Hacker News Comments on
Structure and Interpretation of Computer Programs - 2nd Edition (MIT Electrical Engineering and Computer Science)
·
2
HN points
·
20
HN comments
- This course is unranked · view top recommended courses
Hacker News Stories and Comments
All the comments and stories posted to Hacker News that reference this book.* How to Code: Simple Data and How to Code: Complex Data on edX. Taught by Gregor Kiczales, of Common Lisp and CLOS fame. Uses Racket and graphical programs to teach.https://www.edx.org/course/how-to-code-simple-data
https://www.edx.org/course/how-to-code-complex-data
* The From Nand to Teris project, The Elements of Computing Systems: Building a Modern Computer from First Principles book, and/or Coursera course. Builds a hardware stack for a CPU and then a software stack (assembler, VM, high-level language).
https://www.coursera.org/learn/build-a-computer
https://www.coursera.org/learn/nand2tetris2
https://www.amazon.com/Elements-Computing-Systems-second-Pri...
* The How to Design Programs book. What the edX course above is based upon.
https://www.amazon.com/How-Design-Programs-Introduction-Prog...
* Structure and Interpretation of Computer Programs (SICP). Uses Scheme. One can use Racket with the `#lang sicp` language.
https://mitpress.mit.edu/sites/default/files/sicp/index.html
https://www.amazon.com/Structure-Interpretation-Computer-Pro...
YouTube playlist of the course by the authors: https://youtube.com/playlist?list=PLE18841CABEA24090
* Thinking as Computation: A First Course. Uses Prolog to solve problems of thinking.
https://www.amazon.com/Thinking-Computation-First-Course-Pre...
https://www.cs.toronto.edu/~hector/PublicTCSlides.pdf
* Turtle Geometry: The Computer as a Medium for Exploring Mathematics (shares an author with SICP). Uses Logo to explore turtle geometry/graphics. Can use any modern Logo implementation.
https://www.amazon.com/Turtle-Geometry-Mathematics-Artificia...
https://direct.mit.edu/books/book/4663/Turtle-GeometryThe-Co...
* Starting Forth. Uses Forth.
https://www.forth.com/starting-forth/
https://www.amazon.com/Starting-Forth-Leo-Brodie-ebook/dp/B0...
* Learning Processing: A Beginner's Guide to Programming Images, Animation, and Interaction and also The Nature of Code: Simulating Natural Systems with Processing. Uses Processing and p5.js (the JavaScript version of Processing).
http://learningprocessing.com/
https://www.amazon.com/Learning-Processing-Beginners-Program...
https://www.amazon.com/Nature-Code-Simulating-Natural-Proces...
The author's YouTube channel: https://youtube.com/c/TheCodingTrain
You should not approach problems in functional languages with imperative techniques. It's fitting a square peg in a round hole. The approaches & data structures aren't always the same.In my experience with FP you start with more of a top down approach in contrast to the bottom up approach discussed in the blog post.
There are many good resources on this. I've referenced a few below. Of course there are many more.
[1] https://www.amazon.com/Pearls-Functional-Algorithm-Design-Ri...
[2] https://www.amazon.com/Purely-Functional-Data-Structures-Oka...
[3] https://www.amazon.com/Algorithm-Design-Haskell-Richard-Bird...
[4] https://www.amazon.com/Structure-Interpretation-Computer-Pro...
⬐ rramadassI think anybody who wants to understand Functional Programming should start with Lambda Calculus.I highly recommend An Introduction to Functional Programming Through Lambda Calculus by Greg Michaelson.
You can then see how to express Functional Techniques in your language of choice (i.e. one you already know well eg; Functional Programming in C++ by Ivan Cukic) before learning a new Functional Language. This is to avoid the confusion in syntax/semantic expression of unfamiliar concepts which is a bit too much for a beginning student to handle simultaneously.
⬐ exdsqThanks for these links, commenting to find them later.⬐ Jtsummers⬐ dehrmannIf you select the timestamp of a comment (also when you reply to it) you can favorite it. This is much cleaner than leaving scattered "to find them later" comments around this site (in fact, I'm pretty sure it was added precisely to avoid those kinds of comments). You can also favorite submissions themselves. Favorites can be found in your profile.⬐ exdsqCool, didn’t know that! Cheers⬐ bckryou can click the timestamp and just keep the URL somewhere, like your browser's bookmarks> You should not approach problems in functional languages with imperative techniques. It's fitting a square peg in a round hole.This might be part of the problem with FP. Every popular CPU architecture is imperative.
⬐ chriswarboI find this unconvincing. Electronic circuits are well described as a Cartesian Closed Category; and hence by lambda calculus (i.e. we can give semantics to functional programs by interpreting them as descriptions of circuits; as opposed to the "usual" interpretations of x86_64 machine code, or symbolic values, etc.)Imperative systems are "fitting a square peg in a round hole" by introducing hacks like 'clock signals', 'pipeline flushes', etc.
⬐ hither_shores⬐ imtringuedThe category with linear circuits as its morphisms, labelled sets of electronic terminals as its objects, and laying circuits in parallel as the monoidal product (which is the usual notion of the category of circuits; perhaps you have something more sophisticated in mind, but if so you should specify that) is not cartesian closed.One of the many ways to demonstrate this: all linear circuits have duals (voltage <-> current, series <-> parallel, and so on), but in a cartesian closed category only the terminal object is dualizable.
What you're probably thinking of is the fact that this category is compact closed. The corresponding internal language is going to be some sort of process calculus (I think the pi calculus is too strong, but not sure), not the lambda calculus.
No, that's the easy part. Computation with FP is very easy. The problems start the moment you have to do persistence and communication. Those aren't part of any pure functional paradigm.⬐ TuringTest> Every popular CPU architecture is imperative.That's arguable, given that every (deterministic) imperative computation can be expressed as a pure functional program. "Imperative" is more of a viewpoint that the developer is using to understand the behavior of the computer, rather than a property of the machine itself.
A pure functional analysis will describe a computation on that "imperative" architecture as an inmutable, monotonic sequence of all the states that the CPU goes through over time; or maybe, if you know enough PL theory, as a chain of rewritings of a program-long expression that is updated, one term at a time, when each expression is replaced by the result of a function as it consumes its input parameters.
And no viewpoint is inherently better than the other (except that the functional version can be analyzed in a natural way with mathematical tools, which is often difficult with the imperative description).
⬐ whimsicalism⬐ nightskiNot really arguable, IMO.Just because both lambda calculus and assembly are Turing complete does not mean that CPU architecture isn't clearly imperative.
⬐ TuringTest⬐ dahfizzHow do you define "imperative" in a way that precludes a functional description of your definition? I'd say that if you're able to do that, you'd have found a contradiction in Turing completeness and win you a Turing award.Also, this: https://news.ycombinator.com/item?id=30883863
⬐ whimsicalismJust because every program in C is also expressable in Haskell does not mean that C is Haskell or that C is a functional programming language.The same is true of CPUs, which at their base level execute instructions line-by-line to move and load things in and out of stateful registers as well as doing simple mathematics.
Not going to keep arguing, as I can see from your other comments that you are going to try to hold this line, and also your reasoning doesn't really make sense.
Everyone has heard of Turing completeness. It does not imply that all distinctions between the semantics of languages and the structure of hardware thus are collapsed. It means that you can write an equivalent program using different semantics or different hardware.
⬐ TuringTest> It does not imply that all distinctions between the semantics of languages and the structure of hardware thus are collapsed. It means that you can write an equivalent program using different semantics or different hardware.No, it means that every computable program or device can be described through functional semantics, and therefore that very same program running on that same hardware can be described mathematically with them (not an 'equivalent' program, but the same program with the same runtime behaviour, just described in low level with a different format).
That's a core principle of computer science that predates computers themselves, and people arguing about the benefits of the imperative style tend to be unaware of this fact, making their arguments look weak.
You're definitely stretching here. I could just as easily argue that "all of main memory" is the output of any function. Therefore every function is a pure function, and C is a function language. Using your definition, the concept of functional programming is meaningless.Main memory is state. Registers and cache are state. The entire purpose of the CPU is to mutate state.
⬐ nightski⬐ kortexNo, I don't believe you could argue C is purely functional by framing memory as the output of the function because C doesn't treat it as such. Memory in C can be changed even if it is not listed in the inputs or outputs of the function.He's not really stretching the definition, that's just the lens through which FP looks at the world.
Of course there is state. FP doesn't prohibit state, it just makes it explicit and referentially transparent. But this is in the semantics, not the execution model of the program.
⬐ dahfizz> Memory in C can be changed even if it is not listed in the inputs or outputs of the function.If we are going to nitpick syntax, nothing about `mov eax ebx` lists main memory as output. In fact, mov doesn't even have an 'output'.
If you want to model mov as a function with the implicit output of "all of main memory", then you can do the same with any arbitrary C function. If you can't make that leap for C, then you can't make that leap for assembly.
⬐ nightskiIt's not syntax, it is semantics. There is a lot to programming language theory/design and this is all formalized. C does not have the semantics you are describing in the formal specifications (C99, etc..). Could they have developed a version of C with these semantics? Possibly. Rust was a step in that direction with it's borrow checker.⬐ dahfizzYes, and my whole point is that assembly does not have those semantics either. The computer is an imperative machine.⬐ TuringTestThe computer is not an imperative machine. It's a physical machine that you describe with an imperative representation in your mind. Can you tell the difference, or are you unaware of the map-territory distinction going on?Functional programmers are simply choosing to use a different style of map, but we both represent the same reality.
⬐ dehrmannAccording to Wikipedia, "the hardware implementation of almost all computers is imperative."⬐ TuringTest[Citation needed]Nope, unless you do some serious contortions and basically say that the universe is a lambda calculus that operates on each moment in time to produce a new view of reality.Computers that do anything useful have all manner of I/O. Highly oversimplified in modern architecture, but you can think of I/O as a bunch of memory cells that are DMA'd by external forces. Literally the exact opposite of functional, IO registers are the epitome of global mutable state. Then you have interrupts and the CPU operates in response to these events.
The viewpoint of "computers are mutable state" is inherently better because of parsimony - it requires less degrees of indirection to explain what is happening. Just because you could shoehorn reality into a physical model, does not make it equally valid. You basically need to break it down to the Schrodinger equation level to have a purely functional model when even idealized gates are involved because propagation delay impacts things like how fast you can DMA.
⬐ TuringTest> Just because you could shoehorn reality into a physical model, does not make it equally valid.Hey, physicists do it all the time. Having mathematical representations of how things work in the real world often turn out to give you complex devices that you wouldn't get by intuition alone. Thanks to doing it, we have Special Relativity and Schrodinger equations, that bring you advantages as GPS and insanely-high-speed networks.
There's nothing wrong with modelling interrupts and mutable state as static mathematical entities a.k.a. functions; and if you think it is, you don't know enough about functional programming - in fact, doing it allows for advanced tactics like automatic verification and very high scale generation of electronic devices.
Those less degrees of indirection may make it simple to build some kinds of programs; but they also introduce complexity in modelling the possible states of the system when you allow for arbitrary, unchecked side effects. So no, that representation is not inherently better - only most suited for some tasks than others; but the converse is also true for functional models of computation. If you think it is always better, it's because you're not taking all possible scenarios and utilities into account.
(Besides, as I already said elsewhere, "computers are mutable state" is not incompatible with functional representation; as mutable state can be represented with it). It seems that you're confusing mutable, wich is a property of computational devices, with 'imperative' which is a style of writing source code and defining relations between statements in your written program.
> Literally the exact opposite of functional, IO registers are the epitome of global mutable state.
Yup, you definitively don't know what functional programming is if you think you can't have global mutable state in it. In fact, every top-level Haskell program is defined as a global mutable IO monad...
I was more talking about how you approach solving problems, not the execution model. You can still get tight imperative loops in FP, it's just approached differently than in a traditionally imperative language.Everything is a tradeoff. FP gives you a lot of flexibility in how you trade space and time of the execution of your program. It's also not a magic wand, just a really powerful tool.
"Will Change The Way You Think About Computing."> Have you read SICP? https://www.amazon.com/Structure-Interpretation-Computer-Pro...
Probably not able to completed during a single 3 months unless you do it full time, but I picked up a copy of SICP [0] and started reading through and working through every-single-problem. I got stuck so far on one problem in the first chapter toward the end at the moment. I will say, Scheme is fun! The problems can be challenging, short, and very rewarding.However, maybe I'm not very smart and feel like I might have a very hard time with it. I'm not that great at math I don't think, nor do I consider myself genius like. Did people who go through this book do every single problem and figure it out themselves? There are a lot more problems then I expected. They are also, so far, some to be quite challenging and math heavy. It does really feel like it helps get my brain thinking differently about a lot of problems and I love it! But it also feels like I might start grinding a lot and burn out on it. Any tips or help or suggestions how to get through it successfully, get a good amount of education out of, and continue to be excited to keep moving forward?
[0] https://www.amazon.com/dp/0262510871
I know it's free online, but I wanted a physical edition.
If you've never met Scheme, then SICP [0, 1, 2] may be something that can change the way you program. It certainly made me better, or at least a deeper understanding.[0] https://www.youtube.com/watch?v=2Op3QLzMgSY&list=PLE18841CAB...
[1] https://www.amazon.com/Structure-Interpretation-Computer-Pro...
I can't recommend courses, because I don't have direct experience of any, but given what you say, my suggestion would be to take a bit of a pause from pragmatic problems, and dedicate some time to learn the foundations of computer science, in particular about algorithms and data structures. I'd recommend a couple of books: "The Algorithm Design Manual" by Steven Skiena if you want something not too theoretical, or "Introduction to Algorithms" by Cormen, Leiserson, Rivest, if you want a bit more breadth and theory:https://www.amazon.com/Algorithm-Design-Manual-Steven-Skiena...
https://www.amazon.com/Introduction-Algorithms-3rd-MIT-Press...
As a second suggestion, I'd recommend to learn a language somewhat different from JavaScript-like (or C-like) languages, something that challenges your mind to think a little differently and understand and create higher order abstractions. There are many choices, but to avoid confusion and being my favourite, I'll point to one: read the "Structure and Interpretation of Computer Programs" by Abelson and Sussman. It teaches Scheme in a gentle and inspiring way but at the same time it teaches how to become a better programmer:
https://mitpress.mit.edu/sicp/
Or if you want made of dead trees:
https://www.amazon.com/Structure-Interpretation-Computer-Pro...
I can't recommend it enough. If you read it, do the exercises, don't limit to read through them.
Maybe it's even better if you start with this, and THEN read the books on algorithms and data structures.
Enjoy your journey!
⬐ SnowingXIVSICP has continually showed up on my radar and before this post it's what I was looking at getting into again but felt this the book might have been too "meaty" and maybe was out of vogue. I think I just need to delve into it and finish it. Awhile back I did the first couple chapters and it did seem to go quite well though it's not for the faint of heart and really requires hard focus and I'm okay with that! My hesitation was that I wasn't sure if it was a solid starting point. Looks like it might be!⬐ pantaIt could have a bit of a "serious air", but don't let this intimidate you, it's not that academic. Also you don't need to read it all to grasp the most prominent benefits. Chapter 2 and 3 have a lot of juice (I remember in particular the part on generic operations and the symbolic algebra example in ch. 2 and the streams in ch. 3). If you decide to read it all, in the end you'll learn how to write an interpreter for the scheme language, and this will ingrain a very deep understanding on how an interpreter (and even a compiler to a degree) works. But as I said, write the code yourself while you read the book. It will be easier to follow and much more fun!
I learned programming without a computer in the 90s with Kernigan & Ritchie "C Programming Language", one of the best coding books ever written:https://www.amazon.com/Programming-Language-Brian-W-Kernigha...
I'd also learn SICP: https://www.amazon.com/Structure-Interpretation-Computer-Pro...
and algorithms from either CLRS https://www.amazon.com/Introduction-Algorithms-3rd-MIT-Press... or Skiena Algorithm Design https://www.amazon.com/Algorithm-Design-Manual-Steven-Skiena...
⬐ corysamaAlong with SICP, The Little Schemer would be a great book to work through on paper. https://mitpress.mit.edu/books/little-schemerOnce that is worked through, Godel, Escher, Bach would be an especially entertaining and enlightening read.
⬐ znpyScroll down to the "Customer Review" section ;)
I'm a programmer without a computer science degree and I'm quite aware that CS is a bit of a blind spot for me so I've tried to read up to rectify this a little.I found The New Turing Omnibus[1] to give a really nice overview of a bunch of topics, some chapters were a lot harder to follow than others but I got a lot from it.
Code by Charles Petzold[2] is a book I recommend to anyone who stays still long enough; it's a brilliant explanation of how computers work.
Structure and Interpretation of Computer Programs (SICP)[3] comes up all the time when this kind of question is asked and for good reason; it's definitely my favourite CS/programming book, and it's available for free online[4].
I'm still a long way off having the kind of education someone with a CS degree would have but those are my recommendations. I'd love to hear the views of someone more knowledgable.
[1] https://www.amazon.co.uk/New-Turing-Omnibus-K-Dewdney/dp/080... [2] https://www.amazon.co.uk/Code-Language-Computer-Hardware/dp/... [3] https://www.amazon.co.uk/Structure-Interpretation-Computer-E... [4] https://mitpress.mit.edu/sicp/full-text/book/book.html
Friends of mine used "Create Your Own Programming Language" to get started learning about interpreters: http://createyourproglang.comI personally learned with SICP (But reading this book isn't just about interpreter, it will make you a better programmer and blow your mind in so many different ways. I wouldn't say it's for experts only, but this isn't the kind of book that beginners would get excited about. However, if someone is serious about improving as a developer, I can't think of a better book): http://www.amazon.com/Structure-Interpretation-Computer-Prog...
Finally, (How to Write a (Lisp) Interpreter (in Python)) by norvig is a great read if you're getting started with interpreter: http://norvig.com/lispy.html
* The reason the two last links are lisp related is because writing interpreter in Lisp is really straightforward (Since the code is the AST). Similarly, if you wanted to learn about memory management, a language like assembler or C might be more suited than say Python.
I have a system, where I read the most negative reviews of the book. If the reviews are eloquent and make a solid point, I don't buy the book.If the negative reviews are mostly whiny,emotional rants without any valid solid arguments, then the book is most definitely worth it. A case in point:
http://www.amazon.com/Structure-Interpretation-Computer-Prog...
⬐ radmuzom(Off-topic) The top rated review of this book is from Peter Norvig. He states "For most books, the review is a bell-shaped curve of star ratings". However, as a habitual window-shopper of books in Amazon, I have rarely come across rating distributions which look like normal. In my experience, 2 and 3 ratings are much less common than 5, 4 or 1.⬐ kidnoodle⬐ maratdI have a blog post I've never quite finished writing, walking through some analysis of the 34,686,770 Amazon reviews in the Stanford SNAP dataset (https://snap.stanford.edu/data/web-Amazon.html, but there's a newer and better one at http://jmcauley.ucsd.edu/data/amazon/).Somewhat surprisingly, the median review score is 5, and if you look at median scores for products, the skew is very much left. So, the data pretty much backs up your observation!
⬐ radmuzomThank you for the links. And very timely - was looking for datasets to run some analytical and visualization experiments.> I have a system, where I read the most negative reviews of the book. If the reviews are eloquent and make a solid point, I don't buy the book.This works surprisingly well for any product on Amazon.
⬐ runevaultHuh didn't realize others do the same thing. I thought up this same method 7-8 years ago and I don't think it has ever steered me wrong. I may not always appreciate the book, but I can tell it is simply something that doesn't work FOR ME, which is always hard to gauge before you actually read something.⬐ jevgeni⬐ scott_sIt started off as a cautionary thing for me, when I had to buy (optional) text books and didn't want to blow my money on something bad, so I started paying way more attention to the negative reviews.I do that, but as a source of entertainment. The one star reviews for works (books, comics, movies) that I think are masterpieces generally come from a perspective that I have difficulty wrapping my head around.⬐ simonebrunozziYours sounds a great approach. I've tried many, and I always look at negative reviews, however I should weigh them more.⬐ ctdonathI'll second that method. Positive reviews are uninteresting; 1-star reviews reveal whether there really is a problem/deficiency, as usually the complaint is unrelated ("product arrived damaged"), misguided (expectations were bafflingly far from what product is, "this washcloth is a lousy database manager"), or a fluke (50,000 5-star reviews and one "one page was folded, replacement was fast & free").⬐ walterbellWorks for Yelp reviews too, after disabling "Yelp Sort".⬐ conanbattI directly read 2 star reviews. 1 star reviews are often super biased and pissed. Much like in yelp, it contains things like "The shoes didnt fit" , "The delivery guy was mean" and stuff like that.
Amazons URL's are actually quite interesting -It appears so long as 'dp/0262510871' is in the url (without dp/# appearing before it, but a second one after is fine) it works.Original: http://www.amazon.com/Structure-Interpretation-Computer-Programs-Engineering/dp/0262510871/ Equivalent: http://www.amazon.com/dp/0262510871 http://www.amazon.com/dp/0262510871/something-else http://www.amazon.com/something/dp/0262510871 http://www.amazon.com/something/dp/0262510871/something-else
⬐ cpetersoOr simply http://amzn.com/0262510871⬐ rawdiskHTTP/1.1 301 Moved PermanentlyThis is a URL shortener that just redirects to the full URL that has same number. Easier to type but otherwise acomplishes nothing. Server with the content still needs full URL. All this shorter URL gets you is the full URL.
It is actively harmful to teach students that software architecture is something that somehow arises from diagrams or that those kinds of silly pictures capture anything important about it. Powerful architectures come out of powerful ideas that in turn come from accumulated hard work of many people in different disciplines. One can learn much more from walking through the actual source code of some classic projects and from trying to understand the ideas that make them tick:https://github.com/onetrueawk/awk - UNIX philosophy of small tools, DSLs, CS theory: state machines / regular expressions, Thompson algorithm ...
https://github.com/mirrors/emacs - Both a program and a VM for a programming language, hooks, before/after/around advices, modes, asynchronous processing with callbacks, ... Worth to think of challenges of designing interactive programs for extensibility.
https://github.com/rails/rails - Metaprogramming DSLs for creating powerful libraries, again a lesson in hooks (before_save etc.), advices (around_filter etc.), ...
https://github.com/git/git - The distributed paradigm, lots of CS theory again: hashing for ensuring consistency, DAGs everywhere, ... By the way, the sentence "yet the underlying git magic sometimes resulted in frustration with the students" is hilarious in the context of a "software architecture" course.
One of computer algebra systems - the idea of a http://en.wikipedia.org/wiki/Canonical_form
One of computer graphics engines - Linear algebra
...
There are loads of things one can learn from those projects by studying the source in some depth, but I can't think of any valuable things one could learn by just drawing pictures of the modules and connecting them with arrows. There are also several great books that explore real software design issues and not that kind of pretentious BS, they all come from acknowledged all-time master software "architects", yet all of them almost never find diagrams or "viewpoints" useful for saying the things they want to say, and they all walk you through real issues in real programs:
http://www.amazon.com/Programming-Addison-Wesley-Professiona...
http://www.amazon.com/Paradigms-Artificial-Intelligence-Prog...
http://www.amazon.com/Structure-Interpretation-Computer-Prog...
http://www.amazon.com/Unix-Programming-Environment-Prentice-...
http://www.amazon.com/Programming-Environment-Addison-Wesley...
To me, the kind of approach pictured in the post, seems like copying methods from electrical or civil engineering to appear more "serious", without giving due consideration to whether they really are helpful for anything for real-world software engineering or not. The "software engineering" class which taught those kind of diagram-drawing was about the only university class I did not ever get any use from, in fact I had enough industry experience by the point I took it that it just looked silly.
⬐ synctextActively harmful? Diagrams?Sorry I have to counter-react strongly. Your post is negative without a valid point and the irony is that you agree with the post.
> One can learn much more from walking through the actual source code of some classic projects and from trying to understand what makes them tick
That is the fun part about this post! You propose to mandidate a list of classical code bases. This course lets students freely pick any Github project with activity and complexity. They get graded based on pull requests.. Contributing code and interacting with an Open Source project you picked a week ago is not "drawing pictures" and "connecting them with arrows".
⬐ stiff⬐ avandeursenPrograms are powerful because of concepts. Whether or not you will be able to build a good 3d engine rests much more on the fact whether you know or able to invent a concept of a vector and have it guide all your future coding than it rests on whatever is visible from a block diagram. Both the course and the book linked to seem to focus on some abstract ideas of doubtful usefulness and never ever seem to touch upon those important things that historically have allowed us to build complex programs where other approaches have failed. Google can exist not because people invented new kinds of diagrams, but because large scale numerical linear algebra techniques were applied to the problem of search. This is the heart of Google's "architecture", not a class diagram of the crawler.Picking arbitrary programs won't do. The point is to pick the really good designs and illustrate why they are good, and I think it boils down much more to knowing mathematics, algorithms, programming languages and having studied a lot of existing software, than to usage of any modelling techniques so far invented in formal software engineering circles.
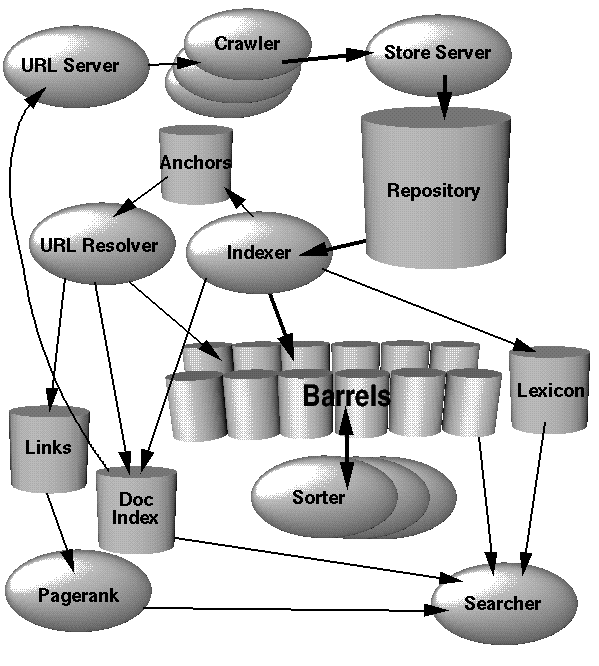
⬐ brosephThere's no conflict between reading and understanding a codebase and seeing the value in a diagram. You can have both. Take a look at the example you chose: [0] and [1] (about a third of the way down).They first explained PageRank (without a diagram), then explained the flow of the data from the crawler (with a diagram). You seem to be arguing that diagrams are never useful, and that just isn't true.
[0] http://infolab.stanford.edu/~backrub/google.html [1] http://infolab.stanford.edu/~backrub/over.gif
Here's an addition to the answers from the others -- I'm one of the authors of the post.Thanks for your feedback.
Perhaps we did not sufficiently emphasize it in the blog post, but we do tell the students about strong existing architectures, open source as well as from industry. The books listed in further reading in the post actually contain chapters about git and emacs, and I share your enthusiasm for Bentley's little language approach.
The philosophy of the course is based on trying to apply published approaches to software architecture (such as those in Rozanski & Woods' book, but it could be others) to real systems actually maintained and used. We encourage to get in touch with the creators of those systems.
The students actually take a deep dive into a foreign code base -- I included pictures because that is easy to share in a post, but the students analyze code, report about that, execute test cases, deploy systems, etc. The pictures are indeed, as suggested by some of the others, means for communication.
⬐ stiff⬐ porkerWhat repels me is the kind of approach taken by this Rozanski & Woods book. It's like a 500 pages of authors philosophy of software, and whether all that is of any use is completely uncertain. There is not much of a widely established corpus of knowledge on software engineering/architecture, another book would treat an almost completely different set of concepts, and whatever is commonly agreed upon is trivial and most people invent in on their own when they need it. You can publish completely anything about "Software architecture" in this spirit thats sounds smart enough and it won't ever be put to any test. I personally, from experience, don't believe any practical high-level theory of software engineering of this kind exists at all, the more "philosophical" or "theoretical" it gets the less useful it becomes. It is much better to spend this time studying established disciplines where things actually get tested out one way or another, mathematics, algorithms, operating systems, ... If there is anything specific to be taught under "software architecture", it's those ideas ("patterns") that made certain programs so much better than the alternatives, but you only really learn them by digging deep in, not by studying some very abstract models.⬐ hansbogertFrom your post it seems you think software architecture and -engineering are the same.. In this course -- disclaimer: I was a student taking this course -- it's not that case, Software Architecture is not the sum of a program's lines or modules. SA is the methodology of getting involved and steering a project, this includes handling team efforts and other stakeholders. Looking and learning a lot of (implementation) patterns is of course very useful, but only a subpart of SA.I tend to think that a good SArchitect knows that the patterns they might be using are good or well suited for the current problem, a better SArchitect knows that he's perhaps using a less well suited pattern for the problem, but can layout a plan to migrate to a new and better situation without breaking continuity of the project.
Furthermore, it can't be stated clearer that in the course there are a lot of guest lecturers who _do_ show different idea's.
In addition to what the other respondents have written, could it be that you are not a visual learner, and diagrams don't 'do it' for you?⬐ currywurstThe pictures are a result of studying the systems in question.For example, you have given links to a couple of github repos. Now if I'm trying to create an overview of how say emacs works, I would try to identify the main sub-parts and break the system down into more manageable chunks of study. This is all what 'viewpoints' are trying to structure. None of this is evident from just the codebase unless it has been captured in some documentation, or you take the trouble to understand it yourself.
You seem to have a very low opinion of software architects, but believe me, you wouldn't want to work on a 5-year old system where huge teams of developers have let loose and no one/team was responsible to ensure a cohesive, maintainable system.
Viewpoints are fantastic for communication purposes, and if you feel that the particular viewpoints shown don't make much of a difference, I agree :). A student project is also not the ideal environment, but it is really valuable to know how to create them, considering the information needs of the audience (biz vs tech vs in-depth tech). And that is what this course is all about.
⬐ stiffThe point is that how emacs is broken down in modules is one of the least important things about emacs. I can draw a block diagram without a "software architecture" course, thank you. In software engineering, there are of minor usefulness most of the time, if of any.There have to be persons that guide the overall development, sure, but this does not mean that those have to be "architects" living in a castle somewhere drawing those diagrams. The best "architects" are people with long experience in the trenches that know all the ins and outs, all the relevant theory, know the domain, and supervise it down to the nitty-gritty details. Linus Torvalds is a software architect for Linux, he doesn't do much coding anymore, but he isn't busy drawing diagrams without understanding the code really well either, he just is the person with the widest understanding of the whole project:
⬐ currywurstThere are a LOT of practicing architects that really fit the mould you are describing! Linus has the big picture in his head, and perhaps if he were to draw them out, does it make him an ivory tower denizen ?!Also, ignoring how a system is modularized is typically how you get tangled codebases by introducing unexpected dependencies. Just because it is 'less interesting' doesn't make it 'unimportant'.
{kind=link}
Amaozn's got it for $46.55 (and it's eligible for Prime shipping) and MIT has it for $50; maybe I'm missing something?http://www.amazon.com/Structure-Interpretation-Computer-Prog...
⬐ taericOnly that my information is out of date. :) Last I looked they did not have this as an option. Well, they did, but look at the hardcover cost, and that is all I could find for a while.
Not sure if this is the right direction or not. In different ways they are all, essentially, about programming...http://www.amazon.com/Code-Language-Computer-Hardware-Softwa...
http://www.amazon.com/Elements-Computing-Systems-Building-Pr...
http://www.amazon.com/Structure-Interpretation-Computer-Prog...
http://www.amazon.com/G%C3%B6del-Escher-Bach-Eternal-Golden/...
http://www.amazon.com/Pragmatic-Programmer-Journeyman-Master...
Good luck!
⬐ dlfDitto on "Code." As a non-programmer learning to program, it was everything I needed to know to wrap my head around how everything actually works.⬐ syedkarimThis is absolutely the right direction--thanks! The one book on the list that might get kicked back is "Structure and Interpretation of Computer Programs". Too bad, since it's probably the most concrete. This is a great starting point, thanks again.
Gee, this reminds me of the time when I showed to a friend a stop motion clay animation I had painstakingly made. The man played it in fast forward. I didn't stay for his comments.Check out the reviews at amazon.com: both PG and some Peter Norvig give you permission to read it:
Or yes, you can choose to postpone the important for the urgent. But for your deity of choice's sake, don't multitask at this. Whenever you think you're ready, get a paper copy and set aside some time for it every day. Kiss the cover. Open the book. Read at least one subsection and do the exercises. Close the book and kiss the cover again. Candles optional.