, Go seems much more like an "easy" language.
An example of easy versus simple in the OP's article is pointing to on boarding: Sure, your on boarding of new engineers may be /easier/ because Go is an ostensibly "simple" (they actually mean small) and familiar syntax. But that does not imply any correlation with writing simple software. I would argue the difficulty of writing abstractions in Go (especially around channels) actually tends to yield the opposite!
Much like ORMs are a trap because they seem simple, so too are technologies which have such a specious quality of simplicity. It is important to establish how a given technology actually achieves simplicity in practice and I do not see how this article argues that successfully--that is not to say Go cannot achieve simplicity, but merely that this article does not seem to make a solid case, in my opinion.
⬐ edwinnathaniel> Much like ORMs are a trapIf that is the case, the same can be said with JavaScript, Rails, Ruby yes? (all of them looked simple yet you can screw up really bad, like awfully bad, like worse than Java complexity bad).
I use ORM to do simple-to-medium complex queries enough to avoid N+1.
My ORM also have tools around it to help me generate DDL from code as part of my build (of course one still have to ensure the generated DDL is correct with proper relationship and constraints and all that jazz, but my point stands).
My ORM gives me the ability to write in either JPQL and SQL to do certain tasks like deleting a bunch of rows based on conditions. Those are handy enough.
My ORM also helps me prevent against SQL injection attack too.
How are these abilities are "traps" for me just as much as the C++ complexity are traps?
⬐ 0xdeadbeefbabeI'd rather deploy go than clojure, but I don't know if the go authors achieved what Socrates and Rich Hickey had in mind.⬐ fedesilvaI agree with you. There is a difference between simple and simplistic. Easy is not always simple.⬐ NateDadI think most people assume that when people say Go is simple, they mean easy. I think it's exactly the opposite. Go is simple, but it's not always easy. It's like the difference between building a house using pre-fab walls, and building a house using studs and nails. Which one is easier? Probably pre-fab walls. Which one is simpler? Probably studs & nails. You don't need a crane to put the walls in place, you can do it with just a hammer and 1-2 guys. It might take a little longer, but you'll have exactly the house you want.Your simple/easy comparison with an ORM is a very valid one, I think. ORMs seem easy, but they're not simple, and often times their easyness at the outset causes complexity once you have to do anything that goes off the rails they've laid out for you.
But I think Go is the opposite of an ORM. There's very little magic, nothing gets done "for you". The code does what you tell it to do, no more, no less. Which means people reading the code can immediately tell what it does - it does what it says it does in plain terms.
⬐ ChaoticGoodimmutable goodness
Interesting question.One nice feature is that markdown makes text annotations explicit and obvious. There's no hidden styling. Empty lines don't have a font size. Its obvious when a bolded region doesn't bold the spaces between words. In the Rich Hickey[1] sense, markdown is much simpler than rich text editing because all you have to worry about is the semantics of your text (this is a heading) and not how its actually styled.
Weirdly, its kind of a huge throwback to LaTeX. Thinking of markdown as a "modern, simplified LaTeX for the web" seriously hits the mark.
⬐ shurcooLAgreed. I would summarize that as: it doesn't have hidden state. Which is nice.
> It is interesting how purity has a very strong allure - maybe our brains are naturally drawn to a reduced state of complexity, and thus energy consumption?Or maybe complicated more often than not is just not a "carefully balanced mix of grey" but more of a clusterfuck .. and we learned to be wary of it.
Have a look at this: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ MrBuddyCasinoI've seen most of his talks, actually I'm a fan. I wouldn't consider Clojure to be a good example of purity though - it has both LISP purists as well as FP purists (Haskell) against it. Actually it is quite pragmatic for running on the JVM and even has optional typing.If elegance and simplicity are achievable without making too many sacrifices, great! I'd choose Clojure over C++ any day.
This "manifesto", for lack of a better word, neatly exhibits the main problem I have with so many efforts to "improve programming" of this style: they focus on ease of learning as the be-all and end-all of usability. Coupled with the unfortunate rhetoric¹, it left me with a negative impression even though I probably agree with most of their principles!Probably the largest disconnect is that while I heartily endorse simplicity and fighting complexity—even if it increases costs elsewhere in the system—I worry that we do not have the same definition of "simplicity". Rich Hickey's "Simple Made Easy"² talk lays out a great framework for thinking about this. I fear that they really mean "easy" and not "simple" and, for all that I agree with their goals, that is not the way we should accomplish them.
How "easy" something is—and how easy it is to learn—is a relative measure. It depends on the person, their way of thinking, their background... Simplicity, on the other hand, is a property of the system itself. The two are not always the same: it's quite possible for something simple to still be difficult to learn.
The problem is that (greatly simplifying) you learn something once, but you use it continuously. It's important for a tool to be simple and expressive even if that makes it harder to learn at first, since it will mostly be used by people who have already learned it! We should not cripple tools, or make them more complex, in an effort to make them easier to learn, but that's exactly what many people seem to advocate! (Not in those words, of course.)
So yes, incidental complexity is a problem. It needs addressing. But it's all too easy to mistake "different" for "difficult" and "difficult" for "complex". In trying to eliminate incidental complexity, we have to be careful to maintain actual simplicity and not introduce complexity in other places just to make life easier for beginners.
At the same time, we have to remember that while incidental complexity is a problem, it isn't "the" problem. (Is there every really one problem?) Expressiveness, flexibility and power are all important... even if they make things harder to learn. Even performance still matters, although I agree it's over-prioritized 99% of the time.
Focusing solely on making things "easy" is not the way forward.
¹ Perhaps it's supposed to be amusingly over the top, but for me it just sets off my internal salesman alarm. It feels like they're trying to guilt me into something instead of presenting a logical case. Politics rather than reason.
⬐ ilakshYou think that Edwards doesn't know the difference between simple and easy to learn/use?> It's important for a tool to be simple and expressive even if that makes it harder to learn at first, since it will mostly be used by people who have already learned it!
Why is that important? Why can't a tool be simple, expressive, easy to learn and easy to use? What studies do you site for your viewpoint? There has been a lot of research in this area. Please reference the research that supports your claim.
Reason has been tried by Edwards and many other for decades. It hasn't worked.
⬐ sheepmullet⬐ jamii"Why can't a tool be simple, expressive, easy to learn and easy to use? What studies do you site for your viewpoint?"Perhaps it can be. But they are all design choices that are often at odds with one another. E.g. I've frequently used software that was easy to learn but hard to use.
Likewise I've used tools that were hard to learn because they had new abstractions but once you understood the new abstractions they were really easy to use. Etc etc etc.
> ...they focus on ease of learning as the be-all and end-all of usability.I see people jump to this conclusion on pretty much every post of this type. In this case it is clear from the authors work (http://www.subtext-lang.org/) that his focus is not on making programming familiar/easy to non-technical users but rather on having the computer help manage cognitively expensive tasks such as navigating nested conditionals or keeping various representations of the same state in sync.
> ...you learn something once, but you use it continuously.
Empirically speaking, the vast majority of people do not learn to program at all. In our research we have interviewed a number of people in highly skilled jobs who would benefit hugely from basic automation skills but can't spare the years of training necessary to get there with current tools. There does come a point where the finiteness of human life has to come into the simple vs easy tradeoff.
You also assume that the tradeoff is currently tight. I believe, based on the research I've posted elsewhere in this discussion and on the months of reading we've done for our work, that there is still plenty of space to make things both simpler and easier. I've talked about this before - https://news.ycombinator.com/item?id=7760790
⬐ iandanforthI explicitly advocate crippling tools and making them more complex if it results in them being easier to learn.The cost of a barrier to entry is multiplied by everyone it keeps out who could have been productive / creative / or found their passion.
The cost of a limited set of tool features is, arguably, that people will exhaust the tool and be limited. However I have never found this argument convincing given what was achieved with 64kb of memory, or even paper and pencil.
The typewriter, the polaroid camera, the word processor, email. All are increases in complexity and massive decreases in effort to learn and they all resulted in massive increases in the production of culture and exchange of ideas. Some inventions are both easier to learn and less complex (Feynman diagrams) but if I had to pick one, I pick easy to learn, every single time.
⬐ enraged_camel>> It's important for a tool to be simple and expressive even if that makes it harder to learn at first, since it will mostly be used by people who have already learned it!Not sure if I agree. Steep learning curves significantly hurt user adoption. This is especially true for tools that have lots of alternatives.
⬐ jonathanedwardsI've observed a definite correlation that people who like Hicky's simple/easy framework don't agree with mine. Personally I don't find it useful because it tries to separate knowing from doing.I also seem to disagree with people who emphasize "expressiveness, flexibility, and power". I think they are mostly a selection effect: talented programmers tend to be attracted to those features, especially when they are young and haven't yet been burned by them too often.
With such fundamental differences we can probably only agree to disagree.
⬐ sheepmullet"Personally I don't find it useful because it tries to separate knowing from doing."What do you mean? Learning and doing are quite different.
From a professional programmer point of view: If it takes me 6 months to learn a tool, and then the tool allows me to complete future work twice as fast (or with half as many defects etc) that is a great trade off.
⬐ thothamonRather than just agreeing to disagree, you could defend your beliefs with the best arguments and examples you have. You're opposed to expressiveness, flexibility and power? That's a somewhat surprising view. I'm interested in why.⬐ swannodetteI don't think this manifesto and the simple/easy framework are even really talking about the same things beyond the basic point around avoidance of incidental complexity. I think both viewpoints outline worthy goals with staggeringly different levels of scope. In the case of the manifesto there's hardly anything actionable beyond doing lots of mostly messy research. I think people find this frustrating, but so what? Lofty goals often arise out of the conviction theres far too much momentum in the wrong direction. In contrast I think the simple/easy framework is something a working programming can apply to everyday tasks and while unlikely to result in a radical shift it may perhaps bring some of us closer to seeing that even larger goals may be possible.
Nice to see another post addressing the biggest issue in Software Engineering head-on.This of course is nothing new - it's something Alan Kay has been telling us for more than 3 decades [1], who also has an enlightening talk addressing the biggest problem facing software engineering [2].
Before vanishing from the Internet node's Ryan Dahl left a poetic piece on how "utterly fucked the whole thing is" [3].
Steve Yegge also has dedicated one of his epic blog posts to "Code's worst enemy" [4].
More recently Clojure's Rich Hickey has taken the helm on the issue producing his quintessential "Simple Made Easy" [5] presentation, explaining the key differences between something that is "Easy", to something that is truly "Simple".
[1] http://mythz.servicestack.net/#engineering
[2] http://www.tele-task.de/player/embed/5819/0/?iframe
[3] https://gist.github.com/cookrn/4015437
[4] http://steve-yegge.blogspot.com/2007/12/codes-worst-enemy.ht...
I should have said "more modular" but I definitely don't mean that modularity comes for free in FP languages. Programmers are capable of writing rigid programs in any language but I do feel in my little experience of using FP languages it is harder to do so, or more obvious when you are doing so. I'll give it a try anyway.I think the modularity comes from most FP languages having fewer building blocks to work with than most OO languages. It's the same reason why users of OO languages with a ton of different building blocks (Java, C#, etc.) find more "minimalist" OO languages like Ruby refreshing. FP languages tend to take this simplicity even further. You essentially have just functions and modules (a place to group related functions). FP languages also usually don't have state, unless you want to emulate that in your program somehow.
To me it is about ditching the OO way of creating some representation of the circle of life or Kingdom of Classes hierarchy in your applications for just treating your program as data that goes through a sequence of transformations. Linear programs are always easier for me to understand than hierarchies.
Rich Hickey's Simple Made Easy[0] talk is a great overview of the subject. Now his talk isn't about modularity per se, but I think modularity is one of the many things that fall out of simplicity.
⬐ PaulHouleI think also the real complaint people have against mainstream OO languages, particularly Java, aren't around "inflexibility" but rather around total ecosystem complexity.For instance, in PHP there are JSON serialization and de-serialization tools built into the language and people just use those.
In Java on the other hand you have to pick a third-party library, find it in maven central, cut and paste it into the POM file which is a gawdawful mess because it is all cut-and-pasted so every edit involves a tab war so it hard to view the diffs, etc.
Then you find out that the other guys working on the system already imported five different JSON libraries, but worse than that, some of the sub-projects depend on different versions of the same JSON libraries which occasionally causes strange failures to happen at run-time, etc...
Ironically these problems are caused by the success of the Java ecosystem. When you've got access to hundreds of thousands of well-packaged software that is (generally) worth reusuing, you can get in a lot more trouble than you can in the dialogue of FORTH you invented yourself.
⬐ matwoodThis is a great point. Just look at the logging situation in Java.
I think it's simple in the "simple made easy" kind of way that Rich Hickey has spoken about [1]. I think something can be deep, refined, and simple. I'd also say that those are my favorite concepts. I guess it's what I think of when I use the word 'elegant'.It's really clean and straight-forward to use, but the simple components provide a lot of flexibility and power, while being easy to teach someone.
I use trello for just about everything, and I would have dropped it a long time ago if it took more than five minutes to show someone how to use the fundamental concepts. I can get them up and running in no time, and the users (even non technical users) tend to find all the interesting bits on their own as they go.
⬐ jimbokun"Trello at its core is just a list of lists. Very simple concept."So it's a Lisp!
I disagree. Simple things are _necessarily_ dense in their implementation because they're so exacting. Recall Simple Made Easy[0].
It's hard for me to submit to a philosophy for reasons like that it's beautiful, and that you will reach zen. Level 3 enlightenment sounds very cultish to me. :) I've dropped the notion of REST and been very happy with simple RPC, instead of contorting my mental model into resources or to align with the HTTP spec.I personally have found zen in applying simpler concepts to software development. Such as composition over inheritance to my API design, mixing in certain aspects like content negotiation or caching, when those complexities become necessary. Or separation of concerns, making sure endpoints don't do too much, and the realization of concerns vs technology [1]. Really thinking about the notion of simplicity as describe by Rick Hickley in Simple Made Easy [2]. Or "There are only two hard problems in Computer Science: cache invalidation and naming things"--putting off caching until an endpoint becomes a problem--and not worrying if my URL structure is RESTful.
Here's an example of an API that I find beautiful [3].
[1] https://www.youtube.com/watch?v=x7cQ3mrcKaY [2] http://www.infoq.com/presentations/Simple-Made-Easy [3] https://mandrillapp.com/api/docs/
What you mean to say is that Lisp is simple but not easy, but that's true of a lot of things.You might enjoy this: http://www.infoq.com/presentations/Simple-Made-Easy
fwiw, clojure supports polymorphism.http://clojure.org/multimethods
I encountered this recently but I'll try to give a (bad) explanation.
You'll call `function(thing, arg1, arg2, arg3);`. Another function will run on the arguments and return a dispatch value. For example, it will check what `thing` is and return `struct`. The `struct` version of that function is then run on the args and gives you your value.
In this way you can define several `close` functions based on dispatch value instead of one monolith nested if/else `close`.
I'm on the opposite side of the fence, OOP has never ever appealed to me. "Why would anyone want to use this crazy mess?" kind of thing. I'm sure I can learn to appreciate it with time but it's not a native paradigm to my mind.
I only have experience with lisps when it comes to functional programming but the reason I enjoy it is that it's simple. You have functions and you have data. Functions transform data to more data and the two aren't tightly bound. If you pass a function a value it will always return the same result if you pass it the same value.
THE clojure video: http://www.infoq.com/presentations/Simple-Made-Easy (I don't think he even says the word clojure in the entire hour presentation.)
> I wish developers would stop equating "complicated" to things "I don't understand".Rich Hickey's presentation on this topic should be required viewing for everyone: http://www.infoq.com/presentations/Simple-Made-Easy
It's easy cause it's familiar. But it's not simple.This excellent talk by Rich Hickey explains the difference http://www.infoq.com/presentations/Simple-Made-Easy
I like many of the author's points. Pragmatism, thinking instead of blindly following principles, pushing back against size as a metric for measuring responsibility. I think Robert Martin's work absolutely deserves examination and critique. However, I don't share the author's definitions of simple and complex.Stating that "binding business rules to persistence is asking for trouble" is flatly wrong. Au contraire, It's the simplest thing to do, and in most cases any other solution is just adding complexity without justification.
I don't feel that increasing the class count necessarily increases complexity, nor do I feel that putting several things into one class reduces it. A dozen components with simple interactions is a simpler system than a single component with which clients have a complex relationship. My views align more closely with those expressed [1] by Rich Hickey in Simple Made Easy.
Classes as namespaces for pure functions can be structured in any way; they don't have any tangible affect on complexity. "Coupling" is irrelevant if the classes are all just namespaces for pure functions. I also find that most data can be plain old data objects with no hidden state and no attached behavior. If most of your code base is pure functions and plain data, the amount of complexity will be fairly small. As for the rest, I think that the author's example of maximizing cohesion and the SRP are functionally identical. They both recommend splitting up classes based on responsibility, spatial, temporal coupling, or whatever other metric you want to use. Personally I prefer reducing the mingling of state, but I think they're many roads to the same place. Gary Bernhardt's talk Boundaries[2] covers this pretty well.
⬐ dasil003I too identify strongly with Rich Hickey's view on this. That's not to say Uncle Bob is wrong, but I don't think he is as clear a communicator. I see Uncle Bob as having a lot of wisdom that he is able to apply based on his experience but which becomes very hand-wavy when he tries to explain it.⬐ dozzie⬐ dkerstenUB happens to be flatly wrong. UB says that docucomments re-stating what the simple function does are excessive and bad. This is totally wrong when one looks at the generated documentation, but UB doesn't seem to use the documentation much. He seems to be one of the people who prefer digging through the code, even if presented with sensible API documentation.⬐ dasil003I understand he's a polarizing figure and is overly prescriptive of things that are a matter of style, but his stance on documentation doesn't seem germane here.I'll add this to your links: https://www.youtube.com/watch?v=cidchWg74Y4He talks about his definition of "simple" (by digging into what the original English definition was) and what that means for code.
⬐ joevandykUnfortunately here, Rails encourages putting each class into a separate file, so you have 10 classes spread over 10 files, which does increase complexity.I dislike having a class/module per file.
⬐ lmmWhy do you say it increases complexity?If I'm in extreme mode I take the view that each file should be a single screen. That means a tangible reduction in the complexity of working on them (no more scrolling - each class is just in its own tab).
⬐ alttabThis can be solved with standard IDEs. Putting two modules or classes into a single file pretty much guarantees a level of coupling. This does not reduce complexity.⬐ kasey_junk⬐ rpedelaBy that definition, I could just as easily argue that requiring different files for every class reduces cohesion. The idea that class definitions and file definitions are in any way related is a leaky abstraction.⬐ doorhammerI've never been a fan of the class-file coupling. It pulls me out of the mental model I'm trying to build in my head and forces me to think about file organization which is almost always inconsistent with the language semantics I'm dealing with.I've used IDE's that make this more or less painful, but none that actually solved it. If anyone has any suggestions on one that does, I'd be interested to try it out. I don't really care what language. I can pick up enough to see what it feels like.
I also want to say that rich hickey talked about a file as a unit of code not being very good, but I don't recall where, or if he really said it. I want to say it was in a Datomic podcast right around when details about it were coming out.
⬐ gphilI think it's this podcast, where Rich Hickey explains codeq:http://thinkrelevance.com/blog/2012/10/12/rich-hickey-podcas...
That is standard practice in many languages.⬐ kylloIn Django (the closest thing Python has to Rails) the convention is to put all your models in one models.py file. I also prefer it this way.⬐ zachroseInteresting. In CommonJS modules, a file can only export one thing. You could namespace multiple things into one exported object, though I find that granular dependencies can lead to insights about how reusable your modules really are.⬐ tragicHaving worked with both, there's a trade-off. Given that in Django you're (mostly) explicitly importing classes and modules rather than autoloading, it's handy to have them all in one place. OTOH, when your project grows, you end up with enormous model files (especially if you follow the fat models/thin views pattern). So you then have to split them into different apps, so fragmentation slips in eventually anyway. (In a rails project, unless you're bolting on engines and such, all your models are at least in one folder).Where I definitely do prefer Django in this regard is that models declare their data fields, rather than them being in a completely different part of the source as in AR (not Mongoid, I now realise). Do I remember the exact spelling I gave to every column when I migrated them months ago? No. It's good to be able to see it all in one place rather than having an extra tab to cycle through. I don't see any practical benefit from decoupling here.
⬐ kylloEspecially since the Rails way is not "decoupling" in any real sense. Splitting tightly coupled code into multiple files != decoupling.I also like that in Django, you declare the fields on the models first and then create the db migrations from them, rather than writing a db migration first to determine what fields the models have.
⬐ tragicIndeed, decoupling is probably the wrong word here: I haven't seen an ORM implementation that was not tightly coupled to the database layer, which in the end is surely the point of an ORM - to represent stuff from the database in application code. (I know some people consider this a bad abstraction, but whatever.)South/1.7 migrations is definitely the best way of the two to manage that coupling. Rails's charms lie elsewhere.
⬐ kylloRight, and the debate raging in the Rails community now is whether your business logic should be in your models at all, or whether it should be extracted into plain old ruby objects, separating your domain model from your data model. Reason being, the OOP purists see it as a violation of the Single Responsibility Principle--an object should only have one reason to change, and the models are tightly coupled to the database schema so they have to change if the schema changes, plus you need to start up a database just to test their business logic, if you put business logic in them.Meanwhile a lot of the practically minded developers like DHH just accept that their objects will be tightly coupled to the database and just deal with it, claiming that anything else would be adding unnecessary layers of indirection.
I am pretty new to Django, but I get the impression that it's not so hard to just not put your business logic in models.py, and put it in separate classes of plain old python objects instead. Maybe that's why I haven't heard about this debate playing out in the Django community the way it is in the RoR community...
If you haven't seen it before, check out Rich Hickey's talk on the topic: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ the_watcherThanks! Never had seen it, really interesting.⬐ ludwigvanYou're off for a retreat if this is the first time you are seeing this talk!⬐ lgasAnd in case you missed any of the others, this is a great list:
Everything in life a tradeoff. You should watch this video: http://www.infoq.com/presentations/Simple-Made-EasyThe parens are annoying, until:
a) You build that fully composable library that you always wished you could have written in X language, but it neeeeever quite worked the way you wanted.
b) You realize that by keeping your data immutable, it allows you to write less tests, be more confident in your code, and you stop worrying "is that value is what I think it is?"
c) By building on top of the JVM, you are able to use java interop to save yourself a day of coding a custom library for something that exists and is well tested.
d) Deployment becomes a breeze because you just export a jar/war file and load it up into any of the existing app servers.
e) You get phenomenal speed increases for "free" if you're coming from dynamic languages like ruby/python/PHP
f) When you need to dip into async code, you can write your async code, in a synchronous fashion, which (for me) is much easier to think about then keeping track of callbacks in my head.
Good luck, if you decide to give it a shot, I think you might realize the parens isn't such a big deal in the long run!
That's almost the Clojure motto...See Rich Hickey's talk "Simple Made Easy" (http://www.infoq.com/presentations/Simple-Made-Easy).
That's very true and I think that it's related to the topic of Rich Hickey's talk Simple Made Easy [1].Maybe what we need is to study the economics of software and come up with a system in which market outcome is promotion of good libraries. I think that the social/economic dynamics of software development play a huge role in building a successful product, both free and commercial. Has anyone studied the subject in greater detail?
> Ultimately we shouldn't assume consumers value convergenceYep, indeed. And the frustrating part is that they choose "easy" over "simple" and end up drowning themselves in "complexity". And they go like "I have so many devices already, and I've already went through the pain of learning to use them, I'm not going to bother to learn the mobile app you talk about too, even if it you say it can replace them all and save me money, it's jut too much for my brain, this I already know, go away!". Big win for the sellers of these devices that are first to get to the market. Amazon will win big with these!
The interesting people is how can we educate consumers to value what we call "convergence", because their current way of thinking hurts both themselves (they end up spending more and being too "overloaded" to be capable to make the best shopping decisions, or the other extreme, having access only to "curated slices of the market" with the same consequences) and to the tech sector as a whole (yeah, more devices mean more innovation at start, but since convergence will happen anyway at a point, all we end up is reinventing wheels and generating tons of needless complexity that we drown ourselves in...).
(for a definition of how I use 'simple', 'easy' and 'complex' refer to - http://www.infoq.com/presentations/Simple-Made-Easy it's about programming but I think the metaphors also apply to UI/X)
The "worse is better" argument is in the context of Unix and C and cannot be separated from that context, otherwise it is meaningless.And a lot of thought went into Unix, as evidenced by its longetivity and long lasting tradition of its phylosophy. To date it's the oldest family of operating systems and at the same time, the most popular. Anybody that thinks the "worse" in the "worse is better" argument is about not carrying, is in for a surprise: http://en.wikipedia.org/wiki/Unix_philosophy
Even in the original comparisson to CLOS/Lisp Machines outlined by Richard Gabriel, he mentions this important difference (versus the MIT/Stanford style): It is slightly better to be simple than correct.
But again, simplicity is not about not carrying about design or the implementation and in fact the "worse is better" approach strongly emphasises on readable/understandable implementations. And simplicity is actually freaking hard to achieve, because simplicity doesn't refer to "easy", being the opposite of entanglement/interwiving: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ rjknight"Worse is better" can easily be separated from that context, though I would admit that most people do it incorrectly."Worse is better" is, ultimately, an argument against perfectionism. Many of the features of Unix could have been implemented in a "better" way, and these ways were known to people working at the time. But it turns out that those "better" options are much more difficult to implement, harder to get right and are ultimately counter-productive to the goal of delivering software that works. We can set up clear, logical arguments as to why doing things the Unix way is worse than doing things another way (e.g. how Lisp Machines would do it), but it turns out that the Unix approach is just more effective. Basically, although we can invent aesthetic or philosophical standards of correctness for programs, actually trying to follow these in the real world is dangerous (beyond a certain point, anyway).
I think that's pretty similar to the OP's argument that, whilst Haskell is clearly a superior language to Java in many respects, writing code properly in Haskell is much harder than doing so in Java because, probably for entirely cultural reasons, a programmer working with Haskell feels a greater need to write the "correct" program rather than the one that just works. Java gives the programmer an excuse to abandon perfectionism, producing code that is "worse" but an outcome that is "better".
I think I know what you're getting at, which is that a comparison between Unix and the monstrous IDE-generated Java bloatware described in the OP is insulting to Unix. On this you are correct. But for "worse is better" to be meaningful, there still has to be some recognition that, yes, Unix really is worse than the ideal. Unix isn't the best thing that could ever possibly exist, it's just the best thing that the people at the time could build, and nobody has ever come up with a better alternative.
⬐ chriswarboI think Worse is Better can be used by either side. You seem to be on the "Worse" side, ie. the UNIX/C/Java side, and claim the moral of WIB to be that perfect is the enemy of good. That's a perfectly fair argument.However, on the "Better" side, ie. the LISP/Haskell side, the moral of WIB is that time-to-market is hugely important. It's not that the "Better" side was bogged-down in philosophical nuance and was chasing an unattainable perfectionism; it's that their solutions took a bit longer to implement. For example, according to Wikipedia C came out in '72 and Scheme came out in '75. Scheme is clearly influenced by philosophy and perfectionism, but it's also a solid language with clear goals.
The problem is that Scheme and C were both trying to solve the 'decent high-level language' problem, but since C came out first, fewer people cared about Scheme when it eventually came out. In the mean time they'd moved on to tackling the 'null pointer dereference in C problem', the 'buffer overflow in C' problem, the 'unterminated strings in C' problem, and so on. Even though Scheme doesn't have these problems, it also doesn't solve them "in C", so it was too difficult to switch to.
Of course, this is a massive simplification and there have been many other high level languages before and since, but it illustrates the other side of the argument: if your system solves a problem, people will work around far more crappiness than you might think.
More modern examples are Web apps (especially in the early days), Flash, Silverlight, etc. and possibly the Web itself.
⬐ dllthomas⬐ bad_userMy understanding was that C did not have tremendous adoption by '75.⬐ NAFV_P> The problem is that Scheme and C were both trying to solve the 'decent high-level language' problem, but since C came out first, fewer people cared about Scheme when it eventually came out. In the mean time they'd moved on to tackling the 'null pointer dereference in C problem', the 'buffer overflow in C' problem, the 'unterminated strings in C' problem, and so on. Even though Scheme doesn't have these problems, it also doesn't solve them "in C", so it was too difficult to switch to.C is quite odd in that the programmer is expected to pay dearly for their mistakes, rather than be protected from them. BTW it wouldn't be as much fun if they were protected.
Regarding Scheme, it has withstood the test of nearly forty years very well.
⬐ bltC is unique because it's really easy to mentally compile C code into assembler. Scheme is more "magical".The more I learn about assembler, the more I appreciate how C deals with dirty work like calling conventions, register allocation, and computing struct member offsets, while still giving you control of the machine.
On the other hand, some processor primitives like carry bits are annoyingly absent from the C language.
I do not agree. "Worse is better" emphasizes on simplicity - and as example, the emphasis on separation of concerns by building components that do one thing and do it well. It's actually easier to design monolithic systems, than it is to build independent components that are interconnected. Unix itself suffered because at places it made compromises to its philosophy - it's a good thing that Plan9 exists, with some of the concepts ending in Unix anyway (e.g. the procfs comes from Plan9). And again, simplicity is not the same thing as easiness.> Haskell is clearly a superior language to Java in many respects, writing code properly in Haskell is much harder than doing so in Java
I do not agree on your assessment. Haskell is harder to write because ALL the concepts involved are extremely unfamiliar to everybody. Java is learned in school. Java is everywhere. Developers are exposed to Java or Java-like languages.
OOP and class-based design, including all the design patterns in the gang of four, seem easy to you or to most people, because we've been exposed to them ever since we started to learn programming.
Haskell is also great, but it is not clearly superior to Java. That's another point I disagree on, the jury is still out on that one - as language choice is important, but it's less important than everything else combined (libraries, tools, ecosystem and so on).
⬐ NoneNone
These are some notes on Rich Hickey's amazing simple made easy presentation.I've desperately been needing something to link to when trying to get people using this vocabulary, but the only options were the hour-long video, or the slides which lacked a little bit too much context.
This is only some of the most important parts i needed to share in the first half, there's so much more in there. I highly recommend watching the whole thing
Rich Hickey - Simple Made Easy http://www.infoq.com/presentations/Simple-Made-EasyChanged how I think about a lot of stuff, made my design process a lot more rigorous, and my projects more successful.
⬐ jawacheAgreed, changed my thinking completely now when people use easy and simple I explicitly try to clarify their meaning.
I found Rich Hickey's dissection of simplicity to be dynamite as usual: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ AdrianRossouwthis was a great watch. thanks for that.It helped me focus a lot of things I have been feeling innately for a while.
⬐ etherealGspot on. his way of putting it that simplicity is objective and ease subjective really nails it. most people say simple and mean easy.
In order to understand the frame of reference for Om, you really need to watch some Rich Hickey presentations [1][2] (or have a good understanding of functional programming). The first one is more relevant to your questions here, the second is just because Clojure programmers have very specific definitions of "simple" and "easy" and because it's a good talk.[1] http://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hic... [2] http://www.infoq.com/presentations/Simple-Made-Easy
That said, on to answering your questions:
> If data changes, it needs to mutate, right? ...
Data doesn't change in this model (see [1]). Incoming events (keyup, network request, page load) occur and your program responds to those events by producing a new, immutable set of data that you're going to use going forward. Om apps keep one reference to the root of the data tree–Om examples use app-state as the name–which represents the official current state of the data. You can reasonably argue that swapping out app-state is changing data except that anything that had a reference to the previous root(s) still has that reference and you have to go dereference app-state to get the current value instead of having it changed out from under you.
> If that's the way, how can you efficiently do updates on relatively large chunks of data? ... Or am I missing something and is it really not that bad?
[3] http://eclipsesource.com/blogs/wp-content/uploads/2009/12/cl...
Clojure(script)'s data structures use structural sharing. The above picture shows inserting a single node into the middle of the structure. The red outlined nodes are the parents which need to be copy+updated, as shown on the right with all the dotted lines being shared references. The most misleading thing about the picture is that the actual cljs trees have 32 branches at each node instead of 2 or 3 so the lookup time is log32 N (basically constant [4], impl in a systems language vs classic datastructures for comparison). In your Gmail example you'd have to make ~3 new nodes.
[4] https://github.com/michaelwoerister/rs-persistent-datastruct...
> In general, doesn't this make model code much much more complicated?
It requires a different mindset and generally some helper code. In Clojure using Om it's pretty straightforward once you're over the initial hurdle. In javascript using Mori [5] it looks a lot like awkward Backbone with very heavy Underscore use. I've poked around at it and if I were going to try to adopt Mori+React for a real project I'd want to do some quality of life tweaks on Mori. Mostly setting a prototype on the Mori objects to get the feel closer to Backbone+Underscore and trying to get the data structure console output to be more useful.
{kind=link}
⬐ skrebbelThanks a lot for the detailed explanation. I'll watch the videos (saw the Simple/Easy one already, they're good definitions of the words and it would be great if they'd be adopted more broadly outside the Clojure community too).I think I'm catching the drift here. This app-state variable was the concept I was missing. That, and how smart the Clojure(Script) data structures really are.
Mori looks pretty damn nice, actually. Would consider using it in practice.
This is what Alan Kay means when he says, "IQ is a lead weight." [1]Also see Rich Hicky's talk "Simple Made Easy." [2] In which he suggests that nobody's that smart; you will always hit a brick wall without the tools to manage complexity. "A juggler can juggle 3 balls. A really good juggler can juggle 9. But no juggler can juggle 90 or 900 (paraphrased)."
[1] http://www.tele-task.de/archive/video/flash/14029/ [2] http://www.infoq.com/presentations/Simple-Made-Easy
The biggest limitation of functions is precisely what you point out: they create scopes. So you end up complecting (http://www.infoq.com/presentations/Simple-Made-Easy) what variables you need access to at a time with what variables you want to describe and explain at a time.I don't think it's controversial that functions have limitations. For example, OO in many ways was an attempt to work around the limitations of functions. But what OO discovered, I think, was that any sort of modularity mechanism when baked into the language brings in its own constraints, which limit the situations where it can be used. The classic example is all the constraints on C prototypes that make any sort of refactoring of include files an NP-hard problem, dooming lots of codebases to never get the reorganization they need to free them from historical baggage. So I've gradually, grudgingly started to focus on more language-independent, tool-based approaches that can overlay an 'untyped' layer atop even the most rigid language.
"Because variables are accessible and manipulable in your snippets there isn't any containment like you get with functions."
My claim (http://akkartik.name/post/readable-bad) is that in seeking local properties like containment/encapsulation we deemphasize global understanding. Both are useful, certainly, but they're often in tension and our contemporary rhetoric ignores the tension. The pendulum has swung so much in favor of local rules for 'good style' that it's worth temporarily undoing some of that work to see what we're giving up, what the benefits of playing fast and loose with local structure might be.
"..following the flow of control is a little more difficult.."
Yeah that's a valid concern. I think literate programming failed to catch on partly because we need at times to see the entire flow of control in a function. Like when we're debugging. I have a vague vision that programmers of the future will work with the expository and 'tangled' views of a program side by side. (In addition to perhaps a view of the runtime execution of a single unit test: http://akkartik.name/post/tracing-tests.)
Your point about reusing snippets is also a good one. That's the benefit of naming fragments in literate programming, isn't it? I hadn't considered that; the examples I've seen never mention it. But emacs org-mode and http://leoeditor.com certainly seem to find reuse useful. Hmm. I haven't encountered the need for reusing snippets so far. That might change, and we can probably come up with some syntax to support it if so. I suspect, however, that our languages already have plenty of primitives for enabling reuse. We don't need any extra tool or meta-linguistic support.
---
Clicking through to your profile I ended up at http://essays.kuntz.co/you-re-probably-not-for-hackers, which suggests we have kindred sensibilities about these questions! (Compare http://akkartik.name/about)
⬐ dkuntz2I think the emphasis on containment and local understanding is good, especially considering that programs are getting huge (which is a separate problem, and what I think really needs to get fixed). With huge programs it's infeasible to fully comprehend the whole program, which means the only thing you can really do is hope that other programmers' functions work as advertised, and focus on perfecting your local domain.The easiest way to alleviate this, in my opinion, is to focus on building smaller programs which focus on doing one thing well, and combining those together to create larger applications, with preferably a minimum of glue code. In my mind this leads to even more containment as each domain is now accessible only through the specified API.
This could lead to similar problems that you have with the deemphasis of global understanding, because it's still compartmentalizing things, and at each higher level the programmer is just trusting that the lower levels have implemented what they said they would, just like in a huge, single program.
The idea of being T-shaped specifically when it comes to the overall knowledge of the projects you work on seems to be the best way to work on those applications: have a general understanding of the whole project, and a really good understanding of your specific domain (and perhaps an intermediate understanding of those around yours).
That's dangerous territory, given Clojure creator Rich Hickey has been staking a compelling claim to exactly that for years: http://www.infoq.com/presentations/Simple-Made-Easy
> OOP is widely-used and easily comprehended because it is a fairly simple way of modeling reality that is compatible with how human beings do it.Have we not learn by now that these systems are not easy to reason about. Are not all the things one first learns (ie Animal -> Dog) bullshit and should be avoided.
Why is it in every good OO book that, composition is better then inheritance. Why is every OO book full of examples about how to avoid mutabiltiy and make the system easy to reason about?
The idea that OOP systems (as generally) thougth of goes completly out of the window as soon as you have any kind of concurency, even just event handling.
> which rejects OOP
It does not reject, it takes the usful features like polymorpism and gives them to you. Protocols are better then interfaces, better then duck typing.
> In Clojure, if I want to define a symbol there are nine different ways of doing so.
There are a lot more then nine. But I would recomend rich or stus talks on simple vs easy. Just saying there is nine of something and thus its complicated is idiotic.
Java has only one thing, classes, does that make it simply, or does that just mean that its hoplessly overloaded?
Clojure is extreamly simply. State can only live in a var, atom, ref or agent. Every one of these has clear semantics, this includes clear sematnics in a multithreaded world. No other language has such clearly defined state management.
> Clojure claims to include these language features as a way to mitigate the complexity of parallelism; frankly, I’ve never found threading or interprocess communication to be any sort of conceptual bottleneck while working on some fairly complex distributed systems in Python.
Distributed system != Shared Memory
Nobody, really nobody can say taht distributed systems are easy. Just listen to the people that implment this stuff. But it is clear that a language generally does not really help you with reasoning about that system.
However when you run on a 16 core with shared memory and you have to do lock ordering and all this stuff,then you will defently be happy for the tools that clojure provides.
> Less is more (as long as “less” is sufficiently convenient).
Clojure is actually a much smaller and much simpler langauge then python every can hope to be. Clojure is simple, and strives for simplicity in every feature of the langauge. See here:
- Simplicity Ain't Easy - Stuart Halloway http://www.youtube.com/watch?v=cidchWg74Y4
- Simple Made Easy http://www.infoq.com/presentations/Simple-Made-Easy
⬐ vezzy-fnordTo add on to the OO counterargument, here's a thorough debunking of object-oriented programming: http://www.geocities.com/tablizer/myths.htmNote that this refers to the Nygaard interpretation of OOP, which is also the most widely used: rigorously class-based and in many ways retaining a procedural nature.
Smalltalk and Eiffel are different beasts, but they never really made it.
⬐ Ygg2OOP isn't be all end all, and it isn't really easy to get into. But, that doesn't mean that modelling hierarchies is not necessary in some domains. E.g. DOM was a very big reason why Rust was considering adding OOP. The performance and the readability is hurt when you don't have to represent hierarchy.Article simply says that giving ALL programmers power to design language leads to bad things. Lisp, Clojure, etc. And I can see why. People love making their own languages, it's fun, but a good programmer and a good language designer are two mostly unrelated things. Good programmer often needs to look at problem from a weird angle, while a language designer needs to find shared views. I'm not saying they don't have a lot in common as well, but I can see how programmers can design AWFUL languages.
Note: Good programmer means a good general programmer i.e. someone that solves various tasks in his favorite programmer language.
⬐ nickikTwo points1. > But, that doesn't mean that modelling hierarchies is not necessary in some domains.
Agree but the addition of full OOP seams overkill to reach this goal. Look at this clojure code:
>(derive ::rect ::shape) >(derive ::square ::rect) > (parents ::rect) -> #{:user/shape} (ancestors ::square) -> #{:user/rect :user/shape} (descendants ::shape) -> #{:user/rect :user/square}
Clojure gives you hierarchy 'À la carte'. This means that you know longer tie the two things together, it easy in clojure for example to have many diffrent hierarchy that are independent but still dont get in each others way. Modeling the same with objects is hard. Just a example, for often good reasons multiple inheritance is not allowed in most languages, however if you use hierarchy as a domain model and not as programming model you generally want it.
2.
I agree with the articles point, people should not invent there own langauges for everything, however that is a terrible reason to discard the language for 'large scale' production use. Every language has features that generally should be avoided, every language make it easy to do the wrong thing. Macros are relatively easy to understand, compared some other language features I could name. Also the effect of macros is generally local, unlike say monkey patching.
⬐ Ygg2> however that is a terrible reason to discard the language for 'large scale' production useI think article by `large scale` means something that needs lots of people working on it. I can see how several programming departments might form their own lisp-tribes that can't speak to each other because they disagree over tiny details (or engaged in power play).
⬐ nickikThe same thing can happen in any language and with any detail. Power play normally is political not really about language.Also one could easly argue that macros help with this situation because the 'right way' can be encoded in a macro and then you can require everybody to use it. That seams a better solution then long documents that explain in detail how X is done (because the langauge can reduce the code dublication). I remember such things in my (short) C++ experiance.
⬐ Ygg2Or just use a language that has one way of doing things? C++ with it's pre-compiler magic, and several (three or four ) ways to define a variable is a rather bad example.Things like this are bumps on a road, where your organization is a car with bad suspension. Sure, bad suspension will cause problems down the road, but no reason to drive your car through rocky terrain.
This sounds like a case of simple, not easy: http://www.infoq.com/presentations/Simple-Made-EasyYou could add a timestamp to each todo with two changes:
https://github.com/swannodette/todomvc/blob/gh-pages/labs/ar...
https://github.com/swannodette/todomvc/blob/gh-pages/labs/ar...(defn handle-new-todo-keydown [e {:keys [todos] :as app} owner] ... (om/update! app [:todos] conj {:id (guid) :title (.-value new-field) :created-at (js/Date.) ;; <-- add this line :completed false :order (count todos)}) ...)(defn todo-item [{:keys [id title editing completed] :as todo} {:keys [comm]}] ... ;; change this line (dom/label #js {:onDoubleClick #(handle-edit % todo m)} (str (:title todo) (:created-at todo))) ...)
I think that was Rich Hickey's "Simple Made Easy" talk: http://www.infoq.com/presentations/Simple-Made-EasyI think one of his most important points is that objects are good for representing, well, actual objects. As in, you have a mouse, or screen or some little robot that you are controlling through code. And that's all they are good for.
Need a way to define a bunch of static methods and avoid name collisions? - you want a namespace.
Need a place to store a bunch of data about something? - you want a associative array.
Need a way to call the same function on different types? - you want an interface.
I'm not sure about this, but I suspect part of the problem stems from the fact that object-oriented languages (usually Java these days) are the first language that students are exposed to. Once you start thinking in OO abstractions, it takes some effort to break out of the mindset.
Joda's impression of Scala is very insightful and it shows that Joda is an awesome engineer. But first of all, Joda was also careful to explain in his second post (the one that was meant to go public) that Scala didn't work in their own freaking context and that all platforms suck depending on perspective.Let me address some of the points raised ...
(1) Scala is difficult for Java developers to learn, because Scala has new concepts in it, like type-classes or monads and these concepts are exposed within a static type system. Are these concepts useful? After using Scala for the last 2 years, I can bet my life on it. However there's a learning curve involved and Scala is definitely more expensive to learn than Java. That's why context matters. If a company has the resources to invest in this learning curve, then it's worth it, otherwise it isn't.
(2) Scala is not complex as Joda mentions. Not in the original sense of the word "complex". Scala is in fact pretty simple, as the features exposed are pretty well thought and orthogonal. But those features are powerful. The real complexity comes from its interactions with the JVM, as they had to do some compromises. It's important however to differentiate "easy" versus "simple". See this awesome talk by Rich Hickey ... http://www.infoq.com/presentations/Simple-Made-Easy
(3) As any new community, the Scala community started by doing lots of experiments, pushing its syntax and its type-system to its limits, going as far as to use features that aren't fully baked yet. This happens with languages that try new techniques. But as the community is maturing, those problematic edge cases get flushed out and there are fewer and fewer libraries that go nuts, as more and better best practices emerge.
The favorite example of Scala bashers is the Dispatcher library, that originally went nuts over operator overloading, but that was rewritten [1] and these days Scala libraries are actually quite sane and elegant.
Also, there's nothing wrong with the existence of experimental libraries, like Scalaz. Contrary to public opinion, it's not in wide usage in Scala projects, it's very useful for people that need it and such projects end up exposing weaknesses and pushing the language forward. The existence of libraries like Scalaz is a virtue and really, people work on whatever they God-damn please, you can't blame a whole community for it. Joda used it as an example for the dramatic effect, in a private email, OK?
(4) SBT's syntax looks awful until you get the hang of it, because it uses operator overloading to achieve a declarative syntax for building an immutable data-structure that describes the build process. This syntax will likely get fixed, but it's also a really pragmatic tool and I now use SBT even for Java projects and I miss it when working with Python/Ruby. There's also a Maven plugin as an alternative and Joda mentions the stalled Maven plugin and its lack of support for incremental compilation, however that's no longer true.
(5) Joda mentioned problems with the upgrade cycle. Scala 2.8 should have been in fact called Scala 3.0, as the changes in it were dramatic, which is why when Joda wrote that email, many companies were still on 2.7 and the upgrade to 2.9 scared the shit out of people. However, things are a lot better these days. Minor versions no longer introduce backwards compatibility issues, so if you're using 2.10.3, then you won't have any problems with libraries compiled for 2.10.x and you can even use many libraries compiled for 2.9. It's much more stable.
In regards to why is backwards compatibility affected by new versions, well it happens because the standard library hasn't stagnated. Java has awful pieces of junk in its standard library that were never pulled out or redesigned, but as a new and still growing language, Scala cannot afford to freeze its standard library. And we are not talking about major changes here, just a simple addition of a method to a base interface can trigger the necessity for recompilation.
But these days there are a lot of useful libraries with multiple contributers and that get compiled for newer Scala versions as soon as those versions come out. And personally I haven't bumped into problems because of it, as upgrades for the stack we've been using have been really smooth.
(6) At my old startup, we've built a web service that was able to handle 30,000 requests per second, with responses being processed in under 10ms on average, using only 10 EC2 h1.medium instances. Actually we started by running that code on 10 Heroku dynos, but then moved to AWS for more control. And the code was written largely in a functional style, using Scala's standard immutable data-structures all over the place. People that complain about performance degradation do have a point in the proper context, but people that bitch about it based on other people's opinions or based on silly benchmarks, well such people don't know what they are talking about, especially since immutable data-structures help a lot with multi-threading woes, giving you room to efficiently use the resources available.
Actually, I think Joda's actions of eliminating Scala's data-structures or closures from the whole codebase, were excessive (and I'm trying hard not to say silly).
(7) It's all about the libraries. If every library you're using is a Java library like Joda mentioned they did (as Scala makes usage of Java libraries easy), then you might as well use Java as a language. But if you're using Scala's strengths and libraries built with Scala, with a Scala-ish interface and you like those libraries (e.g. Play, Akka), then Scala suddenly becomes inexpensible.
(8) Stephen Colebourne, for all his talent, is a douche-bag.
[1] http://code.technically.us/post/54293186930/scala-in-2007-20...
⬐ eepersonThe syntax got much nicer in SBT 0.13: http://www.scala-sbt.org/0.13.0/docs/Community/ChangeSummary...⬐ bad_userNote that I miss typed Coda Hale -> Joda. Dumb mistake. Sorry Coda :)⬐ the_watcher>> Scala is difficult for Java developers to learn, because Scala has new concepts in it, like type-classes or monads and these concepts are exposed within a static type system. Are these concepts useful? After using Scala for the last 2 years, I can bet my life on it. However there's a learning curve involved and Scala is definitely more expensive to learn than Java. That's why context matters. If a company has the resources to invest in this learning curve, then it's worth it, otherwise it isn't.This sounds similar to some of the stories about Twitter's switch to Scala. The developers who liked Ruby loved Scala, while the rest of the team stuck with Java, I believe.
⬐ dxbydt> The developers who liked Ruby loved Scala, while the rest of the team stuck with Java, I believe.Not true. But hey, its a free country. You can believe whatever you want.
⬐ the_watcherOr, instead of telling me that it's a free country, you could be productive, correct me and (ideally) provide a source. I'm happy to learn something new or have a mistaken belief corrected.⬐ dxbydtIts just my sense when I look at the git status of most of the private repos. Can't provide a source, sorry.
[Terms of Service: Let me start by saying that I admire the author's passion and effort to create something wonderful, and that this is not a crap on their project, but rather a reaction to their essay. And the fact that their essay raised a reaction to the point where I wrote something about it is, in this case, a testament to its quality.]Lisp programs can be represented as trees because they are trees. They can also be represented as lists, and this is because they are also lists.
The important difference between these representations is that trees the primary representation by which computers unravel the intent of a Lisp program and lists are the primary representation by which programmers express intent in their programs.
Sure some people sometimes picture their lisp program as a tree, but usually when a programmer pictures something as a tree, it is when viewing it as a data structure. Picturing a Lisp program as a tree is easier than picturing the tree represented by code in most other languages because of Lisps simple parsing process, but the way in which a programming language is parsed is an arbitrary feature of the language [though one worth design consideration].
Although it is easy to draw a tree. Often in Lisp and other languages, the verbal diagram "a list of lists of ..." is adequate to represent a tree along with a description of its interesting properties. Again, while the interesting properties can be represented graphically, what makes them interesting are the maths underpinning their structure not the aesthetics of their spatial representation.
"The purpose of this project is to assist the coder in developing more complex code faster and easier"
This is orthogonal to Rich Hickey's goal of making it easier and faster to produce simple code.
http://www.infoq.com/presentations/Simple-Made-Easy
We already have a great tool which allows graphic methods to be used easily to create complex code. It is called Excel.
⬐ cookingrobotExcel is a brilliant tool for solving problems that can be expressed as arrays. But its not that nice for trees. A first step to this project could be to make a satisfying experience for editing this kind of data. Here's an example: you have a list of categories and products. In excel today, you'll probably put category in column A and product in column B. But now you have lots of duplication of category ids. You can't change the category in one place like you'd be able to it was explicitly a tree, and rearranging branches of the tree is tedious. Creating arbitrarily deep sub-categories is a mess. If someone could make a good experience for this problem, then it might inspire ideas for the more complicated task of programming.⬐ pcmonkHm, interesting. I've always pictured my Lisp programs as trees. I think it's a more useful representation, but I see what you mean.You're right that this is orthogonal to Rich Hickey's goal. That's because I think his goal is great for writing simple programs. His goal is to make more programs simple, which is great. My goal is to make it easier to write complex code. As Fred Brooks talks about in No Silver Bullet, there are some problems that are accidental and some that are essential. Hickey is trying to solve the accidental problemms, and I'm trying to make it easier to solve the essential problems. Some logic is just inherently complex -- I want to create tools to make it easier to reason about.
And Excel is not nearly programmable enough to be better than a textual interface to solve the same problems. It's benefit is that it can be used (relatively) easily by non-programmers.
⬐ brudgersMy impression is that Rich Hickey is seeking ways to allow programmers to solve complex problems, without writing complex programs. He's been fairly successful relative to other people who write new languages.Excel is entirely programmable using the standard .NET stack and languages [from PowerShell to F#].
If the idea is to target the tool as a new IDE for experienced programmers, how does improve productivity over EMACS or Vim etc.? Or without it being an extension of one of those existing ecosystems, what is gained in exchange for all that is lost?
Which suggests to me that incorporating the functionality as an extension to one or more of those ecosystems might be more simple than competing with them for experienced coders.
Don't worry about needing to catch up. Stuff is moving so fast these days, you're always working with something new. Everyone is in a continual update mode so it's not like you have 10 years of catching up to do. Tech has turned over a 10 times since then. You could say 10 years and 2 years are functionally equivalent from a new tech point of view.And don't worry about corps and recruiters. Focus on a problem you want to solve, and update your skills in the context of learning what you need to know to solve that problem. If you can leverage your industry experience in the problem domain, even better.
Data is driving everything so developing a data analysis/machine learning skillset will put you into any industry you want. Professor Yaser Abu-Mostafa's "Learning From Data" is a gem of a course that helps you see the physics underpinning the learning (metaphorically of course -- ML is mostly vectors, matrices, linear algebra and such). The course videos are online for free (http://work.caltech.edu/telecourse.html), and you can get the corresponding book on Amazon -- it's short (http://www.amazon.com/Learning-From-Data-Yaser-Abu-Mostafa/d...).
Python is a good general purpose language for getting back in the groove. It's used for everything, from server-side scripting to Web dev to machine learning, and everywhere in between. "Coding the Matrix" (https://www.coursera.org/course/matrix, http://codingthematrix.com/) is an online course by Prof Philip Klein that teaches you linear algebra in Python so it pairs well with "Learning from Data".
Clojure (http://clojure.org/) and Go (http://golang.org/) are two emerging languages. Both are elegantly designed with good concurrency models (concurrency is becoming increasingly important in the multicore world). Rich Hickey is the author Clojure -- watch his talks to understand the philosophy behind the design (http://www.infoq.com/author/Rich-Hickey). "Simple Made Easy" (http://www.infoq.com/presentations/Simple-Made-Easy) is one of those talks everyone should see. It will change the way you think.
Knowing your way around a cloud platform is essential these days. Amazon Web Services (AWS) has ruled the space for some time, but last year Google opened its gates (https://cloud.google.com/). Its high-performance cloud platform is based on Google search, and learning how to rev its engines will be a valuable thing. Relative few have had time to explore its depths so it's a platform you could jump from.
Hadoop MapReduce (https://hadoop.apache.org/, http://www.cloudera.com, http://hortonworks.com/) has been the dominant data processing framework the last few years, and Hadoop has become almost synonymous with the term "Big Data". Hadoop is like the Big Data operating system, and true to its name, Hadoop is big and bulky and slow. However, there is a new framework on the scene that's true to its name. Spark (http://spark.incubator.apache.org/) is small and nimble and fast. Spark is part of the Berkeley Data Analytics Stack (BDAS - https://amplab.cs.berkeley.edu/software/), and it will likely emerge as Hadoop's successor (see last week's thread -- https://news.ycombinator.com/item?id=6466222).
ElasticSearch (http://www.elasticsearch.org/) is a good to know. Paired with Kibana (http://www.elasticsearch.org/overview/kibana/) and LogStash (http://www.elasticsearch.org/overview/logstash/), it's morphed into a multipurpose analytics platform you can use in 100 different ways.
Databases abound. There's a bazillion new databases and new ones keep popping up for increasingly specialized use cases. Cassandra (https://cassandra.apache.org), Datomic (http://www.cognitect.com/), and Titan (http://thinkaurelius.github.io/titan/) to name a few (http://nosql-database.org/). Redis (http://redis.io/) is a Swiss Army knife you can apply anywhere, and it's simple to use -- you'll want it on your belt.
If you're doing Web work and front-end stuff, JavaScript is a must. AngularJS (http://angularjs.org/) and ClojureScript (https://github.com/clojure/clojurescript) are two of the most interersting developments.
Oh, and you'll need to know Git (http://git-scm.com, https://github.com). See Linus' talk at Google to get the gist (https://www.youtube.com/watch?v=4XpnKHJAok8 :-).
As you can see, the opportunities for learning emerging tech are overflowing, and what's cool is the ways you can apply it are boundless. Make something. Be creative. Follow your interests wherever they lead because you'll have no trouble catching the next wave from any path you choose.
⬐ jnardielloThanks for this. Quite incredibly valuable comment. This is why i love HN.⬐ christiangencoI'm a web developer that considers myself "up-to-date" but there was quite a bit in there that I need to read up on (notably Hadoop and ElasticSearch). Thanks for the links!I'd also recommend, as some alternatives:
* Ruby as an alternative "general purpose language"
* Mongo as an alternative swiss army database
* Backbone + Marionette as an alternative front-end JS framework
* CoffeeScript as a better Javascript syntax
There's several good Clojure books. I'd start with Rich Hickey's video "Simple made Easy":http://www.infoq.com/presentations/Simple-Made-Easy
The "Joy of Clojure" is the best book on understanding the mid and high level constructs and design of Clojure (and FP). It's not a beginner book though - for that the books from the Pragmatic Programmers or Oreilly are excellent.
⬐ olegpThank you!
Yes, "Simple Made Easy" is a must watch imo. http://www.infoq.com/presentations/Simple-Made-Easy"Are we there yet" is also great: http://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hic...
I also love "Hammock Driven Development": http://www.youtube.com/watch?v=f84n5oFoZBc
This argument basically boils down to saying "frameworks are monolithic, and hence not flexible enough".I agree completely with this, the best antidote to this IMHO are the ideas from the lecture "Simple Made Easy" by Rich Hickey http://www.infoq.com/presentations/Simple-Made-Easy
He argues for an approach to framework development where all the different parts of the framework need to be 100% independent and interchangeable. Essentially, instead of a framework you should have 20-30 different libraries that can fully stand on their own but can be combined to give a framework-like result. You can call it the "Chinese Menu" approach to frameworks.
To see this approach in action, look at the different libraries for Clojure server-side development (Ring, Compojure, etc) which consist of tiny interchangeable libraries for specific tasks.
The new full-stack Pedestal framework also follows this philosophy (and in fact I am sure the Pedestal designers expect large chunks of this framework to be discarded as new approaches are tried withing their system, but the plug-and-play nature of all their libraries allows for effortless swapping of component libraries.) http://pedestal.io/
⬐ stcredzero> tiny interchangeable libraries for specific tasks.So, the UNIX folks had a good idea, then.
Simple != easy, as per this great talk by Rich Hickey:
⬐ JeanPierreTo get an even better explanation on what the word "simple" means and what it derives from, I would recommend "Simplicity Ain't Easy" by Stuart Halloway[1]. While it is very similar to "Simple made Easy", it focuses a lot more on the etymology of the words "simple" and "complex" and how people misuse the word.
In my mind Clojure is an easy win unless you're writing short running things that need to boot fast (though you could consider clojurescript + node for that).Both languages have good support for concurrency, but for me Clojure has much more going for it:
- It's fast, and has all the tooling and libraries from the JVM - it has immutable datastructures with literals for all of them) by default, this is huge, they're probably the thing I miss most when I have to use other languages. - It encourages functional programming very strongly, but has excellent support for managing mutable state when you need it. - It's very simple (it's a lisp) and has a very small number of primitives, with much of the standard library coming from macros rather than actually being baked into the language. - The community is amazing, #clojure on freenode is incredibly helpful and friendly towards noobs.
I probably don't sell it well, but I'd highly recommend watching some of Rich Hickey's talks to sort of understand the philosphy that goes into Clojure:
http://www.infoq.com/presentations/Simple-Made-Easy http://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hic...
Don't go for Go just because it's familiar ;)
As another child comment identifies, we should not confuse simple with easy. Clients want easy software, and they have little care or understanding of the complexity. That's OK, on its head, but it is our responsibility to share and teach this side of the software's lifecycle with "management" and "junior" developers. Rich Hickey, author of Clojure, had a great talk on simplicity and easiness of software [0].
It's so strange to me that people describe things like higher order functions and map/filter/reduce as being clever / complicated and think manual iteration and indexing into an array is "simple".I hate to keep linking to this talk because I don't want to look like too much of a clojure fanboy, but I think a lot of people would benefit from re-examining their definition of simple: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ jstellyAgreed. This is a wonderful talk for anyone who writes code in any language.
Great relevant talk: http://www.infoq.com/presentations/Simple-Made-Easy
Summary of the links shared here:http://blip.tv/clojure/michael-fogus-the-macronomicon-597023...
http://blog.fogus.me/2011/11/15/the-macronomicon-slides/
http://boingboing.net/2011/12/28/linguistics-turing-complete...
http://businessofsoftware.org/2010/06/don-norman-at-business...
http://channel9.msdn.com/Events/GoingNative/GoingNative-2012...
http://channel9.msdn.com/Shows/Going+Deep/Expert-to-Expert-R...
http://en.wikipedia.org/wiki/Leonard_Susskind
http://en.wikipedia.org/wiki/Sketchpad
http://en.wikipedia.org/wiki/The_Mother_of_All_Demos
http://io9.com/watch-a-series-of-seven-brilliant-lectures-by...
https://github.com/PharkMillups/killer-talks
http://skillsmatter.com/podcast/java-jee/radical-simplicity/...
http://stufftohelpyouout.blogspot.com/2009/07/great-talk-on-...
https://www.destroyallsoftware.com/talks/wat
https://www.youtube.com/watch?v=0JXhJyTo5V8
https://www.youtube.com/watch?v=0SARbwvhupQ
https://www.youtube.com/watch?v=3kEfedtQVOY
https://www.youtube.com/watch?v=bx3KuE7UjGA
https://www.youtube.com/watch?v=EGeN2IC7N0Q
https://www.youtube.com/watch?v=o9pEzgHorH0
https://www.youtube.com/watch?v=oKg1hTOQXoY
https://www.youtube.com/watch?v=RlkCdM_f3p4
https://www.youtube.com/watch?v=TgmA48fILq8
https://www.youtube.com/watch?v=yL_-1d9OSdk
https://www.youtube.com/watch?v=ZTC_RxWN_xo
http://vpri.org/html/writings.php
http://www.confreaks.com/videos/1071-cascadiaruby2012-therap...
http://www.confreaks.com/videos/759-rubymidwest2011-keynote-...
http://www.dailymotion.com/video/xf88b5_jean-pierre-serre-wr...
http://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hic...
http://www.infoq.com/presentations/click-crash-course-modern...
http://www.infoq.com/presentations/miniKanren
http://www.infoq.com/presentations/Simple-Made-Easy
http://www.infoq.com/presentations/Thinking-Parallel-Program...
http://www.infoq.com/presentations/Value-Identity-State-Rich...
http://www.infoq.com/presentations/We-Really-Dont-Know-How-T...
http://www.slideshare.net/fogus/the-macronomicon-10171952
http://www.slideshare.net/sriprasanna/introduction-to-cluste...
http://www.tele-task.de/archive/lecture/overview/5819/
http://www.tele-task.de/archive/video/flash/14029/
http://www.w3.org/DesignIssues/Principles.html
http://www.youtube.com/watch?v=4LG-RtcSYUQ
http://www.youtube.com/watch?v=4XpnKHJAok8
http://www.youtube.com/watch?v=5WXYw4J4QOU
http://www.youtube.com/watch?v=a1zDuOPkMSw
http://www.youtube.com/watch?v=aAb7hSCtvGw
http://www.youtube.com/watch?v=agw-wlHGi0E
http://www.youtube.com/watch?v=_ahvzDzKdB0
http://www.youtube.com/watch?v=at7viw2KXak
http://www.youtube.com/watch?v=bx3KuE7UjGA
http://www.youtube.com/watch?v=cidchWg74Y4
http://www.youtube.com/watch?v=EjaGktVQdNg
http://www.youtube.com/watch?v=et8xNAc2ic8
http://www.youtube.com/watch?v=hQVTIJBZook
http://www.youtube.com/watch?v=HxaD_trXwRE
http://www.youtube.com/watch?v=j3mhkYbznBk
http://www.youtube.com/watch?v=KTJs-0EInW8
http://www.youtube.com/watch?v=kXEgk1Hdze0
http://www.youtube.com/watch?v=M7kEpw1tn50
http://www.youtube.com/watch?v=mOZqRJzE8xg
http://www.youtube.com/watch?v=neI_Pj558CY
http://www.youtube.com/watch?v=nG66hIhUdEU
http://www.youtube.com/watch?v=NGFhc8R_uO4
http://www.youtube.com/watch?v=Nii1n8PYLrc
http://www.youtube.com/watch?v=NP9AIUT9nos
http://www.youtube.com/watch?v=OB-bdWKwXsU&playnext=...
http://www.youtube.com/watch?v=oCZMoY3q2uM
http://www.youtube.com/watch?v=oKg1hTOQXoY
http://www.youtube.com/watch?v=Own-89vxYF8
http://www.youtube.com/watch?v=PUv66718DII
http://www.youtube.com/watch?v=qlzM3zcd-lk
http://www.youtube.com/watch?v=tx082gDwGcM
http://www.youtube.com/watch?v=v7nfN4bOOQI
http://www.youtube.com/watch?v=Vt8jyPqsmxE
http://www.youtube.com/watch?v=vUf75_MlOnw
http://www.youtube.com/watch?v=yJDv-zdhzMY
http://www.youtube.com/watch?v=yjPBkvYh-ss
http://www.youtube.com/watch?v=YX3iRjKj7C0
http://www.youtube.com/watch?v=ZAf9HK16F-A
⬐ ricardobeatAnd here are them with titles + thumbnails:⬐ waqas-how awesome are you? thanks⬐ ExpezThank you so much for this!⬐ X4This is cool :) Btw. the first link was somehow (re)moved. The blip.tv link is now: http://www.youtube.com/watch?v=0JXhJyTo5V8
Simple Made Easy changed how I think about constructing software systems of any kind. It provided me with a strong vocabulary and mental model to identify coupling and design with a more clear separation of concerns and focus on the output rather than the ease of development.
⬐ coldteaDon't know, I like Clojure and Hickey, but I've never got much out of his talks.Seem more like a series of really obvious ideas and some platitudes thrown in for good measure.
⬐ marshray⬐ bsaulSo what's your favorite talk then?⬐ coldtea⬐ zerrFair question.One that immediately pops to mind is this:
⬐ anm8trWow. Great video; good referral.⬐ NoneNoneExactly. Except, ironically, I happen to like only Hickey, not Clojure. Rich has some great mood in his talks, and also makes good articulations.⬐ lifeisstillgoodReally, I nose-snorted coffee over this one:- everyone knows you cannot keep up the pace of a sprint over a long distance race - so they solved it by running a long distance race but just firing a starting pistol every 400 yards - and we're off again!Just rewatched it, and it is a good talk, but i always think the whole OO dismissal is a bit too extreme. I did code "generic data structure + functionnal language" program and "ORM + objects + states" and i didn't find any problem in both cases, because i used it when they were suited.A document based user application is basically a gigantic state. If you're using generic data structure such as loosely typed maps and sets, with separate functions in various modules for manipulating parts of that structure, you'll end up with a far bigger mess than if you're having a regular three tier MVC code with objects on the model layer (even with an ORM). I do think, and i have experienced it, that sometimes, regular OO is the good abstraction.
⬐ dougk16Just watched it...really great stuff. But can anyone chime in on how you can apply some of the principles in his talk to something like a retain-mode display library, for GUI or 3d for example? Libraries like these pop up in all popular OO languages and usually have long inheritance chains with very state-heavy classes, which further form somewhat rigid hierarchies of class instances at runtime. This violates some of his tenants in a big way, but they seem to be the predominant design pattern for getting stuff on screen. Even HTML5 is essentially like this.Any thoughts on how his talk could apply here? Is there a better way?
⬐ None⬐ emil0rNone⬐ ghotliView layers can get complex, but you can at the very least encapsulate complexity and have it interact with other parts of the system in a simple well defined way. Have the separate layers of the application communicate via interfaces that keep the ingress, egress points of data flow well defined. Things like event pub/sub systems can further decouple things, the observer pattern, etc.⬐ dougk16I meant that if I were designing a general-purpose retain-mode GUI library or 3d engine from the ground up and wanted to incorporate his principles as much as possible, how could I do that? Maybe a retain-mode approach is just inherently (too?) complex?Correct me if I'm wrong, but I think your answer is in reference to using such a library, and I can certainly see how my question implied that, so sorry for the confusion if this is the case. Thanks for your answer regardless.
⬐ snprbob86This is something I've been experimenting with. My intuition is that the scene graph will look a lot more like an AST made from algebraic data structures than an OOP actors network. Down that road, the system looks like an optimizing compiler with the really tricky added bit of iterating in response to user input.⬐ ghotliAt that level it's similar tradeoffs. Consider what the code would look like if it were purely functional. In fact a good answer to your question would be for a thought exercise take a look at how XMonad is implemented in Haskell. That would be a completely different approach to the large, heavily coupled messes that OOP can sometimes lead to when modeling the state as mutable object members.⬐ dougk16Thank you, I will look into that. Sorry, forgot to upvote you...fixed!I second Simple Made Easy. It put into words what I thought was wrong but never could formulate.⬐ toufiqueI third Simple Made Easy. Totally changed the way I think about complexity.⬐ NoneNone⬐ freijusKind of off-topic: I can't manage to see any video, is it slides and mp3 only ?⬐ toufiqueI third Simple Made Easy. Totally changed the way I think about complexity.⬐ jacobolusAlso see Stuart Halloway’s earlier talk, Simplicity Ain’t Easy. There’s a fair amount of overlap with Rich Hickey’s talk, but both are worth watching: http://www.youtube.com/watch?v=cidchWg74Y4And also his talk Radical Simplicity: http://skillsmatter.com/podcast/java-jee/radical-simplicity/...
Two great ones by Rich Hickey, the creator of Clojure -Are We There Yet? - http://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hic...
Simple Made Easy - http://www.infoq.com/presentations/Simple-Made-Easy
⬐ stretchwithmeYes, I was quite impressed with the second one. Haven't seen the first one.⬐ ravimbalgihttp://channel9.msdn.com/Shows/Going+Deep/Expert-to-Expert-R...this one is so far the best by the Guru himself
'Simple Made Easy'[1] is one of my favorite Hickey talks.
Haskell is also very simple--not from an implementation standpoint but from a semantics standpoint. Having polymorphism with no sub-typing (and no casting) is conceptually simple and easy to work with. Parametric polymorphism (like Java's generics but simpler and less horrible) is actually an extremely simple concept. The difficulty comes from a) implementing it in a stupid way after the fact (cough Java) or b) having sub-typing. Neither is necessary!In this day and age, semantics are far more important than implementation.
You can fit Haskell's evaluation rules and its typing rules on one page.
Haskell's syntax is also very simple and consistent. It has fewer constructs than most imperative languages--fewer constructs than anything short of Lisp. It just also happens to be much more flexible than other languages.
Moreover, much of Haskell's syntax is very transparent syntax sugar. You can easily desguar it in your head. It makes code nicer to read but does not add any real complexity because it trivially maps to a bunch of simple function calls.
Most of Haskell is a very transparent layer over a typed lambda calculus. Lambda calculus is basically one of the simplest possible constructs. Ignoring the type system for a moment, it has literally three concepts: functions, variables and application. We then throw in some very straight-forward extensions like numbers, add a bit of syntax sugar and a type system.
The type system is also surprisingly simple. It has to be, for the inference to work! It's also very consistent in the way that is almost unique to mathematics. Consistency is pretty important.
This is where I shall bring up the "Simple Made Easy"[1] talk. It comes up a lot in these discussions, for a reason: most people mix the two up. I don't agree with all the points in the talk, but the core message is completely correct and very valuable.
[1]: http://www.infoq.com/presentations/Simple-Made-Easy
Simplicity is valuable. And Haskell, for all its being hard to learn, is simple.
IO is a great example here. Monads are difficult to learn, granted. But they are not complex. Rather, they are abstract. In fact, monads are extremely simple; the actual difficulty is twofold: it's not immediately obvious why they matter and they're too abstract to permit any analogies. Ultimately, a monad in Haskell is just any type with three simple functions that behave consistently--it's just an interface.
Go is not particularly simple; rather, it's easy. It's familiar. The syntax is more arbitrary, but it is C-like. The built-in constructs like loops are more complex and arbitrary (Haskell, after all, has no built-in iteration at all), but hey, it's C-like. The exposed features? Again, fairly arbitrary.
That's how I would sum up Go's design: arbitrary. And mostly C-like. Where C itself is pretty arbitrary. Especially from a semantics standpoint.
Essentially, Go has whatever the designers felt like adding. Just look at all the different ways you can write a for-loop! Or the fact that you have a loop at all. Haskell, on the other hand, has a deep and elegant underlying theory which ensures that different parts of the language are all consistent.
Haskell is much less arbitrary. Most of the features naturally go together. Many are just generalizations or facets of the same concept. Even the complicated, advanced features like "type families" or "GASDTs" are just fairly natural extensions of Haskell's basic concepts. It's very much akin to mathematical ideas, which have an elegance and consistency eluding most other languages.
Here's a particular example of how the features fit together: algebraic data types. Haskell essentially has two fundamental ways to create data types: you can combine fields into a record (like a struct) or you can have a choice (a tagged or disjoint union). The really neat bit? These aren't arbitrary--they're actually deeply related. In fact, they're duals of each other. Having both makes the most sense.
It also gives you a much better way to signal errors. In Go, for whatever reason, errors are essentially built into the language as an implicit tuple. However, in practice, you either have a result or an error. If you have an error, the result is meaningless; if you have a result, you shouldn't have any error! So it makes much more sense to represent errors as a variant, a choice--a sum type. This lets Haskell avoid baking in error handling into the language, making it simpler.
Haskell is as mixed-paradigm as the languages you listed. Those languages are imperative with some weak support for functional programming. Haskell is functional with some weak support for imperative programming. It's the same idea, inverted. Except Haskell can also support things like non-deterministic and logic programming. It's just that, for some reason, when people say "mixed-paradigm" what they really mean is "imperative with some functional support" and never "functional with some imperative support".
Sure, Haskell's syntax for mutable structures is awkward. But have you seen C#'s or Python's or even Go's syntax for functional programming? Compared to Haskell, it's just as awkward! And Haskell's "syntax" for mutable constructs is just a library; it can be improved. It just turns out that imperative features aren't useful enough for experienced Haskellers to warrant the improved syntax. (Also GHC sucks at optimizing sufficiently complex imperative code, I gather.)
There's a nice example of what you can do on Lennart Augustss's blog[2]. He essentially embedded a very C-like language into Haskell without using macros. So it's certainly possible, just not worth it.
[2]: http://augustss.blogspot.com/2007/08/programming-in-c-ummm-h...
So yes, perhaps Haskell will never be popular. But that's a social issue. It is not an issue of the language's qualities.
And it shouldn't stop you from using Haskell. At your startupt. Hint, hint.
⬐ jules> You can fit Haskell's evaluation rules and its typing rules on one page.Evaluation rules yes, but typing rules? Once you add in features like records, GADTs, type classes, functional dependencies, type functions, equality constraints, associated types ... you end up with quite a complicated system. Maybe you can state it on less than a page if you use a small enough font, but the system is complex. In contrast, C semantics might be large, but they're not complex. Unlike with Haskell's type system, there are no difficult interactions among all the features.
That's one of the reasons people are investigating dependently typed languages. They can offer a simpler and more powerful type system.
In addition to this, the language isn't even the most difficult part. So much of the difficulty is in learning the libraries and concepts associated with the libraries (functors, applicative functors, monads, iteratees, zippers, arrows, etc.). This may be further along the "hard" axis than the "complex" axis, but it's definitely not simple either.
⬐ papsosouid⬐ sampsonjsActually, your examples serve to counter your argument. All of the things you mentioned are very simple, and are in fact implemented in terms of the core language semantics. They are also non-standard extensions, not part of haskell. You do not need to know them or use them at all.Your final part is just plain nonsense. That is like claiming C is complex because you need to learn things like hash tables and linked lists and binary trees.
⬐ julesDefine simple. You're appealing to the Turing tar pit argument. The fact that some core language is simple, doesn't mean that the language is simple in a practical situation. That applies to language constructs specified in terms of the core language and even more so to the libraries. We can define Common Lisp in terms of a small core language, heck we can even consider it a library of macros. That makes all the constructs in Common Lisp "just like" hash tables by your classification. Does that mean that Common Lisp is simple? Of course not. You have to consider what has to be learned in practice.If you think that e.g. the interaction between GADTs and functional dependencies is simple, that's crazy. These things may not be part of Haskell98, but they are part of Haskell from a practical viewpoint, and many libraries make use of these extensions. You will have to learn it if you want to do serious work in Haskell. The same applies to the library concepts.
⬐ papsosouidYou are simply making shit up at this point. You absolutely do not, ever, under any circumstances, need to learn or use GADTs or functional dependencies. That is complete and total bullshit. Using a library that uses those features does not require you to learn them, that is the entire point of a library, to hide that from the user of the library. And yes, common lisp is a simple language.⬐ julesHaha okay, I suppose if you think Common Lisp is simple, then Haskell is simple too. Most people however, consider Common Lisp the opposite of simple. As for the concepts that I mentioned, you explained it yourself very clearly in another comment of yours:> You need to understand monads to do anything beyond trivial exercises. It is something that virtually every single person coming to haskell from another language is unfamiliar with. I don't see how a focus on such a fundamental aspect of the language is a bad thing. -- http://news.ycombinator.com/item?id=5326342
⬐ papsosouidIf you think common lisp is complex, you have no idea what the words complex and simple mean. I know you have to know monads. That does not make haskell complex. Just like needing to know hash tables doesn't make C complex.Here's my challenge, echoing a comment further down: If you want to convert folks to Haskell, write something useful in it. Then people might actually be interested in learning more about it. That's the only way you'll get converts, not writing boring, condescending lectures. My programming language prof tried to use the entire course to indoctrinate students in Haskell. He failed. None of his ramblings about how "pure" Mondads or such and such was or any of his homework assignments ever convinced us that Haskell was a better way. I don't expect you to get much further. For me, the rub was that he never showed a real world application. I took that as proof that the whole language is asinine, and that the claim that it gets rid of the dreaded "state" was bs. Another thing that always irked me: pretending that mathematics has nothing to say about "state". That's pretty funny coming from Haskell fans, who like to fancy themselves mathematicians.⬐ tikhonj⬐ pekkOkay, it sounds like your course managed to sour you on Haskell without teaching you anything. Your entire tirade feels like a straw man born from ignorance. You even managed to misspell "monad".You're simply not in my audience at all--you have too much of a predisposition against Haskell. It's not worth trying to convince you, or anybody similarly biased, because there are so many other people willing to hear me out.
So yes, maybe I won't get any further than your professor. No big loss.
Anyhow, why do you think Haskell--the language with libraries dedicated to managing state--pretends that state doesn't exist? If anything, Haskell is the only language that takes any sort of mathematical approach for modelling (and thus managing) state at all!
There's a reason why some of the most progressive and mathematically sound ways of dealing with state--my favorite example is functional reactive programming--take root in Haskell. If all you want are mutable references and data structures, we have that too. Cleverly integrated with the type system, to boot. We even have some of the best concurrency features (which are naturally based on mutable state!) like STM. STM that's not only actually usable but actually easy.
As for software written in Haskell? There's already plenty. Pandoc is simply the best in its class--I don't think it has any real competition, even. XMonad is a great window manager. Darcs is a dvcs that existed before Git took off, and has a clever model. I use Hakyll for my website, as do some prolific HNers like gwern, and it's great. Gitit is a nice, lightweight wiki. Git-annex helps you manage files on top of Git. The backend for DeTeXify, which everyone using (La)TeX should be familiar with, is written in Haskell.
And these are just the things I could think of from the top of my head, mainly things I personally use.
All these are practical utilities that you might use. If you're willing to look further afield, there are all sorts of more specific tools like Agda and a host of DSLs for everything from SMT solvers to realtime embedded programming.
Then there are the rich and relatively impressive web frameworks like Snap, Yesod and Happstack. Yesod in particular is very fully featured and useable; it has some very cool sites built on top of it including the recently released School of Haskell.
What about stuff I'm personally working on? If you're playing around with the GreenArrays chip, I currently have a simple simulator for the F18A instruction set as well as simple system for synthesizing F18A code using a randomized hill-climbing algorithm. Unfortunately, both are currently limited to one core, but that should be easy to fix. I was also working on a DSL for generating F18A code, but that fell by the wayside recently.
So clearly people are writing tons of useful software in Haskell. And people are using it. But that obviously won't satisfy you. Which, as I said above, is fine.
But if you're actually somebody else--preferably either a startup founder or somebody with control over what technology to use--you should definitely give Haskell a whirl!
⬐ papsosouidThere's plenty of useful software written in haskell. Why is this particular nonsense so commonly repeated with haskell? Just because you don't bother looking at the software written in haskell, doesn't mean it doesn't exist.⬐ efnxJust browse hackage. http://hackage.haskell.org/package/simpleirc is a good starter.It is an issue of the language's qualities if it does not really make it easier to reason about code.I find reason to question the simplicity of something which is widely acknowledged to take a lot of time to learn, to be mind-bending, and which seems to be impossible to explain simply - without deep theoretical background, academic citations or oversimplifications acknowledged as misleading.
I think it would be mature for the Haskell community to occasionally acknowledge a trade-off of the language. Haskell's flaws are not all "social issues." The virtues of survivors like C and LISP are not all "social issues".
⬐ nightskiHrm, I have found the main benefit of Haskell is that it makes it far easier to reason about code. The separation of side effecting operations from non-side effecting is huge.Also I am very comfortable with monads and have never dug into the theoretical category theory side of it.
I bet you could be writing code in the IO monad within a day with some proper guidance. It really isn't hard at all.
⬐ tieTYTThat's not fair. Remember how long it took to learn how to program for the first time? Haskell is so different from imperative programming you should approach it like that.⬐ papsosouid>It is an issue of the language's qualities if it does not really make it easier to reason about code.The primary point of haskell is making it easier to reason about your code.
>I find reason to question the simplicity of something which is widely acknowledged to take a lot of time to learn, to be mind-bending, and which seems to be impossible to explain simply
It takes a long time to learn any programming language. You create an invalid comparison when you compare learning language X++ after already learning X to learning language Y++ without having learned language Y. Haskell only takes longer to learn if you compare it to learning a language that is virtually identical semantically to a language you already know. And I don't know why you think it is impossible to explain haskell simply, there's a reason everyone points to learnyouahaskell.com when people ask how to learn haskell.
>The virtues of survivors like C and LISP are not all "social issues".
How is lisp a "survivor" exactly? Haskell is more widely used than any lisp is.
⬐ rafcavallaro⬐ tikhonjThe tiobe index has lisp in the top 20 (at 13th) while Haskell is at 33rd, so lisp is more popular than Haskell even though lisp is over a half century old. Being in the top twenty after 50 years looks like the very definition of "survivor" to me.⬐ papsosouidLisp isn't a language, it is a whole bunch of languages. Lumping half a dozen languages together obviously moves it up the list. Being old is working in its favour, not against it. Older languages have more written about them purely because of the time they've existed. Pick a specific lisp and try your comparison again.Simple does not imply easy. As an extreme example, a unicycle is simpler than a bicycle--fewer components, simpler structure, no gearing--but also more difficult to learn.Really, I'll just have to point you to the "Simple Made Easy" talk again. The core point being that there's a difference between something being "simple" and something being "easy", and we should generally strive for the former rather than the latter.
Having a deep theoretical foundation is also not a sign of complexity. Instead, like most of math, it's usually a sign of simplicity. After all, math always strives for elegance and simplicity.
What it means is that a lot of smart people have spent a lot of time thinking things through using a strict framework for reasoning that ensures everything is consistent. The theoretical framework lets us simplify by recasting different concepts using the same fundamental ideas. If we can capture things like state, errors and non-determinism using a single concept, we've made things simpler because now we have a common ground and relationship between seemingly disjoint ideas. This is exactly what Haskell (and the theory behind it) does.
This theoretical foundation, coupled with the relative simplicity and consistency of the language, actually make code much easier to reason about in Haskell than in other languages, except for some performance issues. Basically, as long as your main concern is in semantics--and, for 90% of your code, it is--Haskell makes life easier than any other language I know. You can manipulate the code purely algebraically, without worrying about what it does, and be content that the meaning remains the same.
Having well designed libraries with actual algebraic laws governing their behavior, a powerful type system and very transparent syntactic sugar is what makes the code particularly easy to reason about. A simple, elegant semantics also really helps. You can really see the influences of a good denotational semantics when using the language.
Now, reasoning about performance is sometimes an issue. It's certainly reasonably hard without additional tooling. Happily, there are some nice tools like criterion[1] to make life easier for you.
[1]: http://www.serpentine.com/blog/2009/09/29/criterion-a-new-be...
Also, the Haskell community does acknowledge trade-offs. They're just not the same trade-offs that people not knowing Haskell lambast. Which should not be a surprise--you can't expect somebody who hasn't really learned Haskell or its underlying ideas to have a thorough idea of what its real problems (or even its real advantages) are.
⬐ joe_the_userWatching the video now...It seems beautiful, enlightening and wrong.
It might be described as a powerful statement of software idealism. Essentially, start simple and stay there, the problems, the mess, the mythical-man-months, etc all come because the developers refused the effort needed for simple and impatiently descended into the swamp of complexity.
I too, love starting simple and usually intend to stay there.
But the problem I would suggest, is the complexity will build up and simplity-as-the-simple-methods you've learned, simplity-as-such, can't fight this build-up. If being simple COULD put an end to complex situations, you wouldn't have to START simple, you could use simplicity to "drain the swamp of the complex". But every methodology more or less says that you have to be on the top of its mountain and to stay there (except original OO and we know how well that worked).
My contention is that this "mountain dwelling" is only possible at times, in some domains, in some organizations, etc. Humans can, at times, carve simplicity out of the swamp of complexity. But it isn't easy and it isn't a product of any fixed set of simple tools we human have come up with so-far.
Mr. Hickey's viewpoint might be useful for selling simplicity and I would be willing to use it if I thought simplicity would be a good buy for my organization. But the reality is tradeoffs never good away. Sometimes people overestimate the value of short term payoff but sometimes people overestimate the value of long term payoffs. The one thing that I think I want to keep here is the clear, simple distinction between "ease" and "simplicity". It's useful even if it might not be entirely, true.
There is a fundamental difference between the loop and the comprehension: the latter is far more declarative.That is, the comprehension is equivalent to saying something like "even contains every number from numbers that is even". The loop is like saying "start with even as the empty list; for each number in numbers, append it to even". It's much easier to understand what even is from the first description.
The for-loop version is much less direct and has too many low-level details--why are you appending to the list and using extra state? From the second definition, you can know what even is just by looking at it; for the first one, you have to think about what the code is doing.
This is the fundamental delineation between imperative and declarative code. The former is about how and the latter is about what. In general, specifying the what is much simpler--and therefore easier to write, easier to work with and easier to maintain--than specifying how to get it.
I suspect you find the for-loop version easier not because it's simpler but because that's what you're used to. And while familiarity is certainly an important factor, it's always relative and temporary: every person is familiar with different things, and you get more familiar with different constructs over time.
Rich Hickey's "Simple Made Easy"[1] talk is a great description of this whole idea. He makes the matter far clearer than I have any hope of doing.
⬐ Chris_NewtonThere is a fundamental difference between the loop and the comprehension: the latter is far more declarative.I completely agree with this, and the wider fundamental point throughout your post.
However, I’m not a fan of comprehension syntax. It often gets noisy even for trivial cases like this one: the letters “number” appear four times in just a single line here, which as it turns out is just as much accidental complexity as using the explicit loop control variable in the imperative version and you’ve lost the visual cues to what each means that the indentation gives with the loop. For more complicated transformations, I find comprehension syntax also scales poorly.
I suspect (though I’ve no hard data to back it up) that comprehension syntax actually isn’t very readable in many cases, and that this may be why some people prefer the kind of code in the imperative example rather than any innate preference for imperative style per se. Personally, I’d prefer to highlight the data flow but using more explicit transformations instead, such as (in a hypothetical functional programming syntax):
Python’s own syntax for this isn’t quite as neat as some functional programming languages, IMHO, but I still prefer it to the comprehension:evens = filter {_ % 2 == 0} numbersnumbers = [1, 2, 3, 4, 5, 6] evens = filter(lambda n: n % 2 == 0, numbers)⬐ thezilchTo be fair, we should be comparing like tokens, if the proof is using them as part of its advantage:withevens = filter(lambda n: n % 2 == 0, numbers)orevens = [n for n in numbers if n % 2 == 0]Choosing token names is certainly a differentevens = [n for n in numbers if not n % 2]⬐ Chris_NewtonFair comment. I suppose that’s why a more declarative style tends to work much better in a language designed for it. For example, functional programming languages tend to have neat syntactic sugar for things like simple lambda expressions or applying a series of transformations like the filter here, without introducing accidental complexity like extra identifiers that the reader than has to keep track of. The moment you’ve added that kind of baggage, which is almost inevitable to some degree in a language like Python, the clarity tends to suffer.
That's easier, not simpler. When part of the stack breaks you're even less likely to know how to fix it than 15 years ago.
⬐ nonamegivenThe procedure that I use is simple, regardless of the underlying complexity that makes it simple.Eating is simple, even though the body is complex. I'm glad I don't have to explicitly operate my pancreas.
Could be a coincidence, but I've been chanting that mantra at everyone who will listen after watching this talk by Rich Hickey:
⬐ kabdibNo coincidence, that's exactly where I got it. It's a great talk.I think that if it doesn't make you (a) depressed, then (b) mad, that you didn't listen carefully enough. :-)
There is a lot of stuff in Clojure that can be done in more than one way. I know that Python focuses on "only one way to do it", but Clojure's focus is on simplicity, as defined by Rich Hickey in Simple Made Easy [1], and that is a much better focus. I find that, as Rich says (and I'm paraphrasing), simplicity is by far the most important concern when programming. It dominates all other concerns in terms of importance and payoff. I believe I have become a much better programmer since I learned Clojure and listened to Rich's talks.
He's probably referring to the idea that much of the complexity around today is not particularly useful - in particular, that programming with values rather than variables makes understanding a program substantially easier.Simple Made Easy is a talk by Rich Hickey, the author of the Clojure programming language which encodes a lot of these ideas into the language.
http://www.infoq.com/presentations/Simple-Made-Easy
[EDIT: ambiguous comma :)]
http://www.infoq.com/presentations/Simple-Made-Easy
Rich Hickey made some very similar points in his Strange Loop presentation "Simple Made Easy" http://www.infoq.com/presentations/Simple-Made-Easy
Rich Hickey (Clojure) has a presentation about the differences between simple and easy. If you have the time, it's worth it.
I prefer the definition of simplicity proposed by Rich Hickey in Simple Made Easy: http://www.infoq.com/presentations/Simple-Made-EasyIt's a more concrete and historically accurate definition than the vague description supplied in the article.
Why do I think they are sliding towards Easy not Simple? Its a very fundamental distinction!http://www.infoq.com/presentations/Simple-Made-Easy <- Rich Hickey, creator of Clojure and Datomic
As ever, Simple Made Easy is apropos here: http://www.infoq.com/presentations/Simple-Made-Easy. It is well worth the hour, either watching it or downloading the MP3 and listening to it on your commute, jog, etc.One point the speaker, Rich Hickey, argues is that we have a bad habit of focusing too much on our experience sitting at our desks ("look how quickly I can do this one thing") at the expense of complexity in the code.
It's a short view as opposed to a long view, since over time your project inevitably becomes larger and more complex. When you're trying to add a feature to a large, possibly mature product, you're seldom doing the same kind of work you see for a framework or language's demo code. Complexity will dominate everything else, to the point where it probably won't matter as much how easy it is to change the color on a div or whatever.
That said, if you can isolate complexity behind an API (not just hide it, but truly abstract it), it's probably better for your software. The problem is that software only seems to get more complex over time, and after a while your framework which ostensibly abstracts adds its own complexity, complexity incidental to the problem at hand.
Anywasy, I sympathize. :) As I see it, programming as we know it tends to involve gluing together frameworks and APIs more often than it does writing raw code. It's a huge stack of abstractions and I wonder at what point it's futile to try to understand more than a certain subset.
That said, some people like being able to write code which ships almost instantly ~everywhere, or to a great many tiny computers in people's pockets. It's not all bad, right? It could be simpler, but it just isn't, so the decision is to take it or leave it. (Or try to replace it, but now you have two problems and/or N+1 frameworks.)
http://www.infoq.com/presentations/Simple-Made-Easy (this is so fundamental to this topic that it is required watching to even have an opinion on this subject)http://www.dustingetz.com/2011/05/05/how-to-become-an-expert...
http://www.dustingetz.com/2012/10/07/java-sucks-because-idio...
⬐ MatthewPhillipsYou don't have to convince me of OOP's faults; Clojure is my favorite language. But I write code for a living, mostly in OOP because that's where the jobs are, and I do not write very many bugs caused by OOP's poor design. I write bugs when the business is ill-defined, or when I misunderstand how a library's APIs are supposed to work, or when I'm careless and don't consider "what do I do if this function returns false"; all stuff that will come up in FP as likely as it will in OOP.
"Structure and Interpretation of Computer Programs" (SICP) by Abelson and Sussman is a must read.Some other foundational texts I'd recommend:
* "How to Solve It" is a (the?) classic introduction to mathematical problem solving. http://en.wikipedia.org/wiki/How_to_Solve_It
* CLRS ("Introduction to Algorithms") is the classic introduction to solving problems through computation: http://en.wikipedia.org/wiki/Introduction_to_Algorithms
Those texts are useful for "programming in the small." [1] As you get closer to "programming in the large" (basically putting together non-trivial software systems), some good things to look at are:
* The "Gang of Four" book ("Design Patterns: Elements of Reusable Object-Oriented Software") introduced the idea of design patterns to software engineering and provides a useful toolbox and vocabulary for thinking and talking about putting programs together.
* Joshua Bloch's "Effective Java" is an insightful set of heuristics on writing good code. Like with Gang of Four, you can get a lot out of this book by looking past the implementation language and thinking critically about the rationale behind the prescriptions in the book. I'd also recommend Bloch's talk, "How to Design a Good API and Why it Matters" (http://www.infoq.com/presentations/effective-api-design).
* A recent talk I found insightful is Rich Hickey's talk, "Simple Made Easy" (http://www.infoq.com/presentations/Simple-Made-Easy). In this talk, Hickey makes a strong argument for simplicity in software and the ramifications for the working programmer. I'd also recommend his talk, "Hammock Driven Development."
*I would highly recommend the "Destroy All Software" screencast series by Gary Bernhardt (https://www.destroyallsoftware.com/screencasts). These screencasts show an experienced developer working through small programming problems in a test driven style and explaining the reasoning behind his decisions as he goes along.
[1] http://en.wikipedia.org/wiki/Programming_in_the_large_and_pr...
⬐ physloopI just ordered "How to Solve It" and "SICP". They seem to be exactly what I'm looking for!The problem with CLRS is that I haven't had a discrete mathematics course yet, so the math involved in the book is way over my head right now.
Thank you for providing all those resources. I'll definitely make sure to check into the remaining books and lectures.
⬐ _piusGreat, I'm glad I could help!You raise a good point about discrete math, let me add the following to my list above:
* MIT's 6.042 ("Mathematics for Computer Science") Lecture Notes start at first principles and go on to cover relevant discrete math topics motivated by common types of computer science problems.
http://ocw.mit.edu/courses/electrical-engineering-and-comput...
All of Rich Hickey's talks great, but they're not really about learning how to learn. "Hammock Driven Development" is probably the closest, and is about approaching problem solving generally.Both "Simple made easy" and "Are we there yet" are pretty general, not necessarily Clojure-specific talks, although they do point to Clojure and more broadly FP as a possible solution to the problems presented.
http://blip.tv/clojure/hammock-driven-development-4475586
http://www.infoq.com/presentations/Simple-Made-Easy
http://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hic...
Also, I would say that Whitespace being "simpler" than Python is a fallacy, or at a minimum a reductive reading of the word "simple." I doubt the rules for writing in ASM, C, or whitespace are all that simple, despite the building blocks being relatively simple or few.Honestly, I'm just repeating variations on http://www.infoq.com/presentations/Simple-Made-Easy.
More notes on the video:- Rich's whole view on the world is pretty consistent with respect to this talk. If you know his view on immutability, values vs identity, transactions, and so forth, then you already have a pretty good idea about what kind of database Rich Hickey would build if Rich Hickey built a database (which, of course, he did!)
- The talk extends his "The Value of Values" keynote [1] with specific applicability to databases
- Further, there is an over-arching theme of "decomplecting" a database so that problems are simpler. This follows from his famous "Simple made easy" talk [2]
- His data product, Datomic, is what you get when you apply the philosophies of Clojure to a database
I've talked about this before, but I still think Datomic has a marketing problem. Whenever I think of it, I think "cool shit, big iron". Why don't I think about Datomic the same way I think about, say, "Mongodb". As in, "Hey, let me just download this real quick and play around with it!" I really think the folks at Datomic need to steal some marketing tricks from the NoSQL guys so we get more people writing hipster blog posts about it ;-)
An API is an interface, which in this case exposes data.Yes. The confusion comes from complecting[1] an object api and data. In general, having a class that is both a data structure (a bean or a struct) and a service class is a bad idea.
My contention is that if a class is Just Data, exposing public fields is fine. And if it is a service class that needs a consistent, stable API, it shouldn't be exposing fields via getters and setters either.
http://www.infoq.com/presentations/Simple-Made-Easy
This isn't meant as a slight to you, but I think that Clojure in general and Datomic specifically (as a newer product) isn't looking for the most customers. They're looking for the right ones that share their vision for programming.It still requires watching a video, but the video "Simple Made Easy" by Rich Hickey (http://www.infoq.com/presentations/Simple-Made-Easy/) describes it best. If that doesn't appeal to you, then don't worry about what you're missing in Datomic.
⬐ ScriptorActually, someone did a great job succinctly explaining it: http://news.ycombinator.com/item?id=4286701The attitude that Clojure is only for some enlightened few who are worthy enough to understand it is extremely alienating. Lisps aren't that hard, homoiconicity isn't that opaque, the benefits of using Clojure can be explained in practical terms that most developers can understand, if not at first be convinced by. All these concepts can be explained succinctly in text.
Saying that Clojure is only for those who share some 'vision' is hand-wavy at best, insulting at worst.
Edit: My guess is that Datomic is targeted towards Clojure devs because they are already experienced with Datomic's philosophy and will understand the system better. It also provides a smaller and highly receptive market. They can then focus on perfecting the software instead of training a large number of people in the philosophy behind Clojure and Datomic.
⬐ evolve2kAnyone here who knows the product want to have a go at proving a simple tag line, short about that would be suitable to use on their inbound marketing blog?⬐ pchristensenI didn't say that Clojure is for enlightened few or super hard to learn, I meant that Datomic/Clojure is currently targeted to people who already agree with Hickey and the other core developers. The 'vision' isn't some grand thing, just a strict adherence to simplicity and immutability as a way to improve program correctness.I think we're in violent agreement.
Rich Hickey has gone to great lengths to define simplicity and complexity (http://www.infoq.com/presentations/Simple-Made-Easy), and the paper "Out of the Tar Pit" (http://shaffner.us/cs/papers/tarpit.pdf) goes further.Software projects are becoming increasingly complex, and multicore concurrency is becoming increasingly important. Immutability and referential transparency are key ingredients in Clojure concurrency so I think the slogan is apt.
(I wrote all this then realized I've gotten off the point, this isn't really addressed at your comment. I recognize that the typical computer user couldn't give a damn about customizing their system and certainly wouldn't bother with setting up Arch, which makes it a poor gaming platform. I'm just tired of constantly hearing about how hard Arch is. It isn't hard, it just takes a bit of effort).I'd say Arch is pretty simple, just not easy [0]. Easy would be inserting the install cd, walking away, coming back and being able to hit the internet. Which is fine, if that's all you want to do. Arch installation isn't easy, it's simple, and more importantly it works. When I install windows from scratch you know what it comes with? Nothing. No drivers, no programs, nothing. Not even an ethernet driver for me to get the other drivers. Arch comes with all of it out of the box, you just need to go through the tutorial so you can choose which things in the box you actually want.
Arch is simple in that if I go to any scary looking file in /etc and open it up I won't be completely baffled by what's in it. I can randomly shut down any service running on my machine and I know my box will keep chugging and I can recover from it. There's no weird services that I don't know what they do, no scripts that run on startup that I can't understand let alone find. There aren't inter-dependencies that I don't know about. When I run ps aux I can account for every single thing running.
And even then, the package management is simple AND easy. I have never had a problem installing something with pacman, not once. There's this oft-repeated line about upgrades breaking systems, but I've never seen it. If an upgrade fails I look at the front page of archlinux.org and see that some manual commands are needed, copy-paste them and voila things work. I've used arch on three computers now, two laptops and a very old desktop, and have never had any problems. I know there's going to be some horror stories, but I can counter any of them with a quick search for the same in windows. Problems upgrading happen, but they're not common, and not something that's inherent to Arch like I've seen people suggest.
⬐ recursiveEvery time I've installed Windows, it's come with basic drivers and programs.⬐ eitland⬐ wickedchickenShort history lesson here then: Until recently installing Windows (except OEM) meant running driver CDs at least for stuff like network drivers (so you could connect to internet to download the updated drivers).⬐ jholmanShort history lesson: I have successfully gotten my Windows installs onto the internet without using driver CDs since at least Windows 98SE.I dunno what I'm doing that's so magical; I just install the dang thing.
⬐ danbeeThis totally depends on the network card chipset. A fresh Windows 7 install on my PC requires external NIC drivers before I get on the net.⬐ fcecconSame here, I installed Windows 7 on a PC with a fairly recent Asus MB and I had to install the drivers from the CD.I'm a systems developer, not a distro maintainer. When I boot off of that iso, I want a menu that asks me this:[ ] Desktop
[ ] Server
[ ] Embedded
[ ] Custom
This ultimately comes down to a user interface issue, but it's different than the kind of user interface often associated with the HN crowd. It's more like an API user interface, be that a web or programming library API. A crucial feature of good APIs is 'graceful degradation' in terms of easiness/control. Take a look at the libcURL library[1]. cURL has 3 levels of access: "easy," "share," and "multi." If you don't care about a lot of features and just want to download a webpage, the easy interface will get you what you want in a few lines of code. If you have something more complicated, you can go all the way down to the multi interface to access many of the raw functions of the API.
They key takeaway is giving the user control of her complexity level. If I'm a sysadmin compiling an image meant to be deployed on thousands of servers, then something like Arch would be pretty great -- I can fine-tune things how I want. If I'm just a random developer, then I would like to stick to 'sane defaults,' with the option to revisit those defaults later if needed.
I really don't care what cron I have, don't force me to pick one against my will.
I for one wish every working programmer would watch and understand this presentation.A link, for the lazy: http://www.infoq.com/presentations/Simple-Made-Easy
One problem with a state machine approach compared to MVC is that it isn't as familiar. Do you use a Moore or a Mealy machine? A combination of the two? Most people don't use state machines to model the flow of an entire web application, so if you try it out, you might feel like you're on your own.It can be worth it, though. I used state machines for a client-side UI in ClojureScript a few months ago. It forced me to think hard about the structure and flow of the app. But after that, my state was in an explicit, contained area. If I had been using something like Backbone, the state would have been hidden among the various model objects. I felt like I had a much better mental model of how the program worked after the initial design process. Keeping state in control reduces complexity. [1]
Another benefit was that the state machine library I used allowed me to audit the trail of states as they happened. When a user toggled a checkbox to trigger an event, I could look in the JS console and see the moment the checkbox was triggered. If something wasn't working, I could often debug it by seeing if the states and transitions happened in the right order. I wouldn't be able to do this with a traditional MVC framework.
There's one very important thing that nobody has mentioned yet: state machines look ugly in your code. When they get big, they are difficult to follow. I started out using a state machine library that was just too simple. Once the interactions became complex, I was getting lost in my code. I looked for a clearer, more succinct way of modeling state machines, and eventually I came to Harel statecharts. [2]
Statecharts are a way to model state machines without explicitly writing out a ton of redundant states. The number of states becomes a problem when you actually try to model an application with a basic non-deterministic FSM. If you're interested in using state machines in your web application, you need to read the linked paper. The example of modeling a digital watch with statecharts makes it easier to see how you could use them in a web app.
I believe statecharts are to MVC as Clojure is to every mutable state language out there. It feels weird at first, but once you get used to it, it's much simpler. It's just not necessarily easier. [3] If you want to try them out, there's a good library called Stativus for writing statecharts in JavaScript: https://github.com/etgryphon/stativus/
[1] See "Out of the Tarpit" for why state and complexity are closely related: https://dl.dropbox.com/u/249607/all/Out%20of%20the%20Tarpit.... (The original link is down, so I made a mirror.)
[2] The original article on statecharts: http://www.wisdom.weizmann.ac.il/~dharel/SCANNED.PAPERS/Stat...
[3] More about the idea that simpler things are not necessarily easier: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ jaaronThere have been a couple web services I've done which we've modeled as a state machine. I found the approach gave the architecture and API much more consistency, especially when paired with REST.⬐ antonio_cfc⬐ hesdeadjimIndeedAny mirrors on the document for [2]? Site seems to be down...⬐ Xurinos⬐ erichoceanarchive.org helped me find this link: http://web.archive.org/web/20110612045555/http://www.wisdom....⬐ radsHere's another mirror: https://dl.dropbox.com/u/249607/all/Statecharts.pdfI introduced statecharts to the SproutCore community in 2008, and there are a few really nice libraries that have grown out of that. Statecharts are now a standard part of SproutCore development, both at Apple and in the larger community.I also teach a course on how to combine MVC architecture with statecharts. It's pretty easy, but non-obvious, and once you learn how, you'll end up using statecharts for the rest of your life. No one goes back to the 'old' way of spreading application state among controller objects.
There are two different statechart implementations in Blossom: https://github.com/fohr/blossom
One is for the application logic, the other is for writing individual views (called "behaviors", but they're statecharts).
-----
Shameless plug for my 3.5 hour MVC+statecharts course: http://erichocean.com/training/app.html
Even though it's targeted at SproutCore devs, the concepts apply to any application MVC environment, e.g. Backbone, Qt, Cocoa, etc.
Simple versus easy [1]. Getting started with minimal friction is a great virtue for the beginning of a project's life, particularly when it allows amateurs to produce something of value. Software development professionals with stronger requirements (reliability, maintainability, ease of code reading) are not always going to reach for the easiest tool. There's a reason most of the software on your machine isn't written in Visual Basic.The people who prefer PHP are right. The people who avoid PHP are also right. They are solving fundamentally different problems.
⬐ ghotliThis was worth watching again so I'm glad it was reposted and brought back to my attention. I was as struck by it this time as when I was sitting in the room listening to him last year.What I would like to see, or create if I have to, is a condensed version of this argument that is meant for the non-programmers, the managers, and the c-level employees of a business. The underlying premise of believing in and executing with simplicity is one that nearly requires air support, and buy-in.
I think in his summary at the end there are a few key statements he makes:
"The bottom line is that simplicity is a choice. It's your fault if you don't have a simple system.... it requires constant vigilance... You have to start developing sensibilities about entanglement... You have to have entanglement radar... You have to start seeing the interconnections between things that could be independent."
⬐ _shIf, like me, you're overwhelmed with complexity in software projects, you need 'Out Of The Tar Pit'[1]. This essay is so good, I've read it four times, gaining new insights every time.⬐ ab9⬐ gruseomThanks. I really enjoy what I've read so far.⬐ brown9-2Ugh, somehow in the 3 days since you've posted this the URL just returns a default "MobileMe is closed" page.⬐ _sh⬐ nathansoboThere's this: http://shaffner.us/cs/papers/tarpit.pdfCool to read this. I've actually built a library in CoffeeScript that enables a lot of the "relational programming" ideas expressed in this paper.I like most of the points he makes but that "complect" business is fingers-on-a-chalkboard pretentious to my ears. "Coupling" and "complexity" are perfectly good words and have been used for decades to talk about this stuff.But the stuff about how simplicity and easiness are not the same (at least in the short run) is very good.
⬐ repsilat⬐ skardan"Coupling" and "complexity" are nouns, "complect" is a verb. Complect is to complex as complicate is to complicated - It means "complexify" for those who prefer archaisms to neologisms.⬐ heretohelp⬐ chousukehttp://www.thefreedictionary.com/complicatetr. & intr.v. com·pli·cat·ed, com·pli·cat·ing, com·pli·cates
1. To make or become complex or perplexing.
2. To twist or become twisted together.
* ---> To make or become complex <--- *
Why did we need this complect business again?
⬐ repsilat⬐ gruseomI thought it was pretty clear - he used "complect" because it shared an etymological root with "complex". The whole talk is about drawing distinctions between superficially related concepts, and using specific definitions based on words' etymological histories to do it.The word "complicated" is generally synonymous with the word "complex", but that doesn't matter - the word "simple" is generally synonymous with the word "easy", after all. If Rich Hickey had said "complicate" viewers may well have asked whether he meant "to make complex" or "to make complicated", and perhaps wonder whether he was trying to draw a distinction between those concepts as well.
"Couple" is of course a verb. There are other words people have long used for this too. There's no need for obscure new jargon, and it's ironic that a talk about simplicity would introduce any. It gives the wrong impression, because these concepts are neither new nor difficult. What's difficult is building systems that respect them.⬐ richhickey"Coupling" has always been a particularly weak word for the software problems to which it's been applied, IMO. After all, when you connect 2 Legos together you couple them."Complicate" was a candidate, but is decidedly unsatisfying. It just means "make complex", saying nothing more about how; nor about what it means to be complex. For many people, simply adding more stuff is to "complicate", and that was another presumption I wanted to get away from. There is also some intention in "complicate", as in, "to mess with something", vs the insidious complexity that arises from our software knitting.
I wanted to get at the notion of folding/braiding directly, but saying "you braided the software, dammit!" doesn't quite work :)
⬐ gruseomAs far as how we use these words in software goes, I think "coupling" is just fine. To me it means exactly what we're talking about: making things depend on each other. "When you connect 2 Legos together you couple them" sounds off to me. I'd say that's just what you don't do. Rather, you compose them. Composition to me means putting together things that have no intrinsic dependency and are just as easy to separate again.Reasonable people can obviously have different associations, but I thought "coupling" and "decoupling" were pretty standard terms in software. You know, "low coupling high cohesion" and all that.
What about when we simplify a design by removing dependencies between things? Surely we're not going to say we've "decomplected" them?
It goes without saying that we agree on the more important point, which is that whatever we call that thing we do to software where we make everything depend on everything, we fuck it up :)
⬐ richhickey> Surely we're not going to say we've "decomplected" them?Simplified.
⬐ gruseomBut that has the same problem you mentioned about "complicate". It just means "make simple", saying nothing more about how, nor about what it means to be simple. Not all simplification is disentangling.I like the appropriation of an archaic word for this use. The point is to make you think about something familiar in a manner that is unfamiliar to most.The word is now strongly connected to the concepts of easy and simple which Rich tries to untangle. From now on, when you hear someone tell you that you have "complected" something, it will most likely cause you to remember the talk and sort of forces you to think.
Just hearing talk about "coupling" might not trigger such a reaction.
I also recommend Rich's talk called hammock-driven developmenthttp://blip.tv/clojure/hammock-driven-development-4475586
http://www.popscreen.com/v/5WwVV/Hammockdriven-Development
or his recent talks about reducers or Datomic.
For me the talk about reducers was especially jaw-dropping experience because it was about something simple we all do every day - crunching data in collections (how many times you have implemented lists library? :). Yet after decades of collection traversing, there is a still a place for fresh approach, if you are willing to thing hard.
This is the difference between blindly following known programming patterns (cargo-cult programming I would say) and really thinking about a design.
⬐ BadassFractalBeen really impressed by the man, the language and the philosophy ever since I saw the video. Clojure has been a challenging and yet eye-opening experience, and I plan to continue learning it and using it in as many projects as I can from now on.⬐ gamzerTip: If the video and the slides don't fit on your widescreen display, shrink your browser window horizontally.⬐ akkartik⬐ spacemanakiOr click on 'horizontal' and then on 'fullscreen'.⬐ vdmAnd then click 'X' to close the meaningless countdown timer early.If you haven't seen it, Stuart Halloway's "Simplicity Ain't Easy" is a more Clojure-specific talk that's a nice complement to this one. It has some more concrete examples pulled from Clojure.http://blip.tv/clojure/stuart-halloway-simplicity-ain-t-easy...
⬐ jgrodziskiI'm glad Rich and its presentation gets the popularity they deserve. I attended to that one at QCon London in March and it was the presentation that struck me the most.Rich gave also another presentation about the modeling process that I find great (slides from Goto Con) : gotocon.com/dl/jaoo-aarhus-2010/slides/RichHickey_ModelingProcess.pdf
⬐ jamesaguilarIf someone wants to do a talk about how to get as close to this as possible in a language like C++, I would watch it.⬐ dan00⬐ dan00The issue with languages like C++ is, that you can follow better programming practices, but the compiler doesn't support you in the verification and accordingly you can't trust that easily your code, which complicates the reasoning about a system a lot.Having properties like immutability and pureness in your language makes it lot easier to trust your code and to reason about it.
⬐ nivertechErlang:C++:X = 5. X2 = X+1.My C++ style use const modifiers extensively. Likewise you can use final in Java.const int x = 5; const int x2 = x + 1.⬐ dan00⬐ bad_userconst_cast and mutable, and gone is any kind of verification.⬐ NoneNone⬐ saurikThat your code uses neither is trivially verified with grep. Are you saying your issues would be solved if someone added a ten-line patch to gcc for -Wconst-cast (that provided a waning, obiously upgradable to an error, if you used const_cast; as in, similar to -Wold-style-cast)?⬐ dan00You really can't express immutability and pureness in C++, because you can still modify global variables and do any kind of IO everywhere, regardless of const.const_cast isn't the big issue, because there's also unsafePerformIO in Haskell. For both you could say, that they shouldn't be used, that it's bad programming practice to use them.
The point is, even if you follow good programming practices in C++, you can't express them and your compiler can't help you in the verification, if you're really following them.
That doesn't might seem like a big thing, it's also not related to your smartness, because it mostly depends on the size and complexity of your system.
⬐ saurikIf you are arguing that you don't have immutability by default across all values, that is a very different point that I think you need to provide more clarity for... I mean, of course you can modify state that has nothing to do with the variables that are marked const "regardless of const": that is sufficiently obvious as to be a useless comment. However, you really can mark values as const in C++ and allow the compiler to verify that you aren't doing anything non-epic to defeat it. Yes: you can still accidentally or purposefully access the memory via a random hand-calculated pointer, but we can actually harden the compiler (not the language: no changes there required) against that as well by just keeping you from using pointer arithmetic (really, that's a feature that tends to only be used in restricted contexts anyway).Clojure doesn't give you immutability guarantees, it just makes it harder to chose otherwise, but on the other hand calling a Java method on some object is just one special form away. I'm not saying Clojure does the wrong thing here btw, but this thing you're talking about is a fallacy, unless you're working in Haskell and even there you could find ways to screw things up by interacting with the outside world, which isn't immutable.⬐ dan00"I'm not saying Clojure does the wrong thing here btw, but this thing you're talking about is a fallacy ..."Please, read exactly.
"... unless you're working in Haskell and even there you could find ways to screw things up by interacting with the outside world, which isn't immutable."
The whole point is, that you're able to express immutability and pureness in a language like Haskell _AND_ have a compiler which can verify it.
You will never be able to prohibit any screwing, but you can make it a lot harder to screw something.
In a way dynamic typing is easy and static typing a la Haskell is pretty hard.A good type system allows you to reason more easily about your system and checks if you're violating the rules of the system.
Looking at static typing and only see inheritance and the increased complexity, is only looking at static typing a la C++/Java.
⬐ abpHas anyone seen this recording and the newer one [1]?Is one of them better in any form?
http://www.infoq.com/presentations/Simple-Made-Easy-QCon-Lon...
⬐ endlessvoid94I get something new out of this every time I watch it.⬐ mattdeboardNormally I am opposed to chronic reposting but I have watched this video start to finish 5+ times and it has never been time wasted. It is an eloquent expression of a philosophy that has shaped how I approach problem-solving more than any other. If you've never watched it, you're doing yourself (and those who depend on your ability to efficiently and effectively solve problems) a disservice.⬐ kjbekkelundI'm also opposed to reposting, but I mention this talk to people all the time and nearly none have seen it. Those who have, however, all agree that it is an amazing (and eye-opening) talk. I just saw it again today for the first time in half a year and realized how much it has actually changed how I develop software.⬐ kylebrownI watched this a few months ago but don't remember much other than simple != easy. I thought I had taken notes, but turned out I had it confused with a Dan Ingalls talk on OO from 1989 I watched around the same time (which I found interesting enough to take notes).Reading the comments on the infoQ page jogged my memory a bit. I remember thinking that his concept of "complect" was the same as "connascence" - a term I learned from a Jim Weirich talk [1]. Minimizing complectity/connascence (variables shared between modules) is good.
Is there something more striking (and summarizable) I should have remembered?
1. http://www.bestechvideos.com/2009/03/29/mountainwest-rubycon...
⬐ EstragonThe simple vs easy concept is broader than data sharing. One example is perl, which is quite easy to pick up but complects many things, like strings representing numbers being silently coerced into numeric values.Another example, where I immediately thought of simple/easy as it came up: I realized the other day that a component of an app I've been designing serves two almost independent purposes, and I can drastically simplify the design by making separate components.
The video you linked doesn't seem to be available anymore. The slides are available on scribd, but they don't seem to make much sense without the context of the talk.
⬐ kylebrown⬐ mattdeboardThanks. This one is working: http://confreaks.com/videos/77-mwrc2009-the-building-blocks-...He mentions that back in the 70s he was writing Fortran for NASA and his mentor recommended he read a book called Composite/Structured Design. "Structured Design" was the big thing back then and the controversy was using if-else and while loops instead of Gotos. Nobody was worried about strongly vs weakly typed langauges (perl!).. Key chapter in that book is on Coupling and Cohesion.
Junp to the late 90s for his second book recommendation: "What Every Programmer Should Know About Object-Oriented Design", really just the third part of the book which introduces "connascence". Two pieces of software share connascence when a change in one requires a corresponding change in the other.
I love the historical angles on this stuff.
Sure I guess those terms are about the same. Not going to spend any time summarizing it for you though :) There are plenty of blog posts that do so already.⬐ kjbekkelundBasically, it gave me a new vocabulary for thinking about the decisions I make every day when coding. It opened my eyes about things to look for, to focus on, to change, and so on. With regards to decisions, I also love Dan North's Decisions, Decions from NDC recently: https://vimeo.com/43536417It's mainly the basic philosophy that Hickey focuses on that changed a lot for me, not any of the specific examples. After watching Hickey I've read great books such as Pragmatic Programmer, Passionate Programmer, Coders at Work, and other books that have helped me, as a recent university graduate, build my "coding philosophy". Hickey was just a very inspiring "first step" in changing how I look at code.
Rich is so spot-on. Here's a variant of that talk: http://www.infoq.com/presentations/Simple-Made-EasyAnd funnily enough I had the itch to say I'm a primitive obsessive today: http://williamedwardscoder.tumblr.com/post/25916255470/taxon...
It almost feels like a reply to this post, but it was an coincidental bit of pontification.
Monolithic frameworks complect things -- see Rich Hickey's talk "Simple Made Easy" (http://www.infoq.com/presentations/Simple-Made-Easy).Monoliths also lock you into a certain paradigm. Django locks you into a RDBMS if you want to hook into all of Django's components like auth, admin, etc. And being locked into a paradigm limits the types of problems you can solve and makes it difficult to shift when a new paradigm emerges.
We're in a period of rapid development in datastore technology. If you're locked into a relational database, it makes it difficult to switch and take advantage of these developments. Loosely coupled components like Flask follow in the Unix tradition and free you from these bounds.
Django was well positioned 10 years ago when the RDBMS ruled, but with the proliferation of new DBs and data storage services, it's not well aligned with modern architectures.
⬐ cheatercheaterSo yeah, let's use VertexDB for auth....are you out of your mind?
⬐ espeedEvidently you may be trapped inside yours -- I made no mention of VertexDB nor did I suggest any particular database.However, for example, Datomic (http://www.infoq.com/presentations/The-Design-of-Datomic) is interesting, which is distributed and uses Amazon's DynamoDB storage service.
⬐ cheatercheaterI'm yet to see a Django based website that outgrows any old rdbms for auth. Care to back up your claim that it's bad? Same for admin. You do realize that Django's admin is just a search result of objects defined in its ORM, and that objects defined in its ORM are very obviously stored in an rdb - right? What would you like admin to use for managing data stored in an rdb? There's barely anything other than the models being managed that touches the database.Edit: just before my comment gets skewed, my question is: why would you ever use django for a website big enough to warrant this sort of worry? Let's recap: big websites make money which is used to hire coders. Those people are at that point probably porting your website to Agda, or some other cloudscale technology. Sounds like you're the same kind of person who complains that Bash doesn't support OpenMPI and that JavaScript doesn't do fib() well enough and that this here carpentry hammer can't break diamond. Wrong application, dude. Django is for medium-small websites, not for your Cloneddit, Clonebook, CloneSpace, or news.yclonebinator.com; get a different hammer.
⬐ espeedIt looks like you're new here. Make sure you understand the context before you go trolling else you might be mistaken for a chatterbot with all the non sequiturs.⬐ cheatercheaterI'm not new to Django or programming in general, though. Making generic statements like your original post and catering to hip trends is one thing, backing up your bs is another. Obviously you can't answer the direct and very simple questions I stated, so you resort to pointing out your paltry 3.79 karma average in an attempt to sage me. Nice.⬐ espeed⬐ NoneMy comment was about simplicity and paradigms, with allusions to Thomas Khun's The Structure of Scientific Revolutions (http://en.wikipedia.org/wiki/The_Structure_of_Scientific_Rev...). You must have missed that because you're trying to pick a fight about scalability, which has nothing to do with my original comment.Most of my work is with graphs so, for example, if you want to use a graph database to build a social graph with a Bayesian network, you wouldn't use most of Django's components such as auth and admin because they're tied to the ORM -- most of Django would just get in your way. It has nothing to with a Django-based site "outgrowing" auth.
Try to break out of your relational mindset and understand the thread before you decide to go off. And regarding my "paltry 3.79 karma average," you do realize the median for the leaderboard (http://news.ycombinator.com/leaders) is 3.975, right? Again, know what you're talking about.
⬐ cheatercheaterGiven a very specific need of working with a bayesian network based on a social graph, i can see how your point was almost-valid. However, there's no mention of this sort of thing in your top post. The original link is about breaking up web apps into services, a'la amazon. I think it is you who does not understand the topic at hand, but that's a fairly trite way of argumentation, so let's just say that you didn't mention your very specific needs which were needed to appreciate just why not using an SQL db for auth is simpler. The fact is that it's probably not, it's just that it fits your solution better, so the total expense is lower. Having auth or admin backed by an rdb is not more expensive, auth supporting your idea or admin supporting your idea which are two executions of the concept that are very unusual compared to what is normally done with Django. Again, you're complaining your hammer can't be used to screw in things. Get the right tool, or if it doesn't exist make it. Django is not the right tool. So the whole thing is a composition of "why didn't you say so" and barking up the wrong tree.Of course, the lack of actual motivation in your top post can be explained through being inarticulate as in the paragraph above; it can also be explained by you trying to mesh together a few easy and hip claims. The later motivation could well be something you worked hard to muster up only after initial critique, and given that its connection to the top post hinged on a shaky premise I think that's what has happened here.
Regarding your "paltry 3.79 karma average", the leaderboard is sorted by karma amount, not karma average. There are people on that list who have about 10x as much karma average as you do. And even the guy with the least karma on that list still has over 4x as much karma as you do. Well done computing the median of a biased subset of people. Biased because it selects people with the largest amount of points which easily comes at the expense of post quality. Please read about the bias of controlled, not-randomized studies before you go throwing around statistics you can't interpret. I suggest looking at the tree graph found on page 7 of "Statistics" by Freedman, Pisani, Purves, since you like graphs so much. Coming up with meaningless numbers will only shut up someone troubled by innumeracy, and I am not affected.
⬐ espeedDamian, I think I see the disconnect here.The OP/thread is part of an ongoing conversation about the Python community at large and Django's stronghold on the community mindshare because a large portion of development resources goes toward the Django platform rather than to decoupled, external libraries (as noted in the talk).
Most new Python Web developers choose Django as the default option because that's where the mindshare is (hence the repeated "we'll use Django, of course" in the slides), and Django's design and momentum lock the Python community into a certain paradigm, even though new paradigms are emerging.
Kenneth's talk, my comments, and similar comments by people like Mike Bayer (http://news.ycombinator.com/item?id=4079892) were about breaking that stronghold. My example regarding graphs was just an example for you, but my original comment was about the bigger picture.
BTW you were the one throwing around karma average. Have you looked at yours, and are you aware how it's calculated? -- it's not really a good indicator to use when trying to discredit someone.
⬐ cheatercheaterAt first you have tried argumenting with completely unrelated facts, then tried ad-hominem, then you have tried and failed at coming up with a speculative interpretation of your own original post in a failed attempt to pretend those were your motives. Finally, in a last-ditch attempt, you have strongly detracted from your top post.> The OP/thread is part of an ongoing conversation about the Python community at large and Django's stronghold on the community mindshare
No, it's not. The highest rated top posts for this link talk about complex monolithic code vs flexible code made out of bits which is however lacking in features. This includes the post you're trying to defend using this detraction strategy. The question of Django having or not having mindshare in the python community is secondary to this, and isn't even a topic of the largest minority of comments I've seen on this link.
To support your claim that it's all about community you come up with a short post that is several levels deep, and purport that the original talk bemoans the fact that Django is domineering the community. The talk barely mentions that Django is just a popular choice, it is your completely disconnected analysis that he was complaining about Django's harvesting of the "python mindshare". In fact it mentions Django because according to the talker it's just the top competitor to what he's selling. This is standard course of action when you're presenting a new contender in a space and has nothing to do with "the state of the python community".
In the same way as you try to paint over the past repeatedly changing what you've meant with the original post, you do the same with the side discussion of karma. If it were really as unimportant as you say, why were you defending it in a post just above? You lack consistency.
Yes, I have looked at my karma average. The same page that displays it will also show you that I barely, if ever, post here, and if you try harder you will find out that I've registered about a year ago to post on my own content after it submitted here. This should in fact display to you that this website is not as important to me as you think it is. It's not that I'm new here - it's just that I'm not, you know, "a part of it". However, your comment was just so disconnected from the discussion, I felt compelled to point it out, and I'm glad I did so, because the resulting trainwreck should give you, and other people here, some fodder for thought - not everyone buys your junk logic. You can see it as a pedestrian bystander jumping in to rescue people from a car crash. Not a member of emergency services per se, but the situation warrants action strongly enough that some bystander felt the need to do something.
Threatening people with your amount of experience, jumping around in the supposed meaning of your point, ad hominem (oh, now my comment means this.. no, it means that and you don't get it because i'm so much better than you.. oh, no, it means something else; oh btw, I've been stalking you, watch out!) don't really form a way to have creative and intellectual discourse with anyone. Glad to stomp that out for you, you may thank me later once you've become accustomed to actually admitting when you had made an error, rather than feeling the need to spin it, pretending it's something else.
In my mind, when I made the original comment to your top post, the fallout looked like this:
(original premise): you say that it's very bad that you have to use an rdb for admin
(baiting answer): yeah, so let's just use (nosql database chosen as an especially ridiculous example)
(your answer): you would need to use a nosql database for admin to do (fringe application)
(my answer): but (fringe application) is not what Django was made for. Wrong tool.
(your answer): ok, here's a better illustration. We truly do need Django to be able to do (some thing which is tied to an rdb), but it's much better done if it were in its stead using (some nosql technology).
This workflow has happened (except for the last part), but it came with a lot of bickering and manipulative speculation, which makes me think that you hadn't even noticed it, much like someone who after getting a speeding ticket attributes it to police depravity and oppression of the common man. Therefore, I decided to point it out. Is it really so difficult to admit when you've shot off on a tangent? I liked the link in your top post, quite a lot in fact, but the comment that followed it was of no or negative value because you have chosen to illustrate with non-examples: concepts that do not support your claim. In addition you did this because you really really like nosql databases and probably feel the need to bash on everything that uses SQL from the angle of it using SQL, and sometimes can't control this need. In this way your nature has really messed up the execution of your intentions. I'd have totally upvoted you had you just made a link and no comment, and probably defended the link adamantly from anyone criticizing it. I'd have loved it even more had you accepted that maybe what you thought wasn't entirely correct. But neither of those two things happened. Instead, you bicker and manipulate, finally resorting to trolling through stalking, hoping that you'll find out my name (it's not Rumpelstiltskin) and somehow shock me or make it more personal. And even worse, you fail at stalking, but while doing that show yourself as a big jerk. And I'm not saying I wasn't being negative, but I'm trying to keep form, whereas you display somewhat of a sleazy, vaguely adversarial, win at all costs quality in your discourse, which shows lacks of consistency. Consistency is the most important thing when conveying information, and without it you end up being viewed as a charlatan. Think about it.
⬐ espeedHere's the problem -- you fixated on this:(original premise): you say that it's very bad that you have to use an rdb for admin
...but it's not what I said; this is what I said...
"Django locks you into a RDBMS if you want to hook into all of Django's components like auth, admin, etc"
I'm not saying that it's bad that you have to use a relational database for auth, I'm saying that if you don't use a relational database and the ORM then you lose admin, auth, third-party apps, etc. Strip all of that out and what do you have left? See slide 71 (https://speakerdeck.com/u/kennethreitz/p/flasky-goodness).
And I have said this several times before (http://news.ycombinator.com/item?id=2911275), so no, I am not trying to retrofit my argument.
The talk barely mentions that Django is just a popular choice, it is your completely disconnected analysis that he was complaining about Django's harvesting of the "python mindshare".
If you don't think that's at least the subtext of what the presentation was about, look at the slide for Kenneth's primary thesis: "Open Source Everything" (slide 10 - https://speakerdeck.com/u/kennethreitz/p/flasky-goodness). And then go through the presentation again to see what he means -- "Single Code Bases Are Evil" (slide 45).
⬐ cheatercheaterThe slide just says "open source everything". How you conceived that this in turn means "django has ingested the python community" is beyond me. Probably the same mental flaw that makes you a stalker. Why should I be replying to a stalker again?BTW, did I mention: "stalker"?
⬐ NoneNoneNone
There is a great presentation [1] by Rich Hickey about simplicity. He makes a point in keeping the words "simple" and "easy" semantically separate. This post is a wonderful example why that makes lots of sense. None of these examples really show anything that's decidedly simple. They're all about ease of use and backward compatibility (which is a particular case of ease of use).It seems like "easy" can be further subdivided into several useful and objective categories. Clearly, libpng was only concerned with some aspects of "easy" (portability) and not others.
Also, I absolutely hate the kind of fatalism you often see in SE articles. "Oh, gosh, nothing is really simple, nothing really is bug-free, nothing is really good, so you shouldn't even try."
Awesome for the linked talk alonehttp://www.infoq.com/presentations/Simple-Made-Easy
If you haven't seen this just take time to watch the first 15 minutes. Really worth it.
the whole driving force of Clojure and Scala, the thing they were designed for[1], is large, enterprise-class codebases, because functional programming makes it easier to reason about program behavior at scale.[1] http://www.infoq.com/presentations/Simple-Made-Easy (required watching for someone interested in having an opinion on this subject)
you're still saying an awful lot of unsubstantiated opinions. its not about politics, its just about being objectively wrong. frankly, I and it seems also others, just think you're less informed than you think you are. sorry about the super blunt tone, not sure how else to say this. edit: it's good that you're commenting though, these discussions are healthy.
An interesting assertion in Rich Hickey's Simple Made Easy talk is that simple and complex are almost objective qualities, at least when you accept the definitions he puts forth (simple: one fold/braid with no interleaving). I think he's right, but I'm not sure I agree entirely, only because I haven't spent enough time thinking about it and trying to apply the ideas to real world problems. I do think that most programmers can call out complexity without a lot of disagreement. What you describe regarding fold vs for-loops touches on his definition of easy, that is to say "close at hand". Fold is easy for a functional programmer, for-loops for a Python programmer. Their simpleness might be a different matter.
Deploying a PHP app is as easy as using FTP, deploying a Python app can be -- but doesn't have to be -- complex.Easy != Simple && Easy != Good
See "Simple Made Easy" (http://www.infoq.com/presentations/Simple-Made-Easy).
Clojure is a functional Lisp with immutable, persistent data structures. This simplifies concurrency programming, which is becoming increasingly important in a multi-core world.For the "Why?" of Clojure, see Rich Hickey's talk, "Simple Made Easy" (http://www.infoq.com/presentations/Simple-Made-Easy).
As for the downvotes, content-free comments are typically downvoted. Also realize this site is written in a Lisp (http://arclanguage.org) created by Paul Graham (http://paulgraham.com/arc.html).
Rich better illuminates these concepts in his "Simple Made Easy" talk (http://www.infoq.com/presentations/Simple-Made-Easy) at the Strange Loop conference, where he doesn't pull any OO punches.
⬐ JasberHas anyone watched both? Are they significantly different?⬐ bitops⬐ SkyMarshalThey are very different - one is geared towards more of an FP audience, the other targets the crowd at RailsConf.Thanks, was going to ask if this is worth watching if I've already watched his Strange Loop talk.⬐ bitopsI know that not everyone agrees with Rich, but I do think everyone who writes software professionally could benefit from watching this talk.⬐ frou_dhAnd this one (2009):http://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hic...
Sure it’s simpler: they’re used in two separate layers – each with its own purpose – which are consumed by separate components (and actually more, because when you send this down you’re of course wrapping it in HTTP and TCP &c.). For a better understanding of why this kind of design is simpler, and therefore better, I recommend Rich Hickey’s talk: http://www.infoq.com/presentations/Simple-Made-EasyEdit inre “more complex compound data exchange format”: No, the point is that this should be thought of as two simple protocols wrapped one inside the other, not one “complex” format. Watch Rich Hickey’s talk. It would be a complex format if the two layers reached across into each-other, if the consumption of one depended on the details of the other, etc. But if they’re kept properly separate, that’s not complex – by Hickey’s definition anyhow, and I think it’s an excellent definition.
⬐ olavkAgreed, the overall architecture may become simpler by choosing a more complex compound data exchange format.
Here are some links:http://www.infoq.com/presentations/Simple-Made-Easy
http://www.youtube.com/playlist?list=PL4BFC3F13B846707B
http://books.google.com/books/about/Mindstorms.html?id=HhIEA...
Part 4 primarily of:
http://www.amazon.com/The-Design-Essays-Computer-Scientist/d...
⬐ vdms/ http://t.co/cJgpnX5B / http://tele-task.de/archive/video/flash/14029/ /
I'm glad simplicity is taken into consideration early on, because simple is not easy[1] to achieve when language goes into production.
I'm using Rich Hickey's definition: http://www.infoq.com/presentations/Simple-Made-EasyYou might be using it to mean what he's defined as "easy".
Noooo the real problem with scrum is said by Rich Hickey is this talk:http://www.infoq.com/presentations/Simple-Made-Easy
(Especially 17:50 in, where he jokes at scrum, but do watch the whole thing its great)
Hard is OK. Over time, you become better at it, until it's no longer a problem -- it's a relative thing. Not saying easy is bad, but hard isn't _that_ big of a problem.Example: I find Russian very hard to speak. That doesn't mean Russian IS hard, I just don't know russian. And some languages are harder (more stuff to learn) than others.
John D Cook has a lot to say about this: [1]"One of the marks of a professional programmer is knowing how to organize software so that the complexity remains manageable as the size increases. Even among professionals there are large differences in ability. The programmers who can effectively manage 100,000-line projects are in a different league than those who can manage 10,000-line projects. ... Writing large buggy programs is hard. ... Writing large correct programs is much harder."
Jeff Atwood's metrics will help you filter out engineers whose complexity ceiling is <1k lines -- StackOverflow answers, whoopee -- but that's not a terribly hard thing to interview for. Much harder to interview for the very best, the mythical 10x productivity programmers[2], those who can handle 100k LOC, 1M, or more. Perhaps this is the difference between an experienced non-expert and a real expert[3].
In my experience not a lot of employers care about this, perhaps because their challenges aren't those of complexity-in-scale, or perhaps because complexity hasn't bit them hard enough yet, or perhaps because they are "unconsciously incompetent"[4]. About the only hiring signal I've identified for this is interest in functional programming -- languages like Clojure and Scala exist precisely to raise the ceiling of complexity a human can handle[6] -- and as such I'm trying to learn this stuff and trying to find people via the community who care to hire engineers with these skills. Unfortunately my own bias may be blinding me, you never know which side of Dunning-Kruger[5] you're on until it's too late.
If you care about these things: I'd love to know who you are and what you're working on, email me.
[1] http://www.johndcook.com/blog/2008/09/19/writes-large-correc... [2] I am not one of these, but I strive to be one someday. [3] http://www.dustingetz.com/how-to-become-an-expert-swegr [4] http://en.wikipedia.org/wiki/Four_stages_of_competence [5] http://en.wikipedia.org/wiki/Dunning%E2%80%93Kruger_effect [6] Clojure creator Rich Hickey talking about complexity: http://www.infoq.com/presentations/Simple-Made-Easy
edit: man, this got 2 downvotes in 2 minutes, cmon guys i put a lot of thought into this!
⬐ jacquesm> man, this got 2 downvotes in 2 minutes, cmon guys i put a lot of thought into this!That really sucks because there is some very good stuff in here.
One thing that I find strange is to assume that those that are really good at this would have the time to maintain a stackoverflow profile. Likely they're too busy raking in the $. On the other hand start-ups likely can't afford those guys anyway.
Until they drown in a 150K loc tangle that makes spaghetti look structured.
⬐ kamaal>>Much harder to interview for the very best, the mythical 10x productivity programmers[2], those who can handle 100k LOC, 1M, or more. Perhaps this is the difference between an experienced non-expert and a real expert[3].Only that the 10x productive programmer deosn't quite really have time in his day job to memorize and master arcane facts and puzzles.
And since it turns out the big Web brands are all about this facts and puzzles in their initial rounds. This means they are missing out on nearly all 10x productive programmers.
⬐ dustingetz⬐ int3well, you have to figure that the true 10x programmers are probably smart enough to figure out how to attract and close other 10x programmers. so either a) the puzzle-people aren't 10x programmers so who cares, or b) they are, and we don't understand their process because their process isn't designed to find us. i mean, i tend to go with (a), just sayin.Jane Street Capital (world-class FP shop) is famous for two things: a) having a ridiculously hard interview, and b) hiring the best of the best. their interviews are blogged all over google. they ask everything from "three bags - apples, oranges, mixed; all mislabeled; how many guesses do you need to label them properly" to "implement a perl-style regular expression parser. on the whiteboard. in 45 minutes."[1]
i'm not sayin' i dig the puzzles, but I've read a few of their whitepapers, they are definitely better engineers than I am. and if i ever decide to interview again (once upon a time i insta flunked a phone interview), you can bet i will be a godly puzzle master. no matter the outcome, i bet i learn something about why they ask the questions they do.
[1] https://www.quantnet.com/forum/threads/detailed-in-person-ja...
⬐ botjOn another note, the work environment is a crowded open space with people constantly yelling to each other. They advertise a 50 hour work week with no lunch break. My impression is that your base salary is just over $100k, without any indication of bonuses for software engineers.If (emphasis on if) that is true, the only reason I can see people going there is a false sense of elitism.
⬐ kamaalWell I am sure they are.But so far the best people in the industry I have seen so far have no time for puzzles and facts. They have better things to do and build. And they are busy enough and generally have enough of the actual work, to keep themselves busy enough to be adding meaningful value.
I now follow the same principle. I've cut down on my social network interactions. Once a day email communication. No more fact hunting. No more evaluation of every single open source software that gets released. No more worrying about language wars. No more text book reading etc.
I plan my actual work in a GTD model. I execute in pomodoro style. All aligned towards getting work done and keeping me busy and productive all day.
I have received amazing results. I've developed new hobbies like music. I spend meaningful time on things like meditation and exercise in whatever spare time remains.
I am for sure not going back to any puzzle and algorithm shopping any more. My experience reveals provided I can remain a order of magnitude more productive then others everything else will get automatically get taken care of.
I'm very interested in this topic too. Aside from functional programming, I think examining how existing systems were designed is another good way to improve. I'm taking a class[1] where we read a bunch of classic papers on systems design, and I think it's been helpful. I just did a bit of googling, and it appears that MIT has a similar course[2] with a free online textbook -- I'm going to check it out later.(I haven't architected a really large codebase before, so take all this with a grain of salt...)
[1]: http://plasma.cs.umass.edu/emery/grad-systems [2]: http://ocw.mit.edu/resources/res-6-004-principles-of-compute...
⬐ dustingetz⬐ ajuc> it appears that MIT has a similar course[2] with a free online textbooklol. you're looking for SICP[1] and if you're interested in this stuff, and you haven't read it yet, you should a) buy it and burn all your other books so as not to distract you, b) google "sicp site:news.ycombinator.com" to convince yourself i'm not full of hot air, and c) email me so i can get you in on my online participate-as-you-have-time discussion group which is not yet organized but we will start in a week or two ;)
[1] http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-4.html#...
I am interested in functional programming, because it's interesting. Nothing to do with managing complexity. And I have a few friends interested in exotic declarative languages becasue of "coolness factor", not because they need such languages in their job.I also have a few experiences with writing hobby projects in functional languages, which never went anywhere, and what I have finished, I did using the simplest tools I had on my hand (turbo pascal, python, java, javascript).
So I think interest in functional languages isn't really good predictor of anything.
⬐ Roboprog⬐ jamesliYeah, but give me a language (e.g. - Perl, etc) that lets me make closures, instead of anonymous inner classes that implement an interface with exactly one method, any day. Fascist OOP can lead to some real code bloat, and I suspect that is starting to dawn on the leadership of this industry.A bit tangential, but it's something I am reminded of day in and out trudging through Java code at work, and one of the "quick payback" reasons I'd like any new guy to understand FP.
(oh, and Python and JavaScript are, at least in a "compatible style", functional programming languages)
Have to show some support for this post.Engineering is a combination of technology and art. Therefore, it is impossible to have a simple process for interviewing engineers that magically works. Otherwise, such posts would not have been brought up so many times in HN.
Also, some people are good at people evaluation, some are not. An excellent engineer could be a lousy interviewer. On the other hand, a mediocre engineer is lack of the ability to evaluate a top engineer within an hour. Therefore, the employer must first know who are his/her best interviewers. If s/he can't identify her/his own people, I highly doubt s/he is able to identify good candidates.
The hiring signals I pay attention to are one's curiosity and one's depth in understanding in at least one programming language or one computer science topic, no matter if that topic or programming language has any relevance to the position to be filled. Here is the rationale. To be a very good engineer, one needs both internal motivation and intelligence. Both of the two signals speak for internal motivation. A deep understanding on any topic shows the candidate is sufficiently intelligent. Such a candidate, even if s/he knows little about the languages and/or the frameworks the position requires, s/he would learn it very fast and would be very good at it. To be realistic, it is really not hard to learn a programming language and a framework.
⬐ kamaalGood thoughts!I think software has a lot of reusable principles/concepts. And these days syntax is really skin. Programming languages get used a lot because their ecosystem.
You are definitely very correct to demand perfection in at least one walk of our profession. Because those concepts get reused nearly everywhere.
Another thing that I don't understand is rejecting people merely because they don't know answers to some questions from the algorithm and data structures text book. Software engineering today is so much about so many things.
Above all I would say productivity and passion is the only factors I would use to judge people today. Because those factors decide nearly every other factor.
I totally agree. My statement about simple vs. easy is actually a weak attempt at restating some of the principles that guided the design of Clojure (from Rich Hickey's talk "Simple Made Easy": http://www.infoq.com/presentations/Simple-Made-Easy) JS is approaching big apps with Node.js, and Clojure is approaching browser JS with ClojureScript... not sure how it will play out.What are the current trends in language use? Are people moving away from Python, Java, and C++? and if so, to what?
In my opinion, objects conflate entirely too much and lead to tangled code, especially if there is any data transformation involved. Have you seen Simple Made Easy? [0]
⬐ drostieI will say this: the reason I keep coming back from Lisp (and PHP) to JavaScript and Python is that I can do lots of functional things in the latter, but I get that gosh-darn useful little dot operator.Here are some of the many ways to silence someone who is shouting in all caps:
I don't really care about the parens and where they are, but the fact that clisp, php, and perl put this function in the global namespace bugs me to no end. It's a function which only makes sense when you have a string. Other things don't have the sort of "case" such that you could "lowercase" them.(string-downcase yelling) ; common lisp strtolower($yelling) // php yelling.toLowerCase() // js lc($yelling) # perl yelling.lower() # python⬐ adeelk⬐ bwarpFor what it’s worth, Clojure is a Lisp with namespaces: (string/lower-case yelling).⬐ mattdeboardCurious then how you feel about `sorted()` being in the global namespace. Point being I don't understand how `.lower()` et al., being class methods instead of global functions is an argument for the greatness of Python. Ultimately the responsibility is yours for invoking it in the right place with the right type of object, no matter where you put the parens.⬐ drostieIn Python that actually makes some amount of sense, because Python ships with something like five different sorts of lists (arrays, lists, tuples, OrderedDicts, generators) and it's a reasonably generic idea. And it helps that for the one 'proper' case of this, lists, Python also supports list.sort(), so that "it is where it's supposed to be" as well.The only problem with list.sort() in Python is that it's void; it returns None. It should either return self (and sort self) or return a sorted copy of self, like sorted() will.
On the other hand, in JavaScript, array.sort() is known to be a little broken:
Wat.> [48, 19, 7, 14, 30, 22, 45].sort() [14, 19, 22, 30, 45, 48, 7]It's true that I have ultimate responsibility for my code, and it's true that in Python I can write:
...and unlike Java it will not complain that it has no idea how to "lower" 3. But it still suggests like Java suggests that we're going to narrow down the wildly branching tree of possibilities.x = 3 x.lower()When I'm sitting in the Python REPL, and I have an object x, I'll often just call dir(x), to see what I can do with it. What would Common Lisp tell me? It would kindly tell me that it's syntactically valid to call (string-downcase 3), even though that will produce a noisy error. So if I wanted to list all of the things I can do with 3, we would be here for a long time.
⬐ mattdeboard> unlike Java it will not complain that it has no idea how to "lower" 3.AttributeError is a complaint, isn't it?
⬐ drostieI thought you were arguing against the magic of Python. :PThe point I'm making is I suppose one about personal mental hygiene, but I am choosing an odd language for it. Because I am talking about how computers can reason for us, and can help us reason. Python will not complain about x.lower() until it actually occurs; it doesn't reason at all about x. On the other hand, the Python interpreter gives you some leeway to sit inside the code as it's being run, to say "okay, what can I do with x now that I have it?" -- which is a start.
It's especially pivotal for me when I'm working with an external software package which isn't well-documented. I hate working with someone else's packages in Lisp. With Python, I can usually reverse-engineer what they were thinking pretty easily. With Java, your code editor provides another method to do the same thing, preventing you from writing things which wouldn't have made sense to the package designers -- this helps you know what does make sense, to help you understand what they were thinking.
Like I said, my broader point is about mental hygiene, and there is a missing connection between mental hygiene and what computers can do for me. I think this is best summarized by Minsky and Sussman's reminder: "programming is a good medium for expressing poorly understood and sloppily formulated ideas." That's the missing connection. When I have a function which I don't completely understand, assigning it to a namespace helps me to be formal and precise about the situations where it is useful, and allows me to reason about the situations where it is not useful.
So for all that it might pride me that I can just look up the array API on developer.mozilla.org and quickly learn the difference between "shift", "splice", and "unshift", that's not as important to me. It's something more poignant that interests me, something about how, when I have a string, my brain quickly reasons about what functions are correct for it. I don't know how much Hungarian notation you've worked with, but the property-based notation has some Hungarian quirk to it where you can just feel that you've got the right sort of expression.
⬐ mattdeboardExceptions are magic?⬐ drostieWhat?This actually only happens if you don't think first or don't understand ever. Thinking and understanding takes more time than programming in my experience.The same level of fail will accumulate regardless of the language if you don't know what you are doing.
⬐ palishFor an excellent example of how a clean object model can solve extremely difficult technical problems, check out LMAX's "Disruptor" framework: http://code.google.com/p/disruptor/By rigorously separating the concerns into a clean object model, LMAX achieved a level of performance which might correctly be labeled "miraculous". http://screencast.com/t/g67kFj8nRue
It's written in pure Java. Amazingly, I haven't found anything that's achieved better performance thus far. It's very elegant.
⬐ silentbicycleNo, the whole point is that they're getting major speed-ups by using arrays and a giant ring buffer to avoid object allocation, reduce garbage collection, and improve cache behavior.They're writing really tightly optimized C. In Java.
⬐ NoneNone⬐ bengl3rtThat was an incredible read. Thanks for the link.⬐ ntoshevOOP has nothing to do with the Disruptor pattern achieving that performance. I agree the concept is elegant, but I don't think the Java framework implementing it is. You can see a less general benchmark done in far less code in Go and C++: https://gist.github.com/1218360 (and discussion http://groups.google.com/group/golang-nuts/browse_thread/thr... )
Have you ever looked at a class named ObjectFactoryFacadeCollection and thought to yourself, "oh boy, this part will be fun to read?"On one hand there's the complexity of the problem you're solving. On the other hand, there's incidental complexity. The ObjectFactoryFacadeCollection class squarely falls into the incidental complexity category. In other words, the moment you are writing a class of that sort, you have stopped working on solving the problem you set out to solve -- you're solving a problem that was invented by your tools, design, or limits of your understanding.
Rich Hickey gave an extremely good talk about trying to avoid this kind of incidental complexity: http://www.infoq.com/presentations/Simple-Made-Easy .
⬐ hackinthebochsThis isn't necessarily true. Sometimes you do in fact need these types of abstractions. This is why they've been made into patterns. The trick is to not use it before its necessary. The mere existence of it doesn't imply overengineered code.⬐ humbledroneYes, of course you do sometimes need these types of abstractions, but you seem to have missed my point: they are a factor of incidental complexity. To restate, they are not at all inherent to the problem you are trying to solve. They are inherent to the tools with which you are solving the problem.For instance, if your problem is calculating the trajectory of a projectile, a solution certainly exists that does not involve anything at all like an ObjectFactoryFacadeCollection. However, certain solutions involving unnecessarily complex abstractions could conceivably require one. This is incidental complexity. On the other hand, all solutions will require some information about the projectile's velocity, gravity, and so forth. This is complexity that is inherent to the problem itself.
Rich Hickey's "Simple Made Easy" talk from Strange Loop is filled with great ammo: http://www.infoq.com/presentations/Simple-Made-EasyPersonally, it gave me new vocabulary and conceptual tools for explaining why I like Clojure so much.
I liked the article. Here's my humble summary of the main 2 points1. Don't always make decisions in 0 minutes (instantly). Instead, think about them for 1 minute. The time difference is small but the results may not be.
2. Don't always default to the easiest solution.
Point 2 reminds me a lot of a really great presentation I watched recently by Rich Hickey (the creator of the Clojure programming language) which highlighted that easy solutions are not always the simplest solutions; however it is the latter that we should strive for and not the former. The presentation is really good and contains some insightful thoughts about design and decision making - www.infoq.com/presentations/Simple-Made-Easy
Video for "Simple Made Easy" from Strange Loop: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ erichoceanThanks for the link, and to the others, for the recommendation. What a great talk!
Strangeloop - great speakers (including my favorite keynote in years by Rich Hickey http://www.infoq.com/presentations/Simple-Made-Easy) and great variety (https://thestrangeloop.com/sessions). I'm also happy that all of the presentations will (eventually) be available on the web (https://thestrangeloop.com/news/strange-loop-2011-video-sche...).I'll definitely be attending in 2012.
Might have helped to linked to the Rich Hickey talk I assume you're borrowing those semantics for "easy" and "complect" from: http://www.infoq.com/presentations/Simple-Made-Easy(a thought provoking talk for those who haven't seen it)
⬐ malandrewYup. It was such a good talk, I assumed it had made the rounds among HNers that I didn't need to link to is. I assumed wrong.It is a brilliant talk. The only part that he left out of the discussion, but is worthy of a talk in its own right is the notion of the community (formation and characteristics) as one of the artifacts that result from the constructs of a language.
When Rich Hickey talks about code simplicity, he is referring to things that Ruby (simply) cannot simplify.
⬐ saturnflyerI took that quote from that presentation. He hates all OO code, so it's not specifically Ruby that's the problem for him, but object orientation. His point, however, is that being able to reason about your program is important. That is also a driving factor behind DCI. OO programs often hide exactly what happens among objects because we mostly see everything from the perspective of a class, rather than a perspective of being among the communicating objects.⬐ djacobsI'm not sure that he broadly hates object-orientation as an idea. It's true, he hates much of the conflation that goes in OO (E.g., conflating classes with namespaces, objects with data structures, encapsulation with object ownership, and identity with state). And he hates the reliance on tests to overcome that conflation and confusion--something that's hugely prevalent in the Ruby world. But he does allow most of the features of OO in Clojure.
This is explored very well in Rich Hickey's 'Simple Made Easy' talk, check it out: http://www.infoq.com/presentations/Simple-Made-Easy
Intressting topic.Here are some intressting things to look at all about Simplicity and maybe programming.
Stuart Halloway: "Simplicity Ain't Easy" (https://blip.tv/clojure/stuart-halloway-simplicity-ain-t-eas...)
Again from Stuard Halloway but thistime more about programming less about what Simplicity is.
Radical Simplicity (http://skillsmatter.com/podcast/java-jee/radical-simplicity)
Simple Made Easy by Rich Hickey (http://www.infoq.com/presentations/Simple-Made-Easy)
In short: FP makes programs easier to reason about and understand by using trustworthy abstractions. Here are some resources to check out, which explain better than I could:Why Functional Programming Matters: http://www.cs.utexas.edu/~shmat/courses/cs345/whyfp.pdf
Out of the Tar Pit: http://web.mac.com/ben_moseley/frp/paper-v1_01.pdf
Simple Made Easy: http://www.infoq.com/presentations/Simple-Made-Easy
I don't know these tools you mentions but I thing generally that these kinds of tools are the problem or at least they are treatments of the symptoms.Enterprise tools tend to make everything more complicated then it is (somebody else mentiond map/filter as a cure) and to help you fight this complexety you need even more complex tools. In the end you just have tonnes of Code and Tones of tools with tones of configuretions.
Abstracting away ofer thing that are hard to abstract is a typical error these kinds of tools make. You cant just abstract away networks or databases. Sure a simple ORM is fine for most blogs but if you end up writting 30 lines of java code to do something you could have writen in 2 lines of sql something is not right.
This video teaches the basic idea: http://www.infoq.com/presentations/Simple-Made-Easy
Well I think its only cheaper at first and even if people know better they are forced to use a stupid java framework (that abstracts away the network) even if the know that it will end up badly.A other problem is that people often get tought that you need <input some bad framework>. You can't do distributed computing if you done use some kind of framework. At least the places I know they would never tell you something like "just send json from one node to the other if thats all you need".
At clojure conj there where some talks about this, but the videos are not out jet. See these presentation on Concurrent Stream Processing (https://github.com/relevance/clojure-conj/blob/master/2011-s...) or this on Logs as Data (https://github.com/relevance/clojure-conj/blob/master/2011-s...)
For a other example that works in quite simular ways look at Storm (in use at twitter. Its all sequential abstractions. See this video by Nathan Marz (look all videos you can find): http://www.infoq.com/presentations/Storm
For a more philospical perspective look at the videos by rich hickey: http://www.infoq.com/presentations/Simple-Made-Easy
F# seems to have a Hindley-Milner type system, as described some years ago also by Daniel Spiewak[1].Which is a vast improvement over more mainstream type systems, while not as powerful as traditional logic type systems, such as those used in First order and Higher Order Logic.
However, I personally rely more on unit tests than on type systems to make sure the code is consistent. And when I do that, specially when I write the test before the code, I find the type system getting more in the way than helping me. Rich Hickey, Clojure's creator, compared[2] these to guard-rails.
[1] http://www.codecommit.com/blog/scala/what-is-hindley-milner-...
This seems like a strange accusation. It seems like the usual complaint is that lisp programmers are more concerned with elegance than getting anything accomplished.I think this provides an interesting counterpoint: http://www.infoq.com/presentations/Simple-Made-Easy
⬐ tsothaHeh. As much as I agree with pretty much everything he says in that presentation the GP's point is pretty relevant here: Rich Hickey is far, far to the right on the programming bell curve. Things normal people will have real difficulty grasping are going to seem glaringly obvious to someone like that.
⬐ va_coderGreat presentation, but it got me thinking. Am I wasting my time trying to get software just right? Is it worth my time to learn Clojure or Haskell, when I don't even know what I'll use it for?How many programmers do you know that are learning all kinds of languages and technologies and methodologies and other things to improve the quality of the software they write and yet will probably sit at a desk writing code for the next 30 years? As opposed to starting a business, getting financial free, etc.
Take the guy from Duck Duck Go. He wrote all of that in Perl; talk about easy, but not always so simple (to maintain). What if he spent his time learning Lisp and Monads instead of writing an app that lots of people use?
⬐ davidhollander⬐ gregwebs> Is it worth my time to learn Clojure or Haskell, when I don't even know what I'll use it for?I don't know if it's a binary decision between investing a lot of of time, or investing none. You could skim the reference manual, and if anything jumps out at you, you have a topic for future investigation, or a non-zero quantity of information to base your decision to "is it worth more time?" on.
If you mean on a very abstract level, the balance between learning what others are doing and producing your own stuff, you might enjoy Richard's Hamming essay "You and your Research", pg hosts a copy on his site: http://www.paulgraham.com/hamming.html
⬐ tlrobinsonI find I can't learn a language very well without having a real project to use it on anyway.⬐ va_coder⬐ seancorfieldThat's true.I'm just thinking my time might better be spent thinking about business ideas, and then trying those ideas out on Heroku. As opposed to learning about some technology that may make me a better programmer but may not really help me get to where I want to be, which is having a successful product that I own equity in.
Is it really worth my time to learn the intricacies of functional programming? Am I still going to be writing code for some corporate overlord 5 or 10 years from now?
⬐ fogusIsn't that up to you?Am I still going to be writing code for some corporate overlord 5 or 10 years from now?⬐ spaznodeDid you watch the video? He wasn't talking about tools and he wasn't talking about clojure. It was programming in general and if you have to ask if it's worth your time the obvious answer is no.⬐ va_coder⬐ takeoutweightYea I did, but I don't take what Rich says as gospel. I think for myself, not just about code but how I allocate my time.⬐ crc> I think for myselfThen you should think that there may be others who aren't really that concerned about being their own boss and financial freedom(strange as it might sound); others who love learning new perspectives. Other than saying that clojure may not be worth your time, you offer no insight. Thanks for making your preference clear, now can we get back to discussing the talk?
I fear you've missed the thrust of Rich's talk. Functional programming may seem "intricate" because it is unfamiliar, but if you're willing do do a little bit of up-front unlearning of the massively complex (but familiar) tools you're used to, you may find yourself able to work on projects of a much bigger scale and functionality.See the slide at 17:20 -- easy stuff (perl,ruby, blurb) gives you 100% speed at the beginning of a project. If you don't expend effort into making things simple, you will "invariably slow down over the long haul."
"Am I wasting my time trying to get software just right?"Don't we all want to "get software just right"?
"Is it worth my time to learn Clojure or Haskell, when I don't even know what I'll use it for?"
Reasonable question. Pick a project, choose a language. I introduced Scala where I work and it solved a problem but wasn't optimal for our team. Then I introduced Clojure and that's working better for us. Real world problem solutions will help you validate your choices (there was a great talk at The Strange Loop on real world Haskell usage at a startup, BTW).
"What if he spent his time learning Lisp and Monads instead of writing an app that lots of people use?"
Like Paul Graham? (Viaweb)
⬐ jcromartieTo me, Clojure is about as productive as banging out a script in Ruby. It's way more productive than writing the same thing in any language where I can't (easily, or at all) just fire up a REPL and start hacking.I can actually just crank out code that I use. It can be quick and messy. Clojure is not concerned with type theory and provable correctness.
But the end result of a quick hack, in Clojure, is often something (or is made of of parts) that can be applied to other problems by pulling it out into a library, or by abstracting one more argument to a function, etc..
I think someone like Gabriel Weinberg could get along just fine in Clojure, with much the same spirit as hacking Perl, but maybe with better results.
⬐ swahI kinda regret having chosen Clojure for my project. Its not that I can't express ideas in very little code, its just that my workflow is different from languages like Python.In Clojure, it seems that I can't apply the method of spike solution (http://c2.com/cgi/wiki?SpikeSolution) and then refactor it into working code like I do with languages like Python or C.
⬐ seancorfieldI'm curious why you feel you can't create spike solutions in Clojure?⬐ swah⬐ jcromartieProbably because pseudocode in my head is imperative.⬐ mnemonicslothI think that's normal. Part of learning Clojure is learning to think in another kind of pseudocode.What does this imply about the languages you already know?
I'm wondering what about spikes doesn't work in Clojure? I usually understand a spike as a "proof of concept" that doesn't handle all of the edge cases.A good talk. Leave it to a lisper though to call testing and type-checking "guardrail programming". Hickey says instead you should reason about your programming without acknowledging that testing and type-checking are ways to have executable documentation of your reasoning about your program. Testing does in fact feedback into complexity - if something is hard to test it may be due to complexity that you realize you should get rid of.⬐ akkartik⬐ falavaYeah. I like tests because they let me export my mental state about a codebase.. and reimport it later. I can get the code back into my head faster.I use lisp -- and half my code is tests.
⬐ postfuturistHe says relying on tests and type-checking to verify a program still does the right thing after making changes is "guardrail programming".⬐ jemfinch⬐ stuarthallowayNone of us do "guardrail driving", but we still put guardrails on roads.⬐ skew⬐ puredangerI enjoyed being a passenger for some "guardrail driving"http://www.eurail.com/planning/trains-and-ferries/high-speed...
These too run on rails.
⬐ jurjenhHowever, on most highways the guardrails are only on the dangerous sections.So sticking with this analogy, we should only need to use testing in the more intricate / complex parts of our code. However, current testing best practice seems to be to test everything possible, thus potentially wasting a lot of time and effort into aspects with a low ROI.
There could be some lesson in this...
⬐ bitopsThat's an interesting point. I've noticed that as I grow as an engineer, I still place a high importance on tests, but the type of tests I write and how I write them has changed a lot.When I first started testing it seemed like the world suddenly got really scary and now I had to test everything. I ended up testing ridiculous stuff, things that the language would provide by default. (I did this in many languages which is why I don't mention a specific one).
What I've found valuable as I do testing (I do TDD) is that it has made me change how I think about design and composability.
I agree that there should be a greater focus on "what is appropriate to test" but even knowing how to write tests and what to test is a skill in itself.
⬐ chousukeI think to begin with it's futile to try to cover all relevant behaviour in tests as you introduce new code. Some basic functionality tests will do fine to prevent anyone from completely breaking the code, as well as providing fair documentation as to what the developer expects the code to do.However, I think regression tests are useful. Once you find a bug and fix it, the things learned from fixing the bug can be expressed in a test, to prevent similar bugs from happening again. In such a case, the test documents an unexpected corner case that the developer was unable to predict.
⬐ dvogelYour regression tests sound very similar to what I call perl tests. The perl community was ahead of it's time by distributing a test suite with packages on CPAN. Tests that come out of bug fixes tend (at least for me) to be complexity tests. Essentially they are a 2x2 test of the interaction of pairs of conditional paths with some interaction between them. This dovetails nicely with Rich's point -- keep things simple but in those few inevitable areas where complexity will arise, make sure you can reason about them. I just write regression tests around them to ensure that my reasoning about them is correct. Rich skips the tests because he's better at remembering or re-reasoning through them again :)The slide where this comes up (~15:45) is about debugging. I think the point Rich is trying to make on that slide is that a bug in production passed the type checker and all the tests. Therefore, tests are not solving the problem of building high quality systems.Rather, tests (and type safety) are "guardrails" that warn when you when you are doing something wrong (they are reactive). As Rich said on Twitter (https://twitter.com/#!/richhickey/status/116490495500357633), "I have nothing against guard rails, but let's recognize their limited utility in trip planning and navigation."
I believe that linking back to the greater context, Rich is saying that simplicity and doing more to think about your problem at the beginning (proactive steps) provide value in building systems that are high quality and easy to maintain. I think he is at least implicitly challenging whether the value you get from simplicity is greater than the value you get from an extensive test suite.
I do not hear his comments as anti-testing, but rather more as pro-thinking and pro-simplicity. Personally, I find tests useful. I write them when writing Clojure code. However, I also get tremendous value from focusing on abstraction and composability and simplicity in design.
⬐ bitopsThanks for distilling it. Your comment makes me want to watch the presentation and also to perhaps take a closer look at Clojure. Good thoughtful reply.⬐ bitopsOkay, follow up, I watched half of the talk. Wow. What an insightful guy. I really enjoyed what I heard so far.The section about testing and guardrails seems to have been blown way out of proportion. I fervently believe in Agile/XP practices, TDD and all such good things. But I'm not naive enough to say that "because I have tests, nothing can go wrong". And that seems to be his main point here.
It makes me think...it seems like all languages and methodologies have a "Way" of the language (call it the Tao of the language). The closer you get to "The Right Way of Doing Things" within a language, the more you reach the same endpoint. And I feel that's what Rich is talking about here.
What I like about this talk is that it could be useful for programmers of any caliber or toolset to hear. If I could have heard some of these principles when I was first learning BASIC, it would have been useful.
⬐ dexterous> And __I feel__ that's what Rich is talking about here. (emphasis mine)I guess it's just that isn't it. There's a lot of talk here about what Rich might have/probably implied. I suppose it would have been infinitely more helpful if he would have just been explicit about it as opposed to projecting a slightly philosophical [sic] point of view.
Difficulty of writing a test can certainly be a complexity indicator, but in my experience the evidence is against testing having served this purpose very well to date, at least for the kinds of complexity addressed in this talk.If you look at around 31:27 in the talk, you will see ten complex things, with proposed simple alternatives. If testing helped people feel the pain of complexity and discover simple things, we would see projects where people had problems writing tests, and switched strategies as a result.
Do you see people moving from the complexity column to the simplicity column in any of these ten areas as a result of writing good tests? I don't. What I see is people cheerfully enhancing testing tools to wrestle with the complexity. Consider the cottage industry around testing tools: fixtures, factories, testing lifecycle methods, mocks, stubs, matchers, code generators, monkey patching, special test environments, natural language DSLs, etc. These testing tools are valuable, but they would be a lot more valuable if they were being applied against the essential complexity of problems, rather than the incidental complexity of familiar tools.
⬐ spaznodeJust look at this. He keeps rolling out what is usually hard earned wisdom gained over years of time of experience while constantly striving to improve yourself and any software you work on.Do yourself a favor and take the shortcut of listening to this talk..not to say he may not join a cult religion at some future point in time and come out with crazy crackpot ideas then but everything I've seen and read so far are things that all senior+ quality engineers should find some common agreement with.
⬐ gregwebsYes, I am constantly reducing complexity, but only after first writing tests that cover the reasoning of the program so I know that it won't change. Without some of the "cottage industry" of testing tools, it would take me multiple times longer to write tests, and I would do less reducing of complexity.And yes, I have seen developers make large changes in their code towards simplicity because it was hard to test.
If someone is going to write complex code, they are going to do it with or without tests. If someone is going to write simple code, tests are a wonderful tool to have in that endeavour.
⬐ amouatWhy do you consider code generators, monkey patching & DSLs to be "testing tools"?⬐ stuarthalloway⬐ gtaniI don't. I refer here only to their use in that context.⬐ amouatI'm sorry; I think I'm being dense - what is their use in that context?(I don't disagree with your main point, but I don't quite see where those techniques fit in).
⬐ fogus⬐ DanielRibeiroSome examples off the top of my head that use these techniques:* code generators: Visual Studio, Eclipse
* monkey patching: RSpec
* natural language DSL: Cucumber
⬐ amouatThanks! Very good examples.I can see how monkey patching could be useful in mocking or something similar. I've never really used a language that supports it though.
I'm not entirely sure what Eclipse's code generation has to do with testing, but given the other examples I'll assume I'm being stupid again ;) I'm actually working with a lot of EMF generation stuff at the minute which can be quite painful.
I see this mostly in Java. Outside, you can deal with simple dsls (it "should something") and simple functions (equal x, y).But yeah, on Java and C# land, the complexities of the type system and the class based OO complect the testing, yielding this big complex testing system (which are large enough to be called testing frameworks).
This is a purely philosophical debate, it's not to say the testing ecosystem in clojure isn't well done:http://clojure-libraries.appspot.com/category/137002
my 2 cents
⬐ jcromartie> fixtures, factories, testing lifecycle methods, mocks, stubs, matchers, code generators, monkey patching, special test environments, natural language DSLsSTOP STOP STOP! MAKE IT STOP!
This is the clearest indication of how (dogmatic) testing has become a vehicle that introduces complexity, rather than something that alleviates complexity.
You may also want to look at this other great video:Stuart Halloway: "Simplicity Ain't Easy"
http://blip.tv/clojure/stuart-halloway-simplicity-ain-t-easy...
⬐ ExpiredLink⬐ spaznodeThis kind of arrogance has no future.I can't add anything more to what @jsmcgd said but Rich's strange loop talk really brightened my day and more importantly gave me the tools to express what I sometimes try to share with other developers in the clearest way possible. Thanks man, really awesome talk. Invaluable if more people could start thinking this way. (which it sounds like oracle/java 7,8,.. will also help to do whether they like it or not and that's also awesome for that general clump of dev brethren)⬐ neopanzI feel smarter having watched this talk: it gives you tools to think about thinking as you come up with new designs. Also love how Rich manages to find the right metaphors to illustrate abstractions, he's a great communicator.⬐ None⬐ plinkplonkNoneThe interesting thing about this talk is how Hickey's (very valid) distinction between "easy/familiar" and "simple/unentangled" can be applied to argue for powerful type systems like Haskell's or OCaml's. Likewise with the "benefits vs tradeoffs" argument.⬐ shoover⬐ ironchefLikewise, some points in the talk brought to mind the OO SOLID principles. It's unfortunate that much of the discussion I saw on HN and twitter after this talk was argument about the value and purpose of testing. More useful would be examining the point of the talk and considering any common ground between Rich's "Simplicity Toolkit" and where things stand now with languages that aren't Clojure.Take your language of choice. If you're not in a Lisp already, you can't do much about syntax vs. data, but what about the rest? Is it easy to work generically with data and values instead of making custom classes and mutable objects for every piece of data? Is it possible? Can we make it better? Are there persistent collections or managed refs available? Can we write them as libraries? Within the language's polymorphism construct, can we extend a type we don't control to our abstractions without creating adapters and more complexity around value and identity? What about transactions?
Ugh. Why don't they release the presos as opposed to having to deal with synchronous video?⬐ jhickner⬐ agentultraIf you mean just the slides, most of them are in this github repo: https://github.com/strangeloop/2011-slides⬐ ironchef⬐ puredangerAwesome! Thx!⬐ abscondmentFor some reason, these slides are only available in a flash widget that's synchronized with the video. Here's a little script to grab the flash and build a PDF for yourself.ImageMagick and swftools required.
[Edit: required packages]#!/bin/bash for s in {1..39}; do wget http://www.infoq.com/resource/presentations/Simple-Made-Easy/en/slides/$s.swf; done for swf in *.swf; do swfrender $swf -o $swf.png && rm $swf; done convert `ls *.png -x1 | sort -n | xargs echo` slides.pdf rm -f *.swf.png⬐ malkiaThat was Easy! (pun intended)Great talk by Rich Hickey, and thanks for the script.
⬐ markokocicI agree with "teach a man to fish ...", but you know, some people are far away from the sea (linux) so just providing them with the fish (pdf) is also a good option.⬐ julesCopyright.⬐ malkiaThis is in no way Linux specific - most likely OSX can do it, and with enough time cygwin too. Probably BSD's and others...This was done at Rich's request. I've asked whether we can release them now that the video is available.⬐ JoshTriplett⬐ jasonwatkinspdxAny chance of releasing the videos somewhere that doesn't require Flash?⬐ puredangerNo, sorry.⬐ ludwigvanI watched it fine on my iPad, it should be viewable in an HTML5-mp4 capable browser I guess.⬐ JoshTriplettSure enough, if I fake my User-Agent as an iPad, I get a <video> tag referencing a .mp4, which I can then download and watch. Now if only infoq would provide a "download" link pointing to the same .mp4.This is my number one gripe about infoq. I love skimming slides to see if it's worth investing an hour in watching a talk.⬐ spooneybargerI have no interest in seeing slides, I want video.⬐ neopanzI empathize, but at the same time, 5 min. of slide browsing would not drive the point home. People are trying to skimp when they should invest the time. Relax, reserve yourself an hour and enjoy the talk. This is a good one, and getting signals through sound, visual and text will leave a better imprint in our brains.Great talk.Simplicity is, of course, key; but a few of his applications of these principles are misguided IMO.
Ex: The "Parens are hard!!" slide. He suggests that parens are "overloaded" in CL/Scheme because they are used to wrap functions, data, and structures all the same. However he completely misses the fact that by representing everything with parens, CL/Scheme remove a lot of complexity in software written in those languages.
AFAIK, the only languages that do macros right are homoiconic. Anything else is too complicated. Just look at Perl 6 and Haskell macros. They require learning special syntax and really crazy semantics. Using them will probably just make your program more difficult to understand.
He also "rails" against testing. He misses the virtues of a proper testing infrastructure in producing reliable software: if you don't test it, how do you know if it works? Because you reasoned about it? How do you know you're reasoning is correct?
True, "guard rail" testing isn't a crutch that will automatically produce reliable software. But I think Rich relies too much on this narrow view of testing to make his point. Testing is good and necessary.
And the jab to the Unix philosophy? ("Let's write parsers!"). Isn't that what we do on the web anyway? AFAIK, HTTP is still a text-based protocol. Any server that speaks the protocol has to parse a string at some point. So what was he getting at there? The Unix philosophy is about simplicity and has a lot to offer in terms of how one can design software to be simple.
Overall though, it's a great talk. I just think that if he wants to get pedantic then he could be a little more thorough and less opinionated. Everything he said about designing simple systems I pretty much agree with, but I think he glosses over some finer points with his own bias of what simplicity means.
⬐ swannodette⬐ vselovedHaving written a bit of Scheme and Clojure - Clojure's distinction between data structures make many things simpler - from writing code to writing macros.As far as his comments on testing - I suggest you read this, http://blog.8thlight.com/uncle-bob/2011/10/20/Simple-Hickey....
⬐ radarsat1⬐ subbImportantly, it should be mentioned that despite the way it distinguishes between different data structures, Clojure manages to retain the advantage of "representing everything with parens" by instead making sure that everything implements a common _interface_, (i.e., seq). In other words, as opposed to CL or Scheme, it separates logical list manipulation from the physical data structure, giving the best of both worlds. That's a big advantage for Clojure.⬐ agentultraBig advantage for Clojure over what?The point I was trying to make about parens is that I think Rich is creating a straw man from them. Parens in CL/Scheme don't have any special meaning other than demarcating lists. A Lisp compiler/interpreter just evaluates lists of symbols at the end of the day.
⬐ radarsat1⬐ bitsaiHis point is that it puts together (complects.. ha!) lists, the data structure, and list-like operations into one and the same thing, when logically they are separate ideas. He's trying to point out that separating things brings simplicity, even if you end up with more of them, therefore unifying everything under one syntax for example is not necessarily "simpler". You may not agree, that's okay, but it's consistent with what he was saying, not a straw-man.⬐ agentultraThat's where I think he is 'discovering' complexity and in fact creating some.That code and data can both be represented as lists is a major feature of what makes CL so compelling.
And I suppose that is the major contention -- is 'code as data' a complex idea? I say it's simple. There's no difference between the data structure of the code and the data structures the code acts on, so using the same operations on either should be trivial. With a handful of simple evaluation rules and a small number of special forms you can bootstrap an entire language written entirely in itself. Functions, classes, interfaces, namespaces, the whole nine-yards. The list is just an implementation detail and it's a very simple one that enables some very elaborate structures.
⬐ swannodetteThere's nothing you've expressed that doesn't apply to Clojure as well. I'm assuming you haven't done much Clojure and thus can't really illustrate what the problem is in practice.Precisely. Clojure was my first Lisp, and I got spoiled by the "every collection is a seq" uniformity. In Clojure, functions like 'count' can operate on all collections, whereas in, say, Racket, you have an explosion of methods like:length
vector-length
string-length
hash-count
set-count
...
Clojure embodies Alan Perlis' idea that "It is better to have 100 functions operate on one data structure than to have 10 functions operate on 10 data structures.", which is one of the many reasons why I enjoy the language so much.
⬐ radarsat1> "It is better to have 100 functions operate on one data structure than to have 10 functions operate on 10 data structures."Oddly enough though, you yourself are pointing out that it is better to have 1 function that operates on 10 data structures. ("length" operates on vectors, strings, hash tables, etc.) On the surface this seems opposed to the quote you chose.
However, it is clearer if you replace "data structure" with "interface". The is classic separation of concerns. When specifying the "what", we can get away with "100 functions operate on one interface", but the efficiency, the "how", can be specified independently based on the choice of data structure implementing that interface.
⬐ bitsaiYes, that is a better way of making the point. Thank you.I think the Unix philosophy jab is about data. Instead of using string/text file with no form, I think he's suggesting that a standard format (like JSON) could be much simpler.HTTP is just that, a protocol : a standard way for two entities to communicate. In Unix, there's no protocol, its just text without any standard form, which makes it difficult to write tools.
⬐ IvarTJWithout being confident enough to have voiced it earlier, I thought similar thoughts. Clojure appears to depart from something that characterizes both traditional Lisp and Unix systems – having one universal interface, with a big emphasis on one. Though by the definitions he outline, that would perhaps be easy more than simple.⬐ chousukeClojure is homoiconic just as much as CL and Scheme are. It just happens to use more than one datastructure to represent code.The "oneness" in other lisps does not make things simpler, nor, in my opinion, easier. The reason why parens (lists) in traditional lisps are not simple is that they complect several different purposes. In contrast Clojure uses list forms (almost) exclusively for "active" expressions such as function and macro calls. For grouping and binding, vectors (and sometimes maps) are used instead.
In this manner Clojure manages to keep the roles of different data structures in code mostly simple.
⬐ gruseomThe reason why parens (lists) in traditional lisps are not simple is that they complect several different purposes.You've repeated what Hickey says in the talk, but I'm not sure I buy it. [Deleted boring stuff about boring parens here.]
The trouble with the general argument is that you can add constructs that are individually simpler but nevertheless make a system more complex. It's overall complexity that we should seek to minimize.
⬐ chousukeHow does adding several independent simple things make systems more complex in a way that is unavoidable (ie. incidental complexity, not problem complexity)? The interaction between simple elements will be explicit, whereas complex elements by definition interact in ways that you can't control.Of course, sometimes the complex tool might be exactly what you need to solve your problem, making things easier. But in cases where you need only a part of the functionality of this tool, the complexity bites you as all the unneeded functionality (along its cost) is forced on you.
What sort of "overall complexity" does having several data structures in code introduce? As Rich Hickey says in his talk, complexity is not about cardinality.
In Clojure's model, the elements are distinct, and as such there is more simplicity in the system than in lisps where you have to understand the difference ("untangle" the complexity) between several different uses of lists to get anywhere.
I also think having several datastructures makes code easier to read due to the visual differences, but that's a separate discussion. :)
⬐ gruseomAdding things means more things, which means more complexity. Doing so is a net win only if the new things subtract more complexity than they add. To figure out whether they do, you have to consider the system as a whole. That much is clear. Do we know how to do that? Not really. Empirical studies favor the simplest measurement of program complexity: code size. So that part is roughly taken care of. But I don't know of a good definition of "system". What counts as a single system and what counts as separate interacting systems, or subsystems? It's in the eye of the beholder. If I take 90% of a program and call it a library, has my program become 1/10 as complex?Rich says his definition of simplicity is objective, but it's not. What determines whether a construct has a single purpose? It's whether or not, on inspection, you think it does. S-expressions seem to me to have a single purpose: to group things. How those groups of things are treated by the evaluator is a separate concern. You, following Rich, say no, they have 3 purposes. Ok. Why not 4? A function call and a macro call have different purposes; why conflate those? (I have no trouble reading function calls in s-expressions, but sometimes run into trouble not knowing that they are really macro calls, so this is not a made-up point.)
We have no objective basis for this type of discussion, only emotions and beliefs. Concepts like "readability" are hopelessly relative, but appeals to "ease of future change" are no better; to put it politely, they depend on individual perspective and experience; to put it bluntly, we imagine them.
⬐ chousukeI don't agree with your assessment that adding things necessarily increases complexity. Assuming these things are simple (in the objective sense as defined by Rich), actually suitable for the problem, and used correctly, then any complexity arising from their use is necessary to solve the problem, and can't be avoided.The definition of a system in this case is anything with one or more components that accomplishes a particular purpose.
It still seems you're using a different definition of complexity than I am. To me, complexity implies unnecessarily intertwined elements.
In your hypothetical library situation, the answer is likely no. Your program still depends on the "library" code in ways that make the two not treatable as standalone entities, so no complexity has been removed.
An inherently complex tool may solve the specific problem it's built for, but it does not combine well with other tools. A simple tool tries to keep itself standalone so that can be freely combined with other simple tools to provide functionality that the original authors of either tool might not have envisioned. Clojure has many examples of this idea in action, but it's not the only language to exhibit simplicity.
I think Rich's definition of simple is straightforward and objective. For example, Clojure protocols fit the definition. They give you freely extensible polymorphism based on object types. Protocols don't even provide a direct way to do inheritance. That can be done by using a map of functions that you modify as needed, but requires no explicit support.
Your defense of s-expressions is rather puzzling. The evaluator defines what s-expressions (lists) mean in CL, and depending on context, there are multiple meanings that are completely separate. Certainly you can argue that Clojure conflates macro and function calls too (it is justified to me though, since they're all operators), but it has at least reduced complexity by not conflating binding and grouping with those elements.
As an added benefit, with few exceptions, whenever you see a list form in Clojure you can assume it's either a function call or a macro of some sort.
Rich is a good philosopher. Although it's often hard to strictly follow your own principles in your real-life work - and Clojure shows that often ;)⬐ typicalruntSlightly OT: What's the name of the template used in his presentation? It's beautiful and has a nice contrast of colours.⬐ puredanger⬐ nebanebaThat's a stock Keynote theme called Industrial.At 55:20 he says, if you have A calling B all the time, you should "Stick a queue in there."What is an example of this?
⬐ automagical⬐ Sikulhes talking events i guess, instead of A saying "B do this" it just pushes "i want this done" in a queue. and someone else, may be B, could dequeue and get it done. this decouples A and B.⬐ chousukeI suppose he means that instead of A calling B directly, A should put work in a queue and B should consume from it, thus decoupling the two entities.Can anyone explain how pattern matching causes complexity?⬐ mnicky⬐ ShardPhoenixsee http://www.reddit.com/r/programming/comments/lirke/simple_ma...Good talk - reminds me of Yegge's recent rant about the Service Oriented Architecture, but coming from another angle (internal use vs. external).⬐ malkiaI wonder what would Rich think of automake, autoconf and cousins? is it simple, is it easy, or simply esoteric?It confuses the hell out of me :)
⬐ NoneNone⬐ NoneNone⬐ jsmcgdFor me this was the best talk I've seen in a long while. It reminded me of how I felt when I first read PG's essays, someone articulating your own suspicions whilst going further and deeper and bringing you to a place of enlightenment and clarity.BTW for those of you who haven't watched it, this talk is not Clojure specific.
⬐ snprbob86All of Rich's talks are great: http://www.infoq.com/author/Rich-Hickey⬐ rjn945⬐ jcromartieI'd like to point out in particular "Are We There Yet?" (http://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hic...)If you liked this talk, then you will definitely like "Are We There Yet?" In it, Hickey argues that most popular object-oriented languages make similar mistakes by bundling identity, time and state into objects. He discusses how we might simplify programming by separating these components and rethinking each.
It has a similar theme but focuses on one concrete issue in depth. It has a similar philosophical style while remaining clear-headed and practical. And, in my opinion, it is similarly enlightening. If you couldn't tell by now, I recommend it :)
However it's a great advertisement for Clojure, since the set of things he highlights as enabling simplicity is pretty much a subset of Clojure (or included libraries, like core.logic).I'd be interested in seeing someone present a different and convincing set of concepts. At this point, I think Rich has put together a very good toolset.
⬐ shooverAnother way to look at it is Clojure is a reification of his thoughts on simplicity.⬐ brianmWell, yes, IIRC he described one of his major goals with Clojure as enabling simplicity, or something like that. That Clojure's design follows his views on simplicity seems natural.Non-Clojure examples would help make the point. He does bring up examples from Haskell (such as type classes) in the talk in places, but doesn't dive deeply into them.
⬐ loumfSQL and Prolog were also cited, but yes, nothing very deep (which I think is fine for this talk)I would love to see the programs that are generated from this philosophy.
⬐ KafkaIf I'm not mistaken he also mentions LINQ wich is a wonderful extensions of C# and the .NET Framework. It feels like LINQ and Clojure could be a interesting match.⬐ bitopsYour comment made me take heart if I understand it correctly. Sometimes I feel I'm the only person out there who thinks SQL has a certain beauty and elegance.I find it a little funny sometimes to hear all these "web scale" folks put down SQL, and then praise something like MongoDB because you can do map/reduce.
I saw a presentation by the author of the Lift framework in Scala and he made a bit of a joke saying "gosh...all this FP stuff...the folks who created SQL heard about that a long time ago".
⬐ ZakI think the relational model has beauty and elegance, but not the SQL language itself. They are not one and the same.On the subject of SQL and Clojure, ClojureQL provides an alternate relational data manipulation language that compiles to SQL. It's not just a different syntax; it allows some composability not found in SQL. The syntax does help though, especially in conjunction with the thrush operator.
⬐ fogusYou're not alone. :-)the only person out there who thinks SQL has a certain beauty and elegance